Blind search algorithms (e.g. UCS) uses the cost from the root to the current node, g(n) to prioritise which nodes to search
Informed search algorithms rely on heuristics, h(n) that give an estimated cost from the current node to the goal to prioritise search.
In general, informed search is faster than blind search
However, it is more difficult to prove properties of informed search algorithms, as their performance highly depends on the heuristics used.
Informed Search: Select which node to expand based on a function of the estimated cost from the current node to the goal state
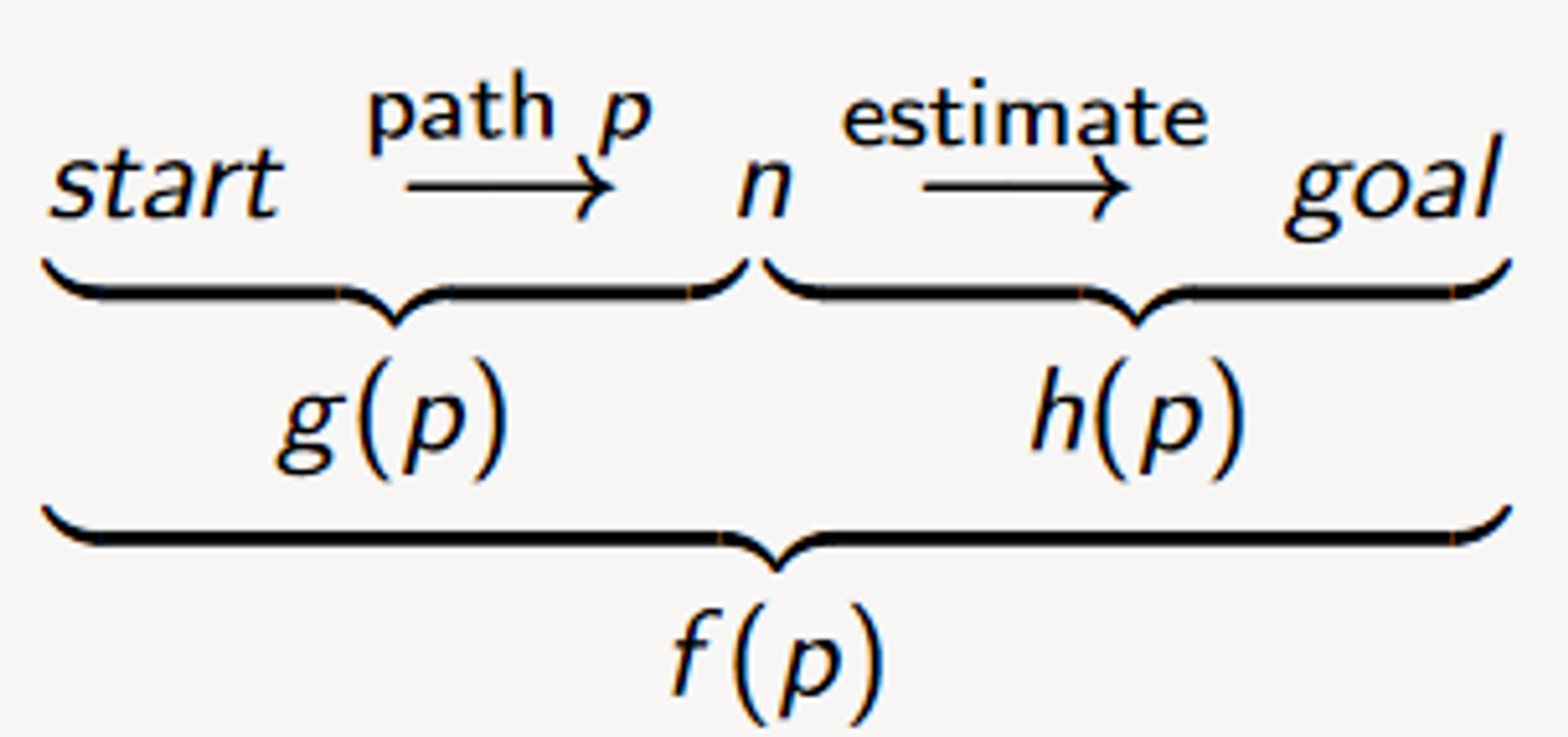
Cost f(n)=g(n)+h(n)
f(n) Function representing the total cost
g(n) Cost from root to node
h(n)Estimated cost from node n to goal (usually based on heuristics)
In informed search, the node is selected based on f(n), and f(n) must contain h(n)
Informed search algorithms include
Greedy best-first search
A* search
1.2 - Informed Search
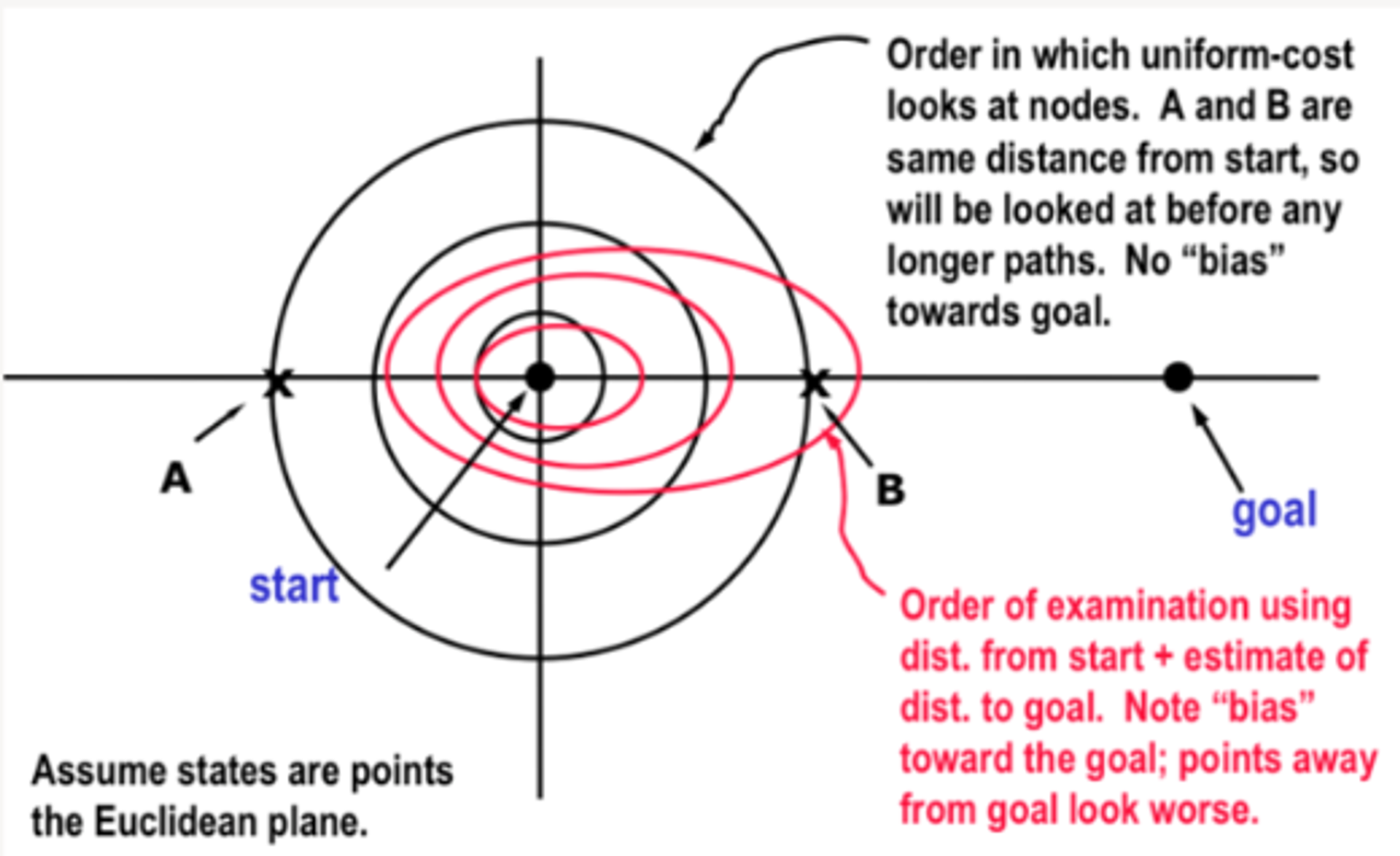
Node A and B are the same distance from the goal, but we can use our heuristic function to guide the search path toward the goal - prioritise node B over node A
Figure 1 - Informed Search
1.2.1 - Informed Search using Heuristics
Idea - Don't ignore the goal when selecting paths
Often there is extra knowledge that can be used to guide the search: heuristics
E.g. position of goal node
h(n) is an estimate of the cost of the shortest path from node n to a goal node
h(n) needs to be efficient to compute
might not save any time with respect to uninformed search heuristics if the heuristic is inefficient to compute
h can be extended to paths - h(n0,n1,...,nk)=h(nk)
h(n) is an underestimate if there is no path from n to a goal with a cost less than h(n)
An admissible heuristic is nonnegative (≥0) heuristic function that does not overestimate the actual cost of a path to a goal
1.3 - Example Heuristic Functions
If the nodes are points on a Euclidean plane and the cost is the distance, h(n) can be the straight-line distance from n to the closest goal (i.e. ignoring obstacles)
If the nodes are locations, and cost is time, we can use the distance to a goal divided by the maximum speed (underestimate)
If the goal is complicated, simple decision rules that return an approximate solution and that are easy to compute can make for good heuristics.
