1.0 - Causes of Uncertainty: System Noise and Errors
Where does uncertainty come from?
Control error or disturbances from external forces → Effect of performing an action is non-deterministic
Errors in sensing and processing of sensing data → Imperfect observation about the world (partially observable systems)
Strategic uncertainty and interaction with other agents → Game Theory (Module 5)
Too complex to model
Lazy: Rolling a dice in a casino depends on the wind direction from air conditioning, number of people around the table, etc.
Deliberate: To reduce computational complexity. We want to eliminate variables that will not affect the solution significantly.
Accidental error → Lack of understanding about the problem
Abstraction error → The actual possible states are often too large. We simplify them so it's solvable by current computing power
One approach to simplification is to cluster several actual states together and assume all actual states in the same cluster are the same
Meaning: A state in our model corresponds to a set of actual states that are not differentiable by the program.
Similarly with the action space
Another approach is to use function approximations of the state or action policy, e.g. using basis functions or machine learning methods
In both, the effect of performing an action becomes non-deterministic
Usually we deal with bounded, quantifiable uncertainty.
2.0 - Assumptions on Environment in Module 3
Does the agent know the state of the world / itself exactly?
Fully observable vs partially observable
Does an action map to one state into a single other state?
Deterministic vs non-deterministic
Can the world change while the agent is "thinking"?
Static vs
Are the actions and percepts discrete?
Discrete vs continuous
3.0 - Review of Probability
3.1 - Applied Probability and Statistics
In this course, are are only interested in applied probability and statistics.
We will not cover the mathematics of probability theory and stochastic processes, statistics (derivations and proofs) or the design of experiments - this is not a statistics course.
R&N Chapter 12.1 - 12.5
P&M Chapter 8.1
3.2 - Probability Terminology
Experiment An occurrence with an uncertain outcome that we can observe, e.g. rolling a die
Outcome The result of an experiment; one particular state of the world.
Sample Space The set of all possible outcomes for the experiment. For example {1,2,3,4,5,6}
Event A subset of possible outcomes that together have some property we are interested in. For example, the even "even die roll" is the set of outcomes {2,4,6}
3.3 - What is a Probability Distribution?
What do you think of when an event is described as "random"?
An unexpected event?
A uniform number between 0 and 1?
A normally distributed random value?
A random variable, denoted X, has an element of chance associated with its value
The level of chance associated with any particular value (or range of values), X=x is called its probability P(X=x). This is a positive value between 0 and 1.
The collection of probabilities over values that a variable may take is called a distribution, with the property that the sum of probabilities of all mutually exclusive, collectively exhaustive events is 1.
The value of any function of a random variable is also a random variable.
For example the sum of n random variables takes a random value.
Very loosely [1], just about anything that you can count or measure, has non-negative values, and that sums to one over all outcomes is a probability distribution
Fundamentally, both discrete and continuous variables, X, are represented by a cumulative distribution function cdf, denoted F(x)
The cdf is the probability that the realised value of X is less than or equal to x
F(x)=P(X≤x)
[1] Take it on trust that there is a serious branch of mathematics behind this, regarding topological spaces and measure theory.
3.4 - What is a Probability Distribution
The terms used for probability that X takes a particular value are different for discrete and continuous variables.
For discrete variables, a probability mass function (pmf), P(X=x) describes the chance of a particular event occurring
For finite discrete-value variables, this is easy to understand as a finite vector of non-negative values that sum to one.
For example, the chance of a coin toss, roll of dice, poker hands, etc.
For countably infinite discrete variables, the probability distribution is a series of numbers over an infinite set of distinct elements.
For continuous variables, a probability density function (pdf) f(x) is a continuous function that integrates from below to the cumulative density function.
F(X≤x)=∫−∞xf(y)dy
Python will very effectively help you to handle probabilities.
Many distributions have functions for probabilities, random number generation etc.
The methods that you will learn about available through the python random module, which is part of the standard library.
3.4.1 - Sampling Random Values
For example, a normal distribution can be sampled using:
>> import random as r
>> mu, sigma = 2.0, 4.0
>> x = r.gauss(mu, sigma)
1.3927394833370967
We can also sample a Weibull distribution, given by:
f(x∣a,b)=ab(ax)e−(ax)k
>> a, b = 1.0, 1.5
>> r.weibullvariate(a,b)
1.9157188803236334
In this course, you don't have to remember functional forms, etc.
Just focus on understanding a distribution's use and parameters.
We can generate an integer from 0 to 100 inclusive:
Conditional probability is a measure of the probability of an event given that another event has already occurred.
