It is inconsistent with the axioms of preferences to have A≻B,D≻C
A,C: lottery [0.11:$1M,0.89:X]
B,D: lottery [0.10:$25M,0.01:$0,0.89:X]
1.5 - Framing Effects - Tversky and Kahneman
A disease is expected to kill 600 people. Two alternative programs have been proposed:
Program A: 200 people will be saved
Program B: 31→ 600 people will be saved
$2\over3$→ no one will be saved
A disease is expected to kill 600 people. Two alternative programs have been proposed:
Program C: 400 people will die
Program D: 31→ No one will die
$2\over3$→ 600 will die
Programs are the same, just different framing of the same problem
2.0 - Decision-Theoretic Planning
2.1 - Agents as Processes
Agents carry out actions
Infinite horizon Forever
Indefinite horizon Until some stopping criteria is met
Finite horizon Finite and fixed number of steps
2.2 - Decision-Theoretic Planning
What should an agent do when:
It gets rewards (and penalties) and tries to maximise its rewards received?
Actions can be stochastic (non-deterministic); the outcome of an action can't be fully predicted
2.3 - Initial Assumptions for Decision-Theoretic Planning
Flat instead of modular or hierarchical (everything in this course will be flat)
Explicit states instead of features, individuals or relations
Indefinite / infinite stages instead of static or finite stages
Fully observable instead of partially observable (we can exactly sense the state we are in)
Stochastic dynamics instead of deterministic dynamics (can't perform actions deterministically)
Complex preferences instead of goals
Single agent interaction instead of multiple agents
Knowledge is given instead of knowledge is learned
Perfect rationality instead of bounded rationality
3.0 - Markov Decision Processes
A framework to find the best sequence of actions to perform when the outcome of each action is non-deterministic
The basis for Reinforcement Learning
Used to solve games like Tic-Tac-Toe, Chess, Go, in control systems for traffic systems and navigation systems.
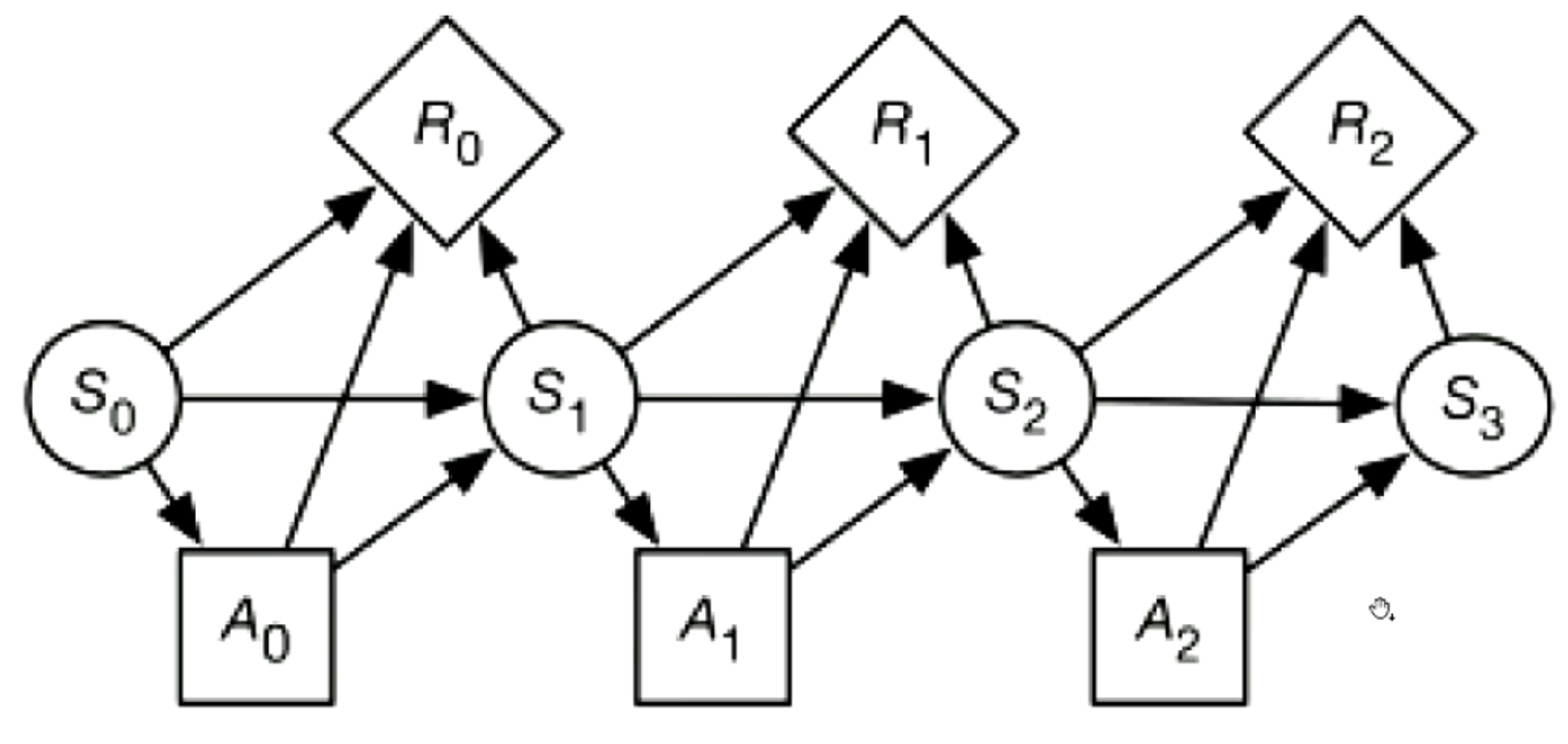
3.1 - World State
The world state is the information such that if the agent knew the world state, no information about the past is relevant to the future - Markovian assumption
Sk is a state at time k, and Ak is the action at time k
P(St+1∣S0,A0,...,St,At)=P(St+1∣St,At)
The next state is only dependent on the current state - i.e. memoryless property.