A heuristic function can be found by solving a simpler (less constrained) version of the problem.
1.4 - Heuristic Example
1.4.1 - Euclidean Distance / Bird Flight Distance
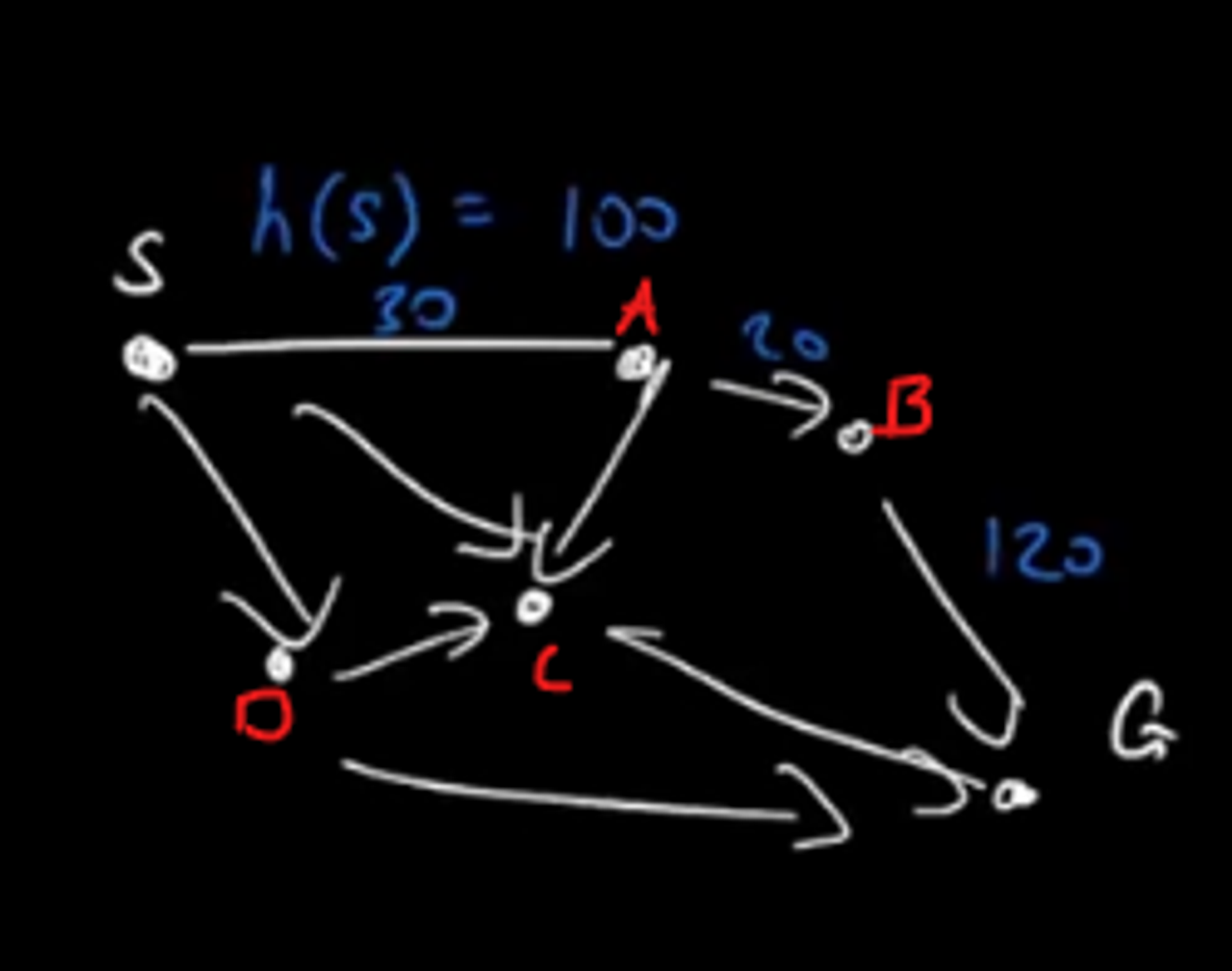
Figure 2 - Euclidean Distance
Given a graph, a heuristic h(n) is an estimate of the cost of the shortest path from node n to the goal node.