If the event of interest is A and the event B is known to have occurred, then the corresponding conditional probability of A given B is denoted P(A∣B)
If two events A and B are independent, then the probability of both occurring is:
P(A∩B)=P(A)P(B)
Otherwise, if the events are dependent
P(A∩B)=P(B)P(A∣B)=P(B)P(B∣A)
In both cases, the probability events A or B occurring is:
P(A∪B)=P(A)+P(B)−P(A∩B)
Bayes' rule rearranges the conditional probability relationships to describe the probability of an event, given prior knowledge of related events.
P(A∣B)=P(B)P(B∣A)P(B)
For example, knowing symptoms of a disease is easier than figuring out the disease given symptoms
4.0 - Search Under Uncertainty - AND-OR Trees
We want to find a plan that works regardless of what outcomes actually occur
Can no longer rely on a sequence of actions
Need a conditional plan. The action to perform depends on the output of the previous action
Need a different type of tree data structure
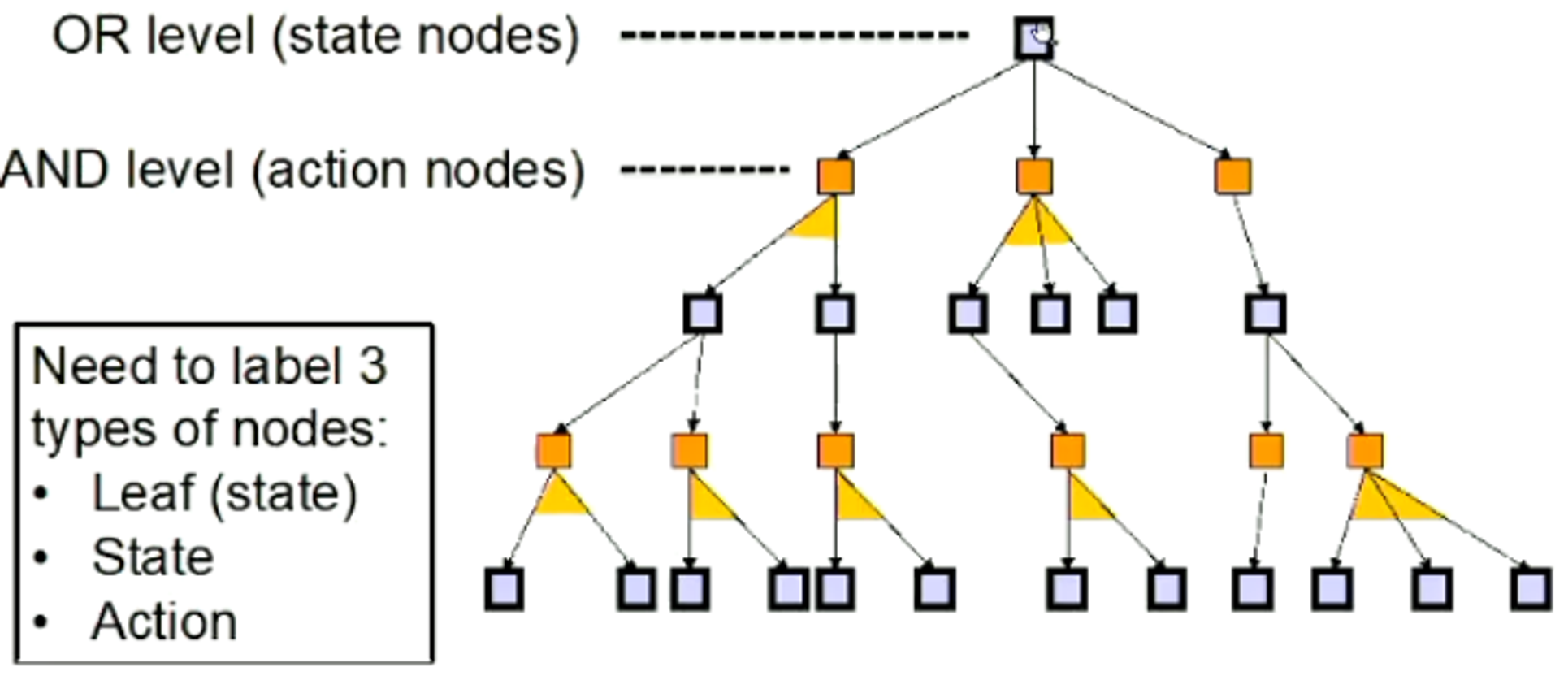
4.1 - AND-OR Search Tree
A tree with interleaving AND and OR levels
At each node of an OR level, branching is introduced by the agent's own choice
At each node of an AND level, branching is introduced by the environment
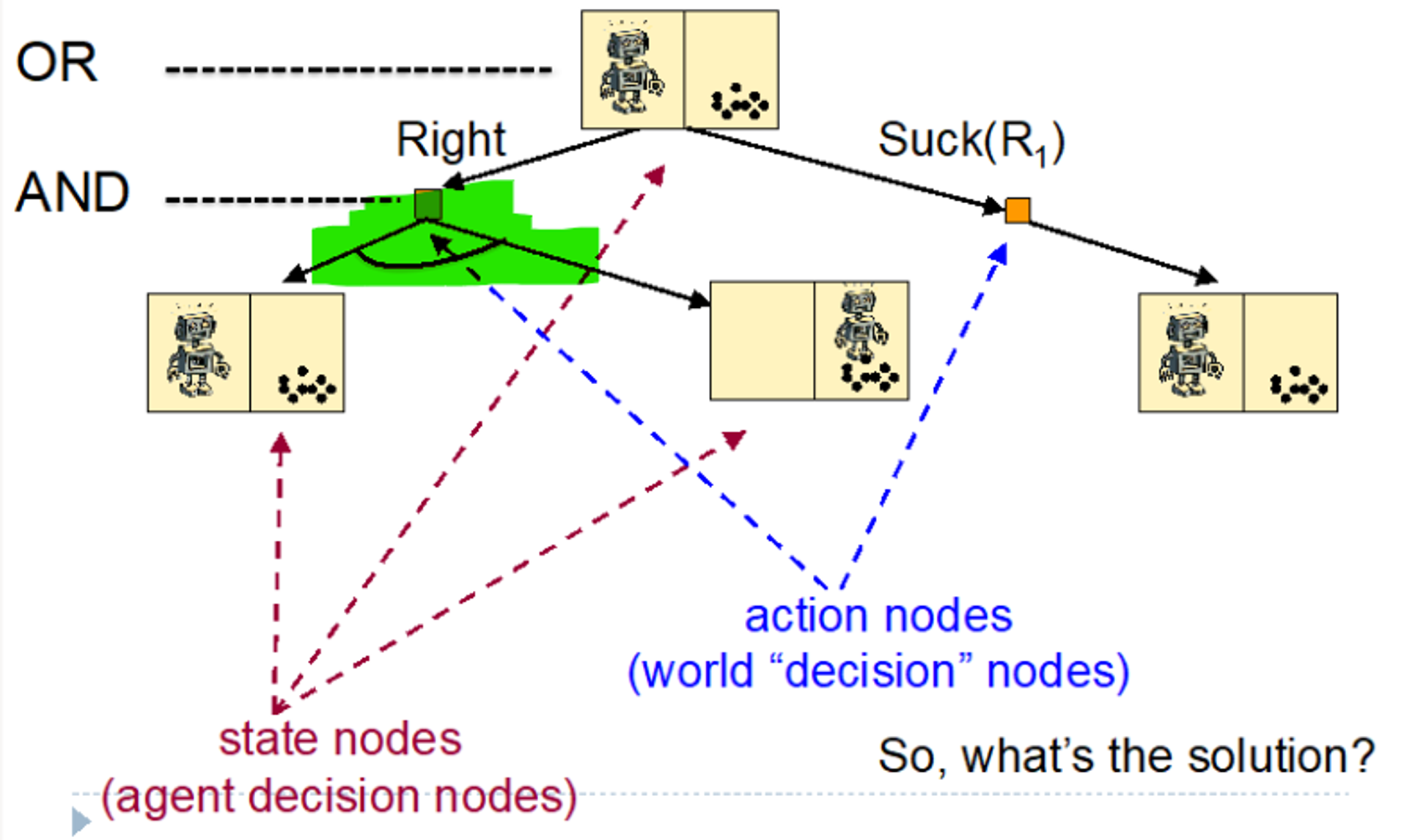
4.1.1 - Slippery Robot Vaccum
States: Conjunctions of the following state factors
Robot Positions: {in R1,in R2}
R1 state: {clean, dirty}