P(s′∣s,a) is the probability that the agent will be in state s′ immediately after performing action a in state s
The state captures all relevant information from the history
The state is a sufficient statistic of the future
The dynamics is stationary if the probability distribution is the same for each time point.
3.2 - MDPs vs Markov Chains
A Markov Decision Process augments a Markov Chain with actions and values:
When you perform an action on a given state, you get a new state and some associated rewards.
A Markov Decision Process consists of:
Set of States (S)
Set of Actions (A)
Transition Function P(St+1∣St,At) for stochastic / probabilistic environment
Reward Function R(StAt,St+1) specifies the reward at time t
Sometimes is a random variable.
R(s,a,s′) is the expected reward received when the agent is in state s, does action a and ends up in state s′
Sometimes we use R(s,a)=∑s′P(s′∣s,a)×R(s,a,s′)
γ is a discount factor
An MDP's objective is to maximise the expected value of the rewards - E[∑t=0TγtR(st,at)]
Similar to a Utility function that we try to optimise
3.2.1 - MDP Examples - To Exercise or Not || Simple Grid World
Example - To Exercise or NotStates = {fit, unfit}
Actions = {exercise, relax}
Dynamics:
StatefitfitunfitunfitActionexerciserelaxexerciserelaxp(fit|State, Action)0.990.70.20.0
In the long run, we can see that being fit is going to be beneficial (lead to greater reward)
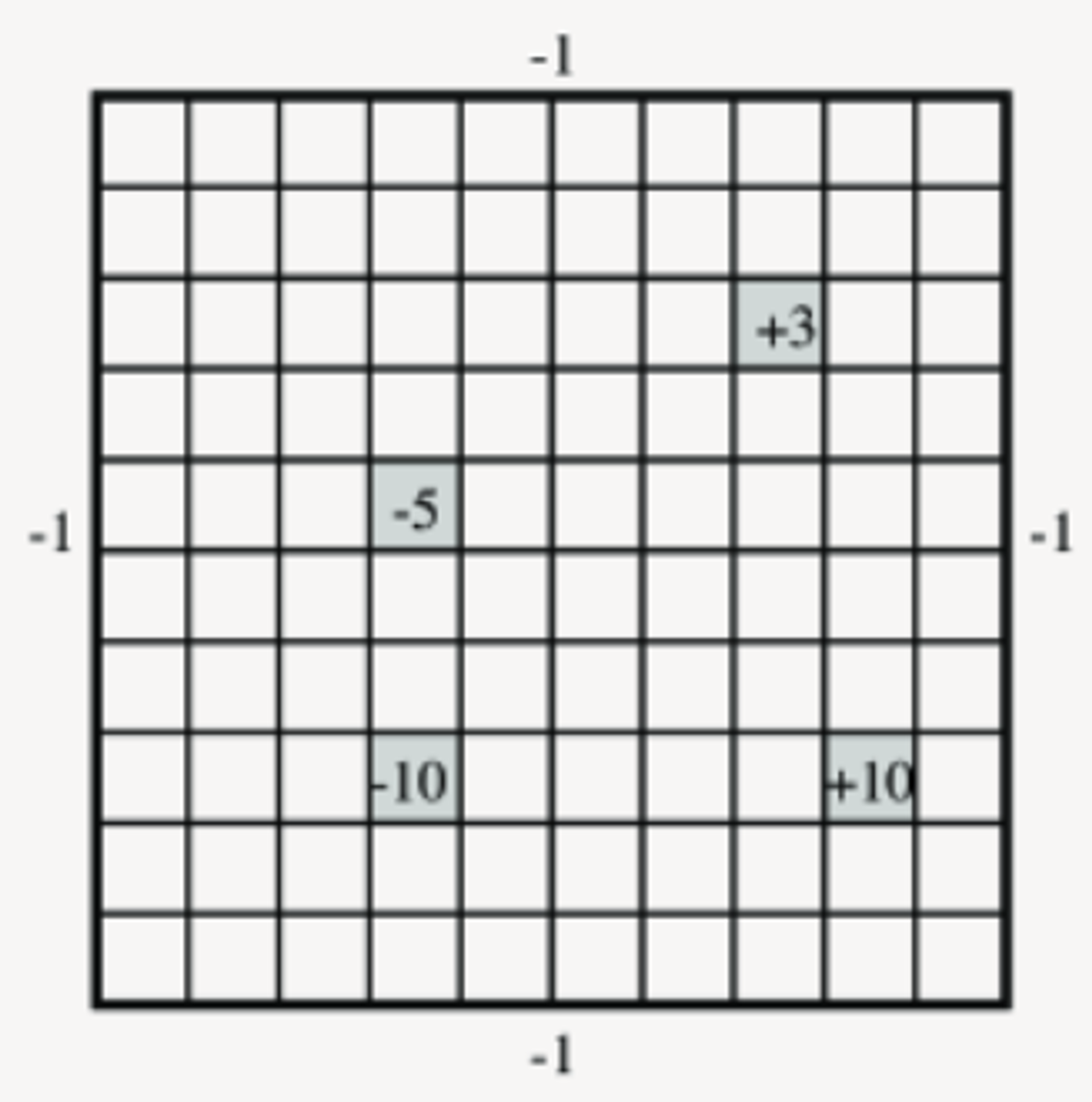
Example - Simple Grid World
The agent can be in any grid cell
In certain cells, the agent is given positive (or negative) reward.