The estimate for travelling from node A to node G is 100, but the actual cost is 20+120=140
In a map-world we can use the Euclidean distance (bird's flight path) to estimate how far a node is from the goal.
Greedy Best-First search is almost the same as UCS, with some key differences:
Uses a priority queue to order expansion of fringe nodes
The highest priority in priority queue for greedy best-first search is the node with the smallest estimated cost from the current node to the goal
The estimated cost-to-goal is given by the heuristic function, h(n) [instead of g(n) in UCS)
If the list of paths on the frontier is [p1,p2,...]
p1 is selected to be expanded
Its successors are inserted into the priority queue
The highest-priority vertex is selected next (and it might be a newly expanded vertex)
Complete? Will Greedy Best-First search find a solution?
No (it depends on the heuristic) - cost of 0 → what do you search for?
Generate optimal solution? Is greedy best-first search guaranteed to find the lowest-cost path to the goal?
No (highly dependent on heuristic)
Complexity?
Depends highly on the heuristic
Worst case if the depth tree is finite: O(bm) where b is branching factor and m is maximum depth of the tree (i.e. it can be exponentially bad).
2.1 - Node Traversal Example
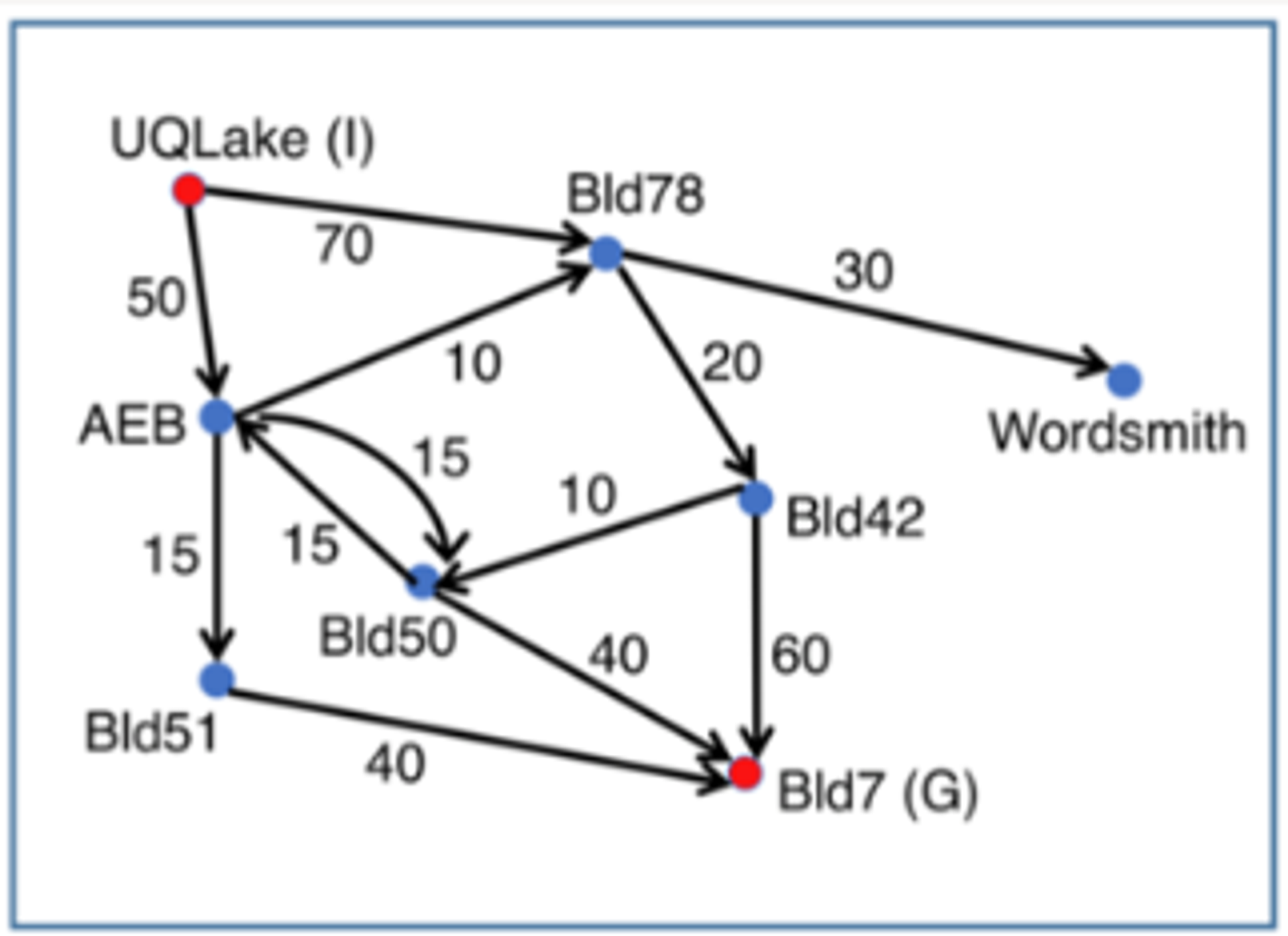
2.1.1 - Breadth-First Search on UQ Navigation Example
We start at UQ Lakes, and find its successors, AEB and BLD78 (and add them to the frontier)
Explore AEB which has successors Bld50, Bld51, and Bld78 (and add them to the frontier)
....
Figure 4 - UQ BFS Example
2.1.2 - Greedy Best-First Search Time & Space Complexity
At depth 1, there is 1 node to explore (UQLake)
At depth 2, there are b nodes to explore (Where b is the branching factor)
At depth 3, there are b2 nodes to explore
At depth d, there are bd nodes to explore.
...
In the worst case, there are bm nodes to explore
We can add all of these terms up using the formula for the sequence:
1+b+b2+b3+...+bd