R2 state: {clean, dirty}
Action: {Left, Right, Suck(R1),Suck(R2)}
World Dynamics: Non deterministic, after performing an action state, the robot may end up in one of several possible states
Successors of (Robot in R1,Right)={Robot in R1,Robot in R2}
Successors of (Robot in R2,Left)={Robot in R1,Robot in R2}
(The rooms are slippery, the robot might not move into the other room
Initial State (Robot in R1)∧(R1 is clean)∧(R2 is dirty)
Goal state (R1 is clean)∧(R2 is clean)
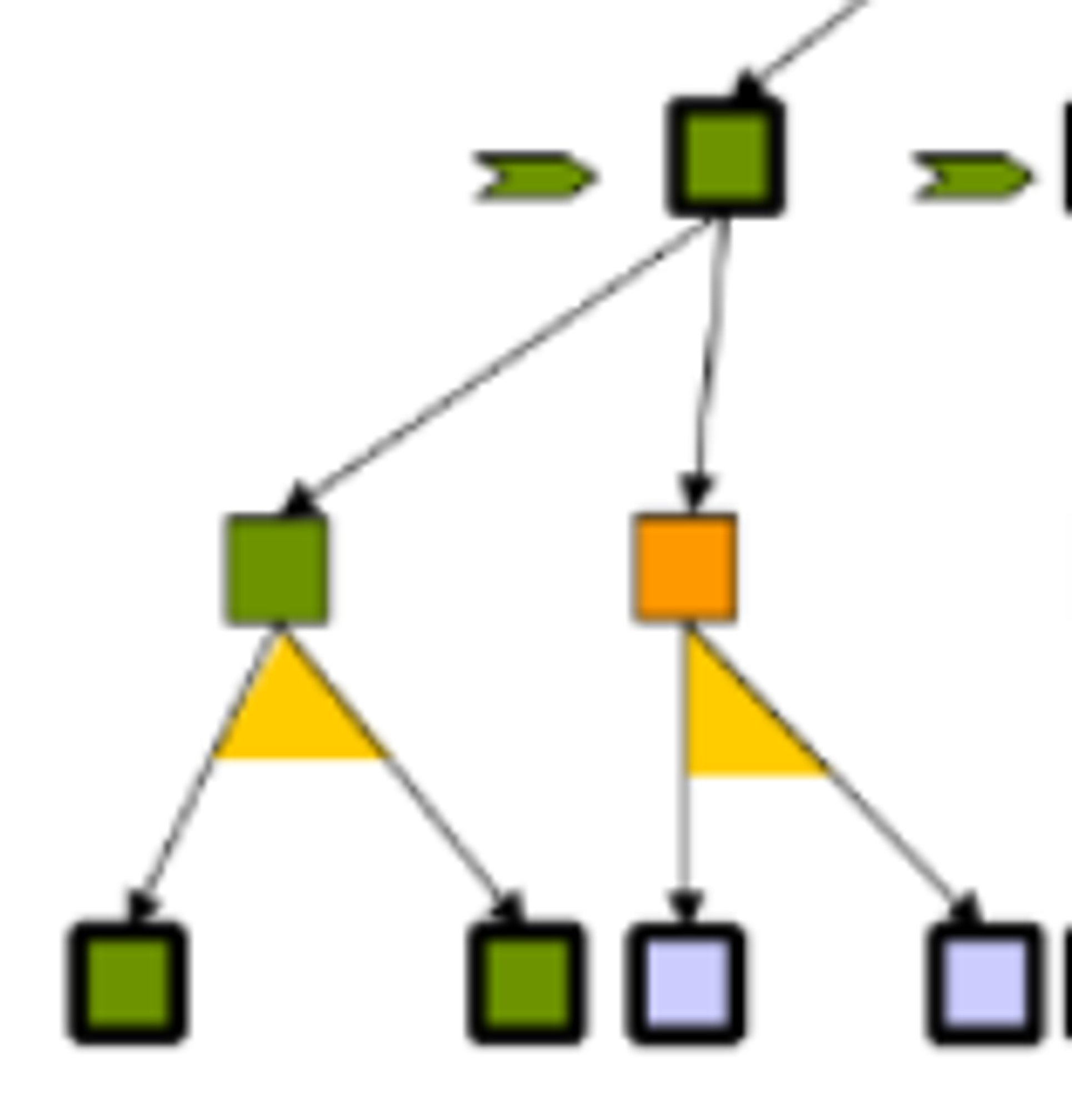
4.1.2 - And-Or tree of the Slippery Vacuum Robot
Note that the arc across the outcomes (as highlighted in green) indicates that there is a probability of landing in the various states.
The non-determinism of the environment is modelled in the AND layer
The choice of state is deterministic when the agent makes a decision
4.1.3 - AND-OR Search Tree
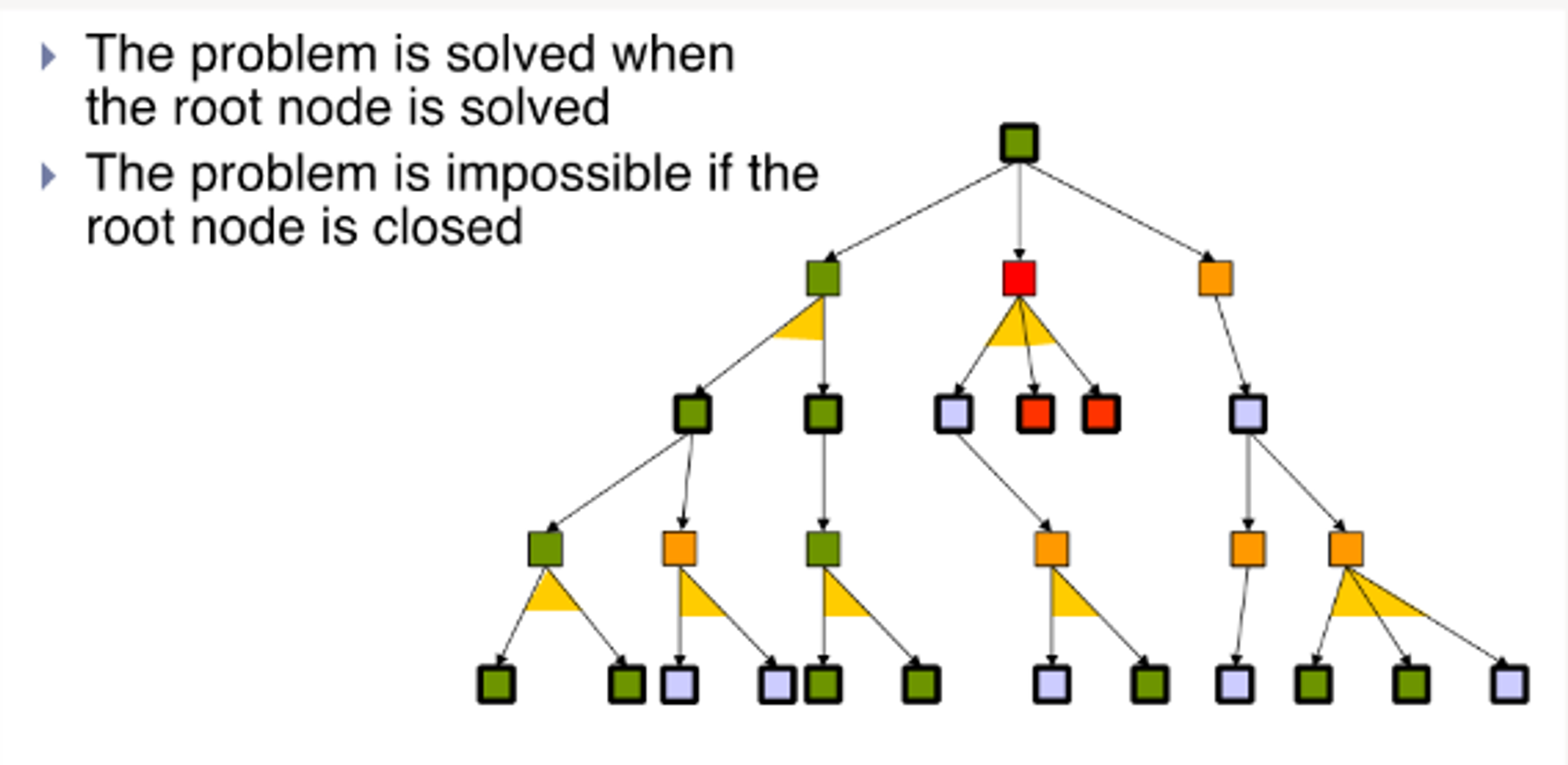
A solution in an AND-OR tree is a sub-tree that:
Has a goal node at every leaf
Specifies one action at each node of an OR level
Includes every outcome branch at each node of an AND level
When do we have a solution?
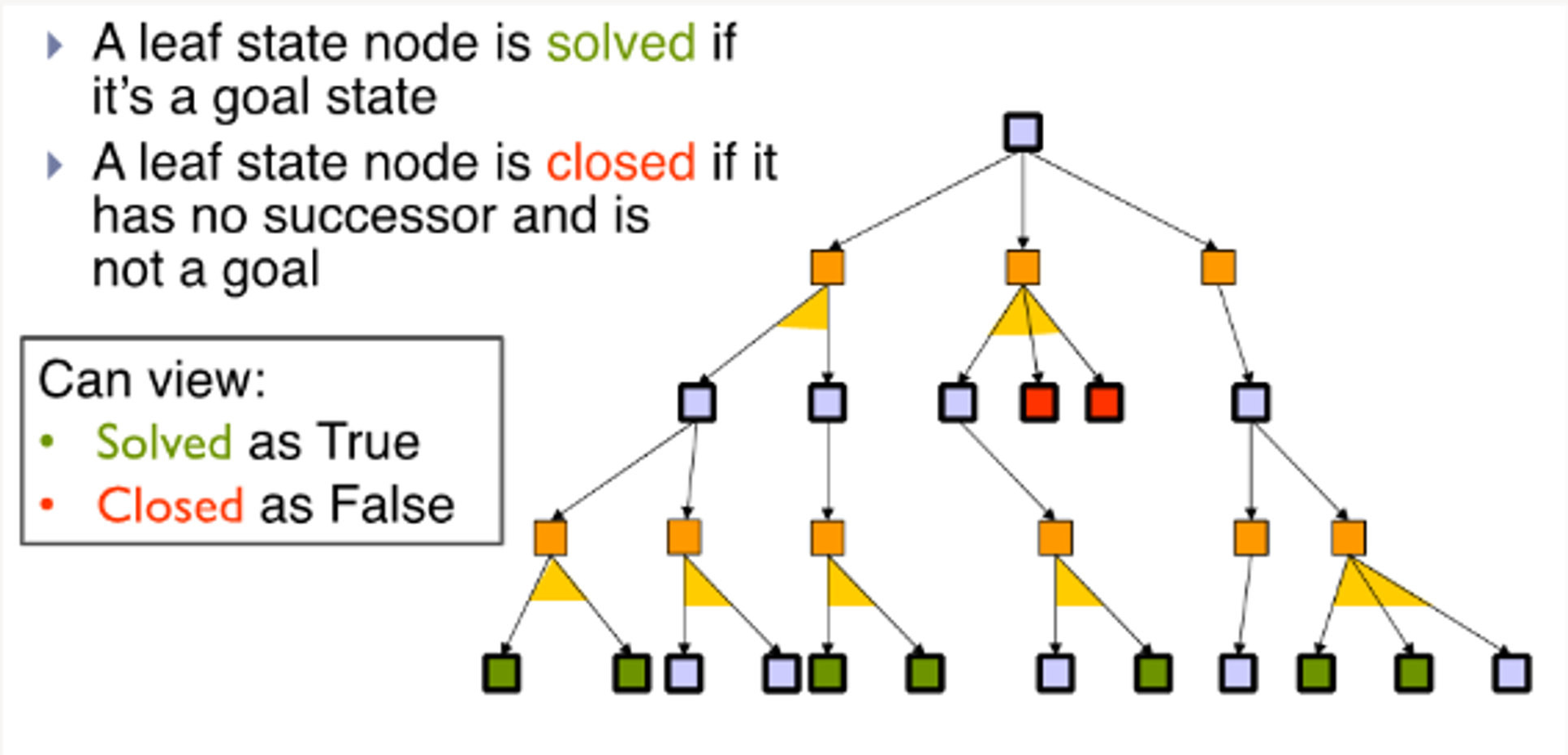
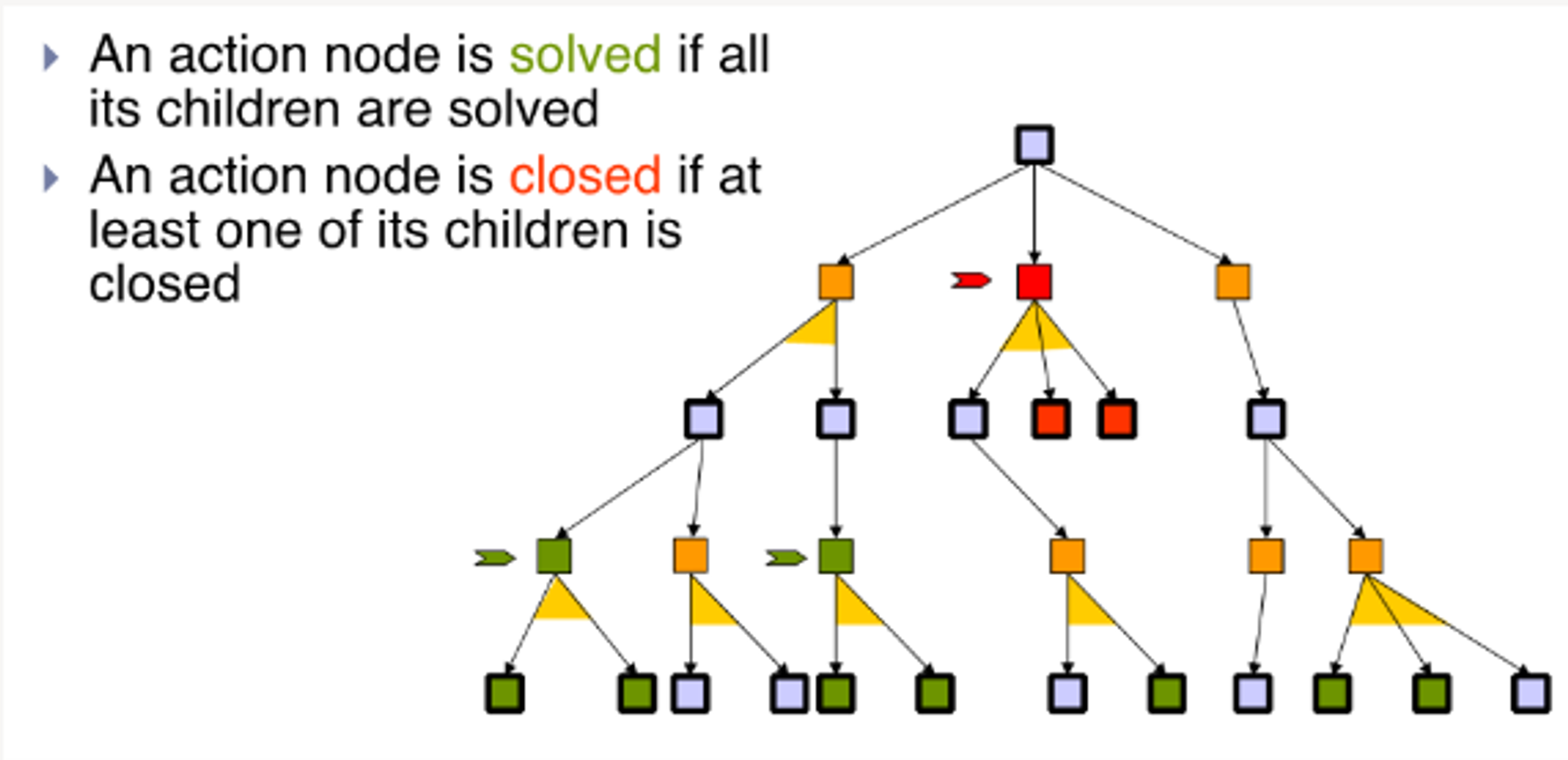
4.1.4 - Labelling an AND-OR Tree
Notice that An action node is closed if at least one of its children is closed
This is as we might end up in an invalid state as a result of the conditional probabilities.
We can propagate up the solution to the parent nodes
Both leaf nodes must be solved for the solution to propagate upward.
In this subtree, it doesn't matter that the AND node isn't closed - we can choose not to take that branch as our actions in this aspect of the world is deterministic
Keep labelling until the root to determine a solution path
What happens when a node is the same as an ancestor node? A loop in the and-or tree?
We can keep doing the action again and determine if we can get to another state as a result of the environment's non-determinism
Searching an And-Or Tree
Start from a state node (at the OR level)
Fringe nodes are the state nodes
Using any of the search algorithms we have studied:
Select a fringe node to expand
Select an action to use
Insert the corresponding action node
Insert all possible outcomes of the action as the child of the action node
Back up to re-label the ancestor nodes
Cost/reward calculation at AND level
Weighted sum (when uncertainty is quantified using probabilities, expectation)
Taking the maximum cost / minimum reward (conservative)
Decision Theory
Modelling decision making under uncertainty.
Preferences
Actions result in outcoems
Agents have preferences over outcomes
A rational agent will do the action that has the best outcome for them
Sometimes agents don't know the outcomes of the actions, but they still need to compare actions
Agents have to act (Doing nothing is often an action)
Preferences over Outcomes
Some notation:
The preference relation ≻ means is preferred to or succeeds in a preference relation
≺ is precedes in a preference order or is not preferred to or is preferred less than
∼ is indifference
If o1 and o2 are outcomes
o1⪯o2 means that o1 is at least as desirable as o2
o1∼o2 means o1⪯o2 and o1⪰o2
o1≻o2 means o1⪰o2 and o2⪰o1
Lotteries
An agent may not know the outcomes of its actions, but only have a probability distribution of the outcomes
lottery is a probability distribution over the outcomes:
P&N denote this [p1,o1:p2,o2:,...:pk,k]
P&M denote this [p1:o1,p2:o2,...,pk:k]
where the i are outcomes and pi≥0 such that ∑ipi=1
The lottery specifies that outcome i occurs with probability pi
Alternatively, an agent may choose to select an action using a lottery
When we talk about outcomes, we include lotteries over "pure" outcomes (where pure outcomes are fully defined and either happen or not)
Axioms of Rational Preferences
Idea: Preferences of a rational agent must obey certain rules
Rational preferences imply behaviour describable as maximisation of expected utility
An agent prefers a larger chance of getting a better outcome than a smaller chance:
If o1≻o2 and p>q then (Given two pure outcomes o1 and o2, construct a lottery.
[p:o1,1−p:o2]≻[q:o1,1−q:o2]
The probability of outcome 1 occurring in the first lottery is greater than the probability in the second lottery, (and likewise, the probability of outcome 2 occurring is greater in the second lottery as compared to the probability of outcome 2 occurring in the first lottery)
Therefore, we prefer lottery 1 over lottery 2 to maximise the chances of outcome 1 occurring
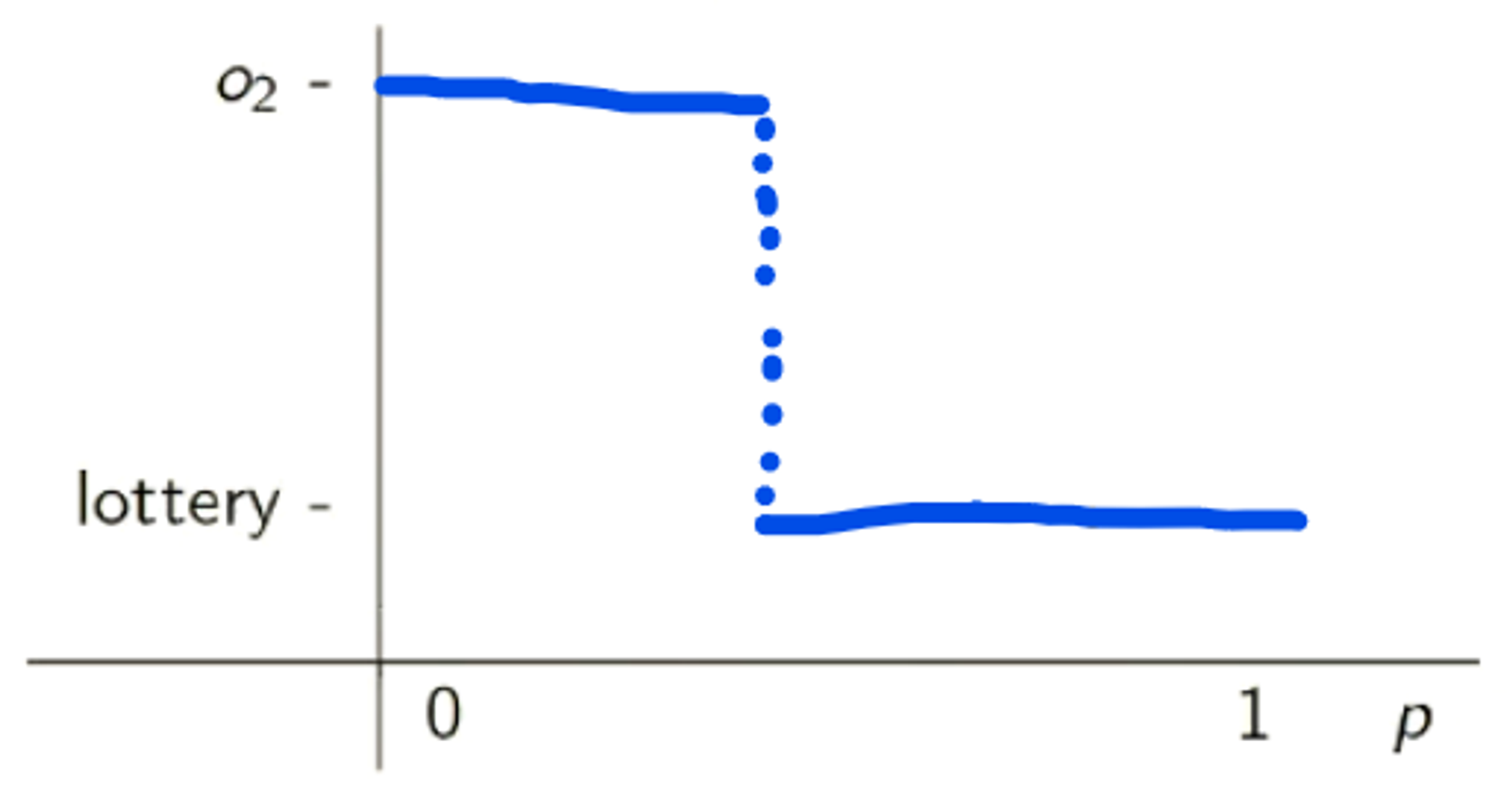
Continuityo1≻o2≻C⇒∃p∈[0,1][p:o1,1−p:C]∼o2
At some point, we favour a different outcome
Suppose o1≻o2 and o2≻o3. Consider a situation where the agent is trying to choose between o2 and the lottery [p:o1,1−p:o3] for values of p∈[0,1].
For the lottery, P(o1)=p,P(o3)=1−p
When p=0, we are effectively comparing o2 to o3 - we know that o2≻o3 (o2 is preferred to o3).
When p=1, the chance of getting o1 in the lottery is 100% - we prefer the lottery
If o1∼o2 then the agent is indifferent between lotteries that only differ by o1 and o2
We are indifferent about the decisions between o1 and o2, and the outcome C is irrelevant to the expression/property.
Alternative Axiom for Substitutability
If o1⪰o2 then the agent weakly prefers lotteries that contain o1 instead of o2, everything else being equal.
That is, for any number p and outcome o3
[p:o1,(1−p):o3]⪰[p:o2,(1−p):o3]
Decompostability (no fun in gambling): An agent is indifferent between lotteries that have the same probabilities and outcomes