If you collide with the walls there is a reward of -1
States: 100 states corresponding to the position of the agent / robot
Actions: Up, Down, Left, Right
Transition: Robot goes in the commanded direction with probability 0.7 and one of the other directions with probability 0.1
Rewards: If it crashes into an outside wall, it remains in its current position and has a reward of -1. For special reward states - the agent gets the reward when leaving the state.
3.3 - Planning Horizons
The planning horizon is how far ahead the planner looks to make a decision
The robot gets flung to one of the corners at random after leaving a positive (+10 or +3) reward state
The process never halts
Infinite planning horizon
The robot gets +10 or +3 in the state, then it stays there getting no reward, or it is left with only a special action exit and the episode ends - these are absorbing states
The robot will eventually reach an absorbing state - non-zero probability of getting to the +10 or +3 reward state from other states
Indefinite horizon
3.4 - Information Availability
What information is available when the agent decides what to do?
Fully-observable MDP / FOMDP - The agent gets to observe St when deciding on action At
Partially-observable MDP / POMDP - the agent has some noisy sensor of the state
It is a mix of a hidden Markov model and MDP - It need to remember (some function of) its sensing and acting history.
3.5 - Policy
A policy is a sequence of actions, taken to move from each state to the next state over the whole time horizon
A stationary policy is a function or a map
π:S→A
Given a state s, π(s) specifies what action the agent who is following π will do.
An optimal policy, usually denoted π∗ is one with the maximum expected discount reward
maxπE[t=0∑γtR(st,π(st)]
Where π(t) is the action taken at time t
Here, we replace the action with the action determined by the policy.
We want to find optimal π(s) so that we can optimise our reward.
For a fully observable MDP with stationary dynamics and rewards with infinite or definite horizon, there is always an optimal stationary policy.
3.5.1 - MDP Example - To Exercise or Not
To Exercise or Not || Simple Grid World
Example - To Exercise or NotStates = {fit, unfit}
Actions = {exercise, relax}
Dynamics:
StatefitfitunfitunfitActionexerciserelaxexerciserelaxp(fit|State, Action)0.990.70.20.0
In the long run, we can see that being fit is going to be beneficial (lead to greater reward)
Example - Simple Grid World
The agent can be in any grid cell
In certain cells, the agent is given positive (or negative) reward.
If you collide with the walls there is a reward of -1
States: 100 states corresponding to the position of the agent / robot
Actions: Up, Down, Left, Right
Transition: Robot goes in the commanded direction with probability 0.7 and one of the other directions with probability 0.1
Rewards: If it crashes into an outside wall, it remains in its current position and has a reward of -1. For special reward states - the agent gets the reward when leaving the state.
3.5.2 - Solutions to MDP Problems
For the simple grid world navigation:
A policy, or mapping from states to actions (π:S→A) could be given as shown in the figure to the right
A policy π(s) tells us what action the agent should perform for each state
The optimal policy π∗(s) tells us what the best action the agent should perform for each state.
3.6 - Discounted Rewards
How much you value immediate rewards vs future rewards.
V=r1+γr2+γ2r3+⋅⋅⋅+γk−1rk+⋅⋅⋅
V=∑k=1∞γk−1rk
The discount factor γ∈[0,1) gives the present value of future rewards.
The value of receiving reward r after k+1 time steps is γkr
This values immediate reward above delayed reward
γ close to 0 leads to myopic evaluation (short-sighted)
γ close to 1 leads to far sighted evaluation
3.7 - Value of a Policy
We first approach MDPs using a recursive reformulation of the objective called a value function
The value function of an MDP, Vπ(s) is the expected future reward of following an (arbitrary) policy π starting from state s, given by:
Vπ(s)=s′∈S∑P(s′∣π(s),s)[R(s,π(s),s′)+γVπ(s′)]
Where the policy π(s) determines the action taken in state s
P(s′∣π(s),s) is our transition function for our stochastic world.
R(s,π(s),s′) is our reward function
γVπ(s′) is our discounted future value function
Here, we have dropped the time index as it is redundant, but note that at=π(st)
Note that this is a recursive definition - the value of Vπ(s) depends on the value of Vπ(s′)
Given a policy π
The Q-function represents the value of choosing an action and then following policy π in every subserquent state.
Qπ(s,a), where a is an action and s is a state, is the expected value of doing a in state s, then following policy π
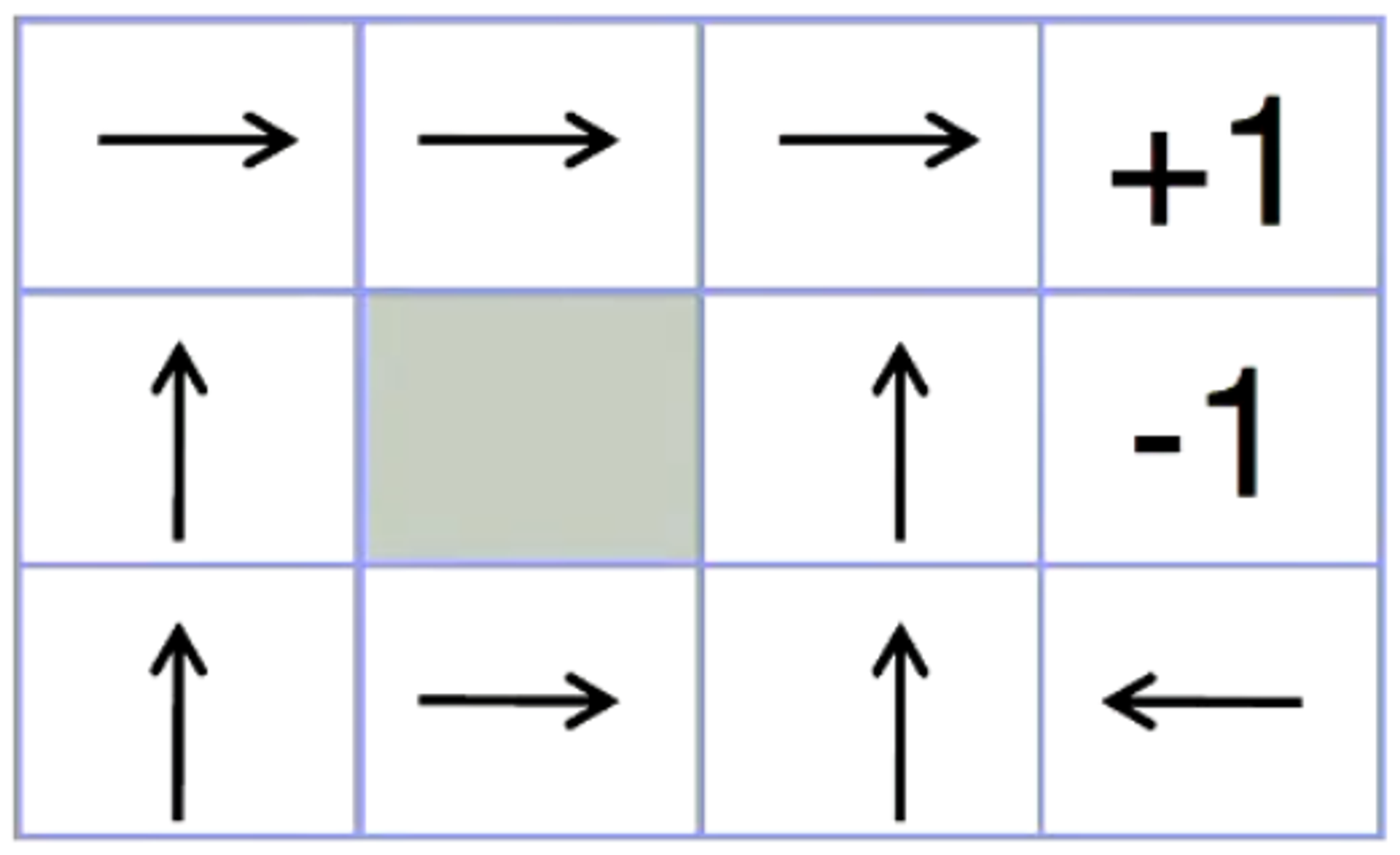
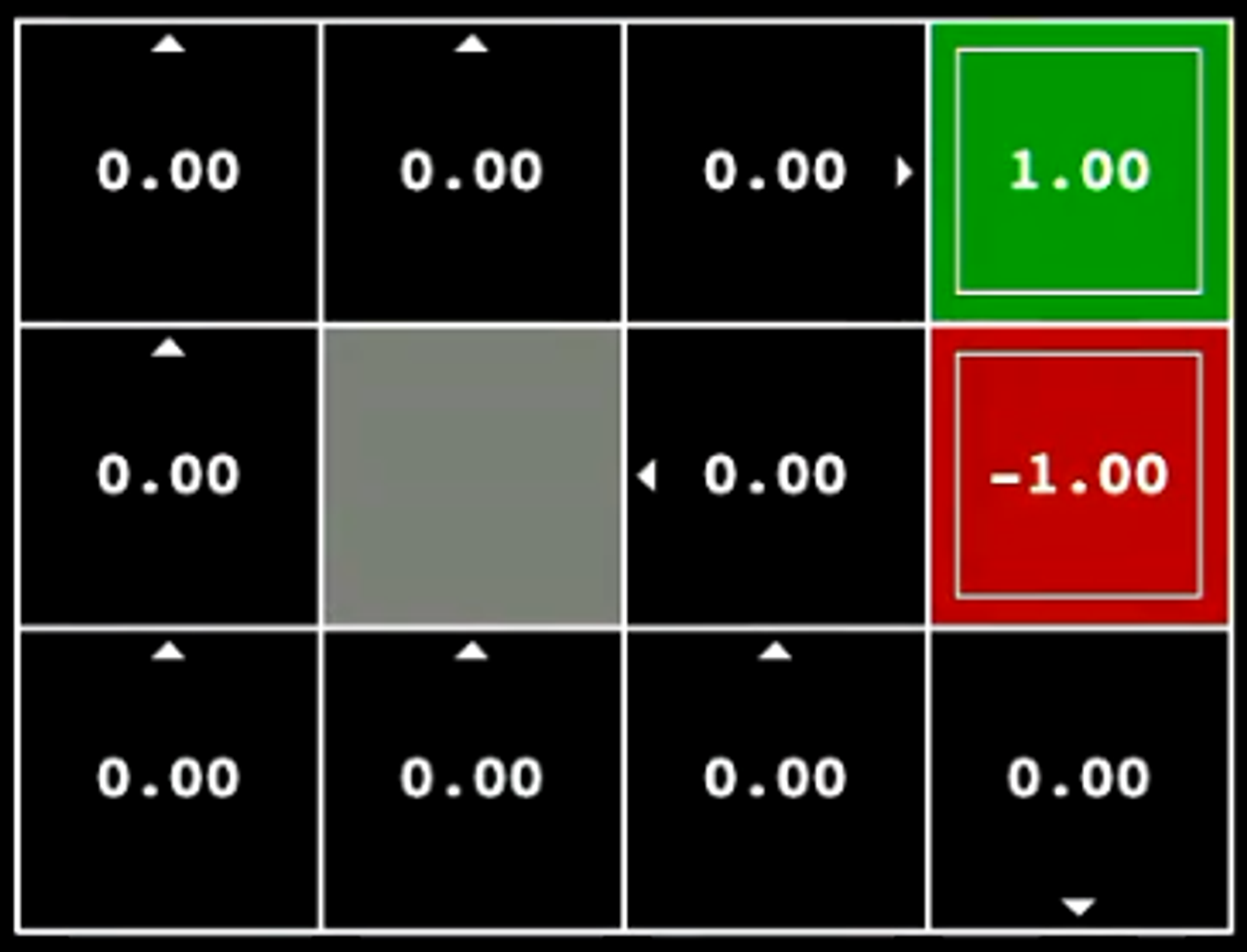
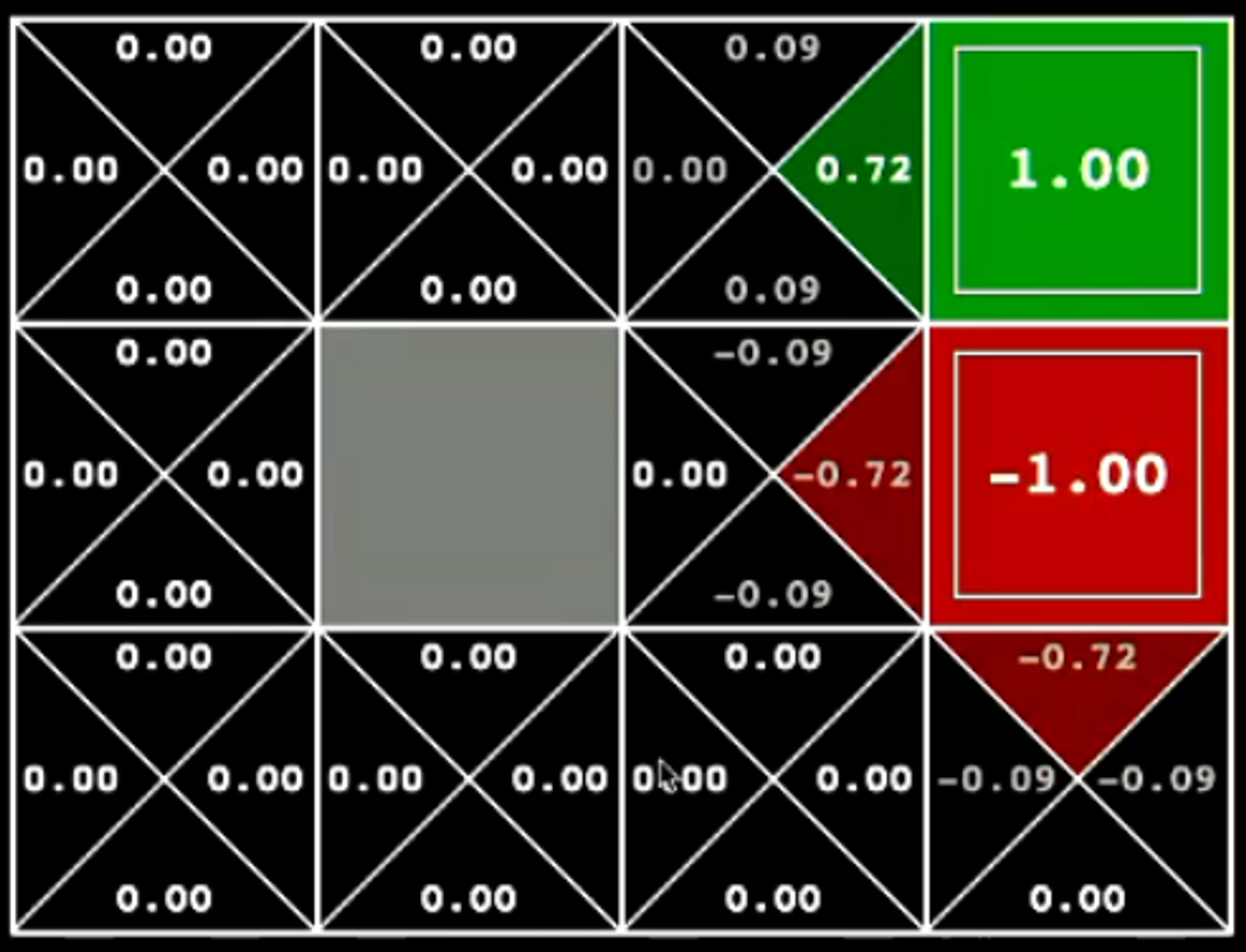
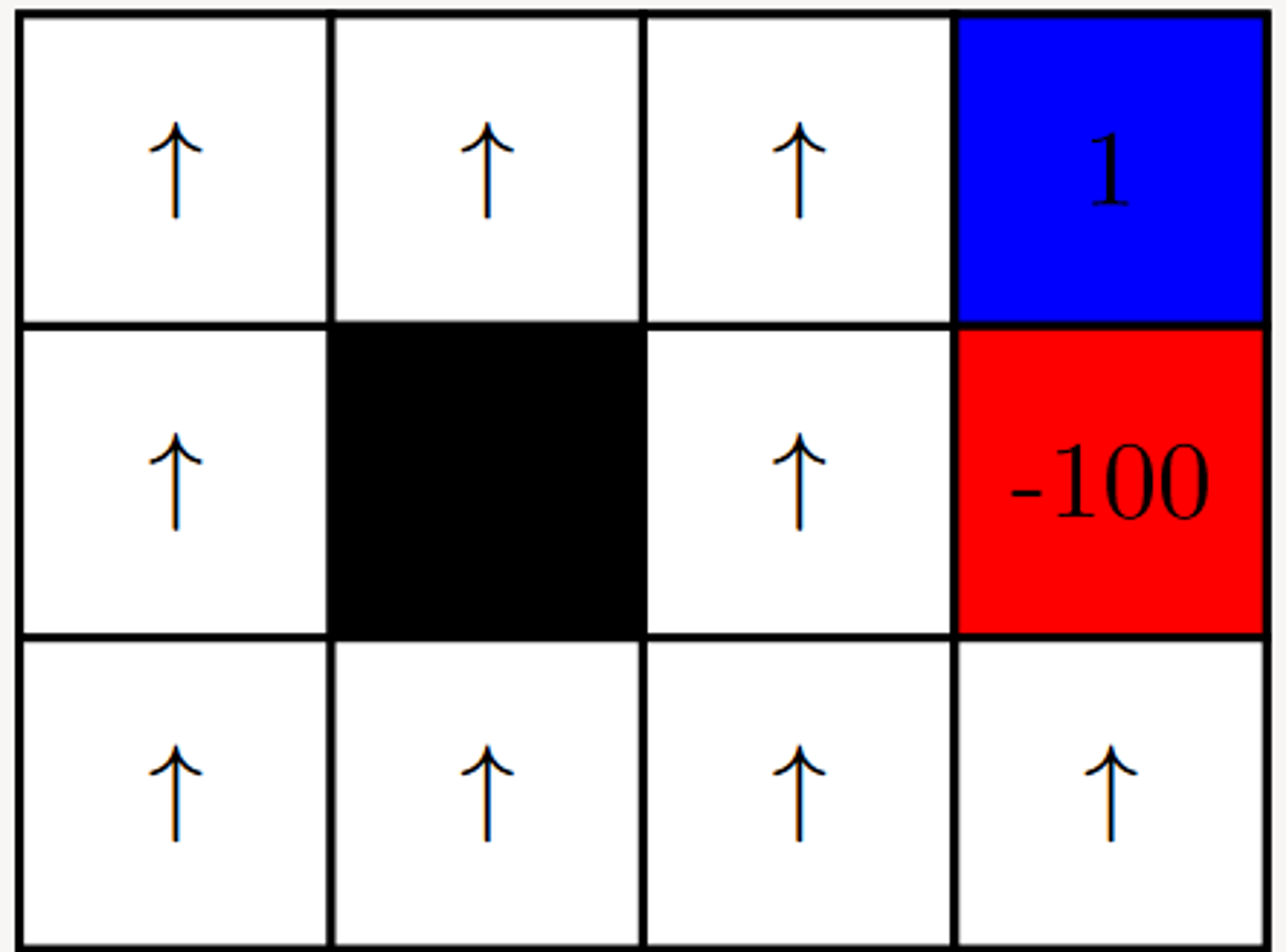
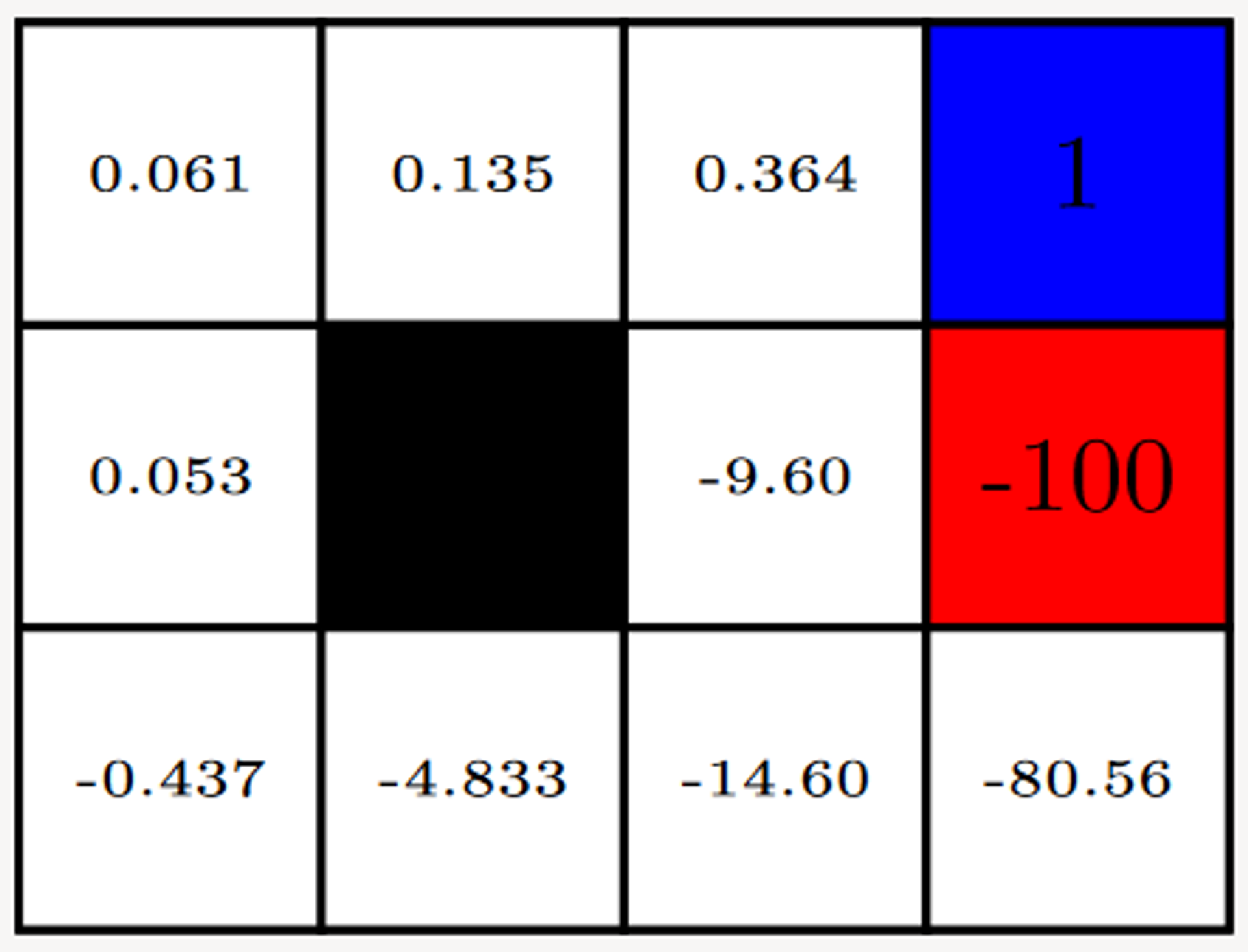
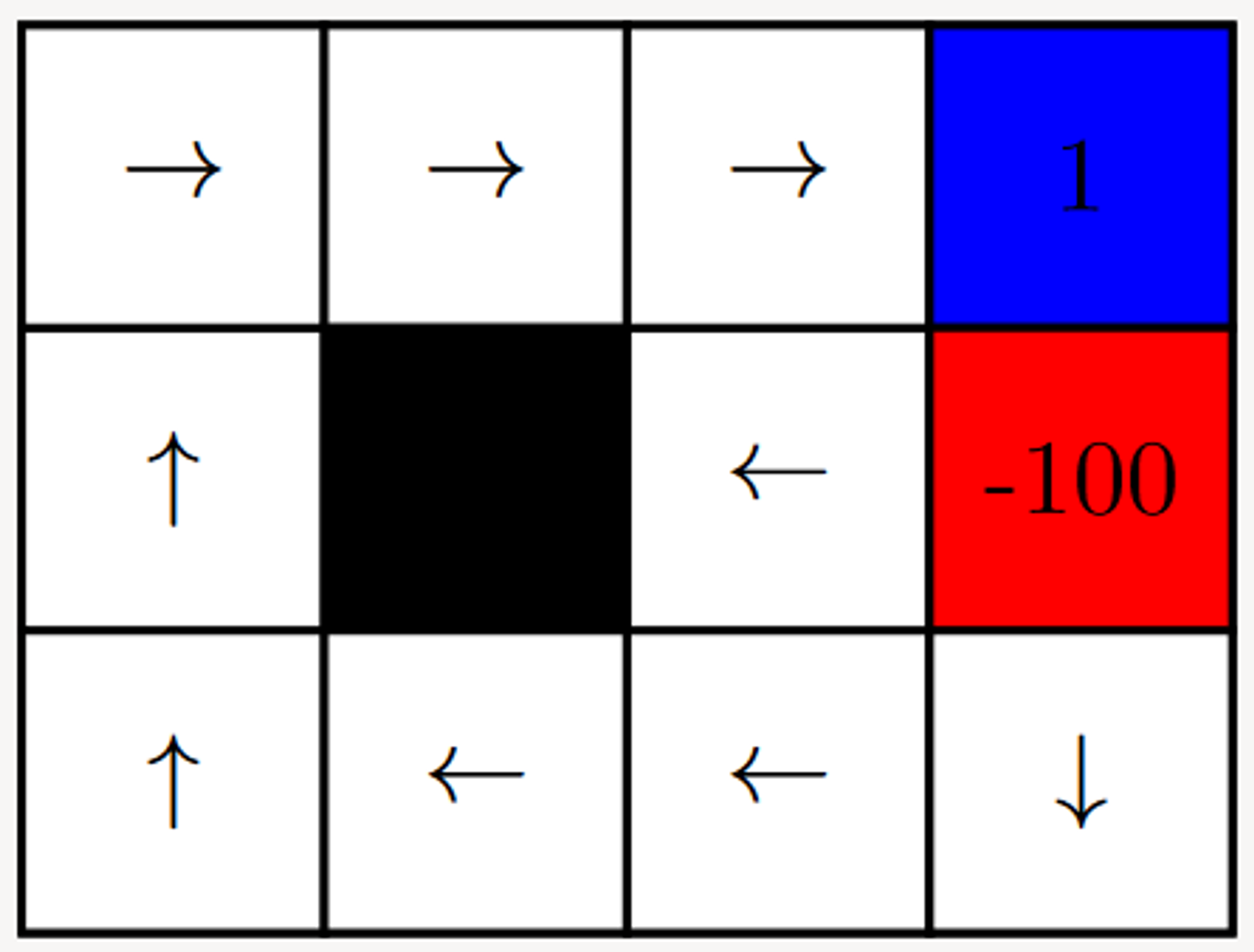
Given the following Grid World, Value Iteration can be performed to determine the optimal path / sequence of actions.
Shown below are the values of each state V∗(s) (as shown on the left) and the Q∗(s,a) value after performing an action.
Note here that in each state, V∗(s)=max(Q∗(s,a))
Grid-World with two terminal states {+1, -1} and a series of actions that are possible.Value Iteration - V-Value after 100 iterationsValue Iteration - Q-Value after 100 iterations
4.1 - Value Iteration Mechanics
Let Vk be a k-step lookahead value function (expected reward, up to time step k)
Idea Given an estimate of the k-step lookahead value function, determine the k+1 step lookahead value function
Set V0 arbitrarily, e.g.:
V^(s)←0
Compute Vi+1 from Vi - loop for all states s
Vi+1(s)=maxas′∑P(s′∣a,s){R(s,a,s′)+γVi(s′)}
Once the values converge, recover the best policy from the current value function estimate
arg maxas′∑P(s′∣a,s){R(s,a,s′)+γV^(s′)}
i.e. pick the action that maximises the value of the Q(s,a) function
Theorem: There is a unique function V∗ that satisfies these functions
If we know V∗, the optimal policy can be generated easily
Guaranteed to converge to V∗
No guarantee we'll reach optimal solution in finite amount of time, but in practice this converges exponentially fast (in k) to the optimal value function
The error reduces proportionally to 1−γγk