If the branching factor is variable, we could take the worst-case branching factor or the average branching factor as the value of $b$ is really only used as an estimate.
2.1.3 - Greedy Best-First Search on UQ Navigation Example
Heuristic values (to Bld7)
h(UQLake)=100
h(Bld78)=50
h(AEB)=53
h(Wordsmith)=1000
h(Bld42)=50
h(Bld50)=38
h(Bld51)=30
h(Bld7)=0
(By default) start node added to the PQ
Expand the start node UQLakes
UQLakes has two successors, AEB and Bld78 so we add those to our Priority Queue container.
Get the costs
h(AEB)=53
h(Bld78)=50
Since Bld78 has the lowest cost, we explore that node first.
Bld78 has two successors, Bld42 and WS → Add these to the Priority Queue container.
Get the costs
h(Bld42)=50
h(WS)=1000
Since Bld42 has the lowest cost, we explore that node first
Bld42 has two successors, Bld50 and Bld7
Since Bld7 is the goal node, we have found a path from the start node to the goal node.
Actual cost = 70+20+60 = 150
This is not the optimal path
PQUQLakes
PQ~~UQLakes~~,AEB, Bld78
VisitedUQLakes
PQ~~UQLakes~~,AEB, ~~Bld78~~, Bld52, WS
VisitedUQLakes, Bld78
3.0 - A* Search
A∗ search uses both path cost and heuristic values
It is a mix of uniform-cost and best-first search
g(p) is the cost of path p from initial state to a node (UCS)
h(p) estimates the cost from the end of p to a goal (GBFS)
A∗ uses
f(p)=g(p)+h(p)
f(p) estimates the total path cost of going from a start node to a goal via p
This is still an estimate as
estimate+trueCost=estimate
We use paths instead of nodes for A∗ search as there are often multiple paths to get to a node.
3.1 - A* Search Algorithm
A∗ is a mix of uniform-cost search and best-first search
It treats the frontier as priority queue ordered by f(p)
The highest priority node is the node with the lowest f value - the function f(p) is the shortest path length from root node to the node (g(p)) plus the estimated future reward from node p to the goal (h(p))
It always selects the node on the frontier with the lowest estimated distance from the start to a goal node constrained to go via that node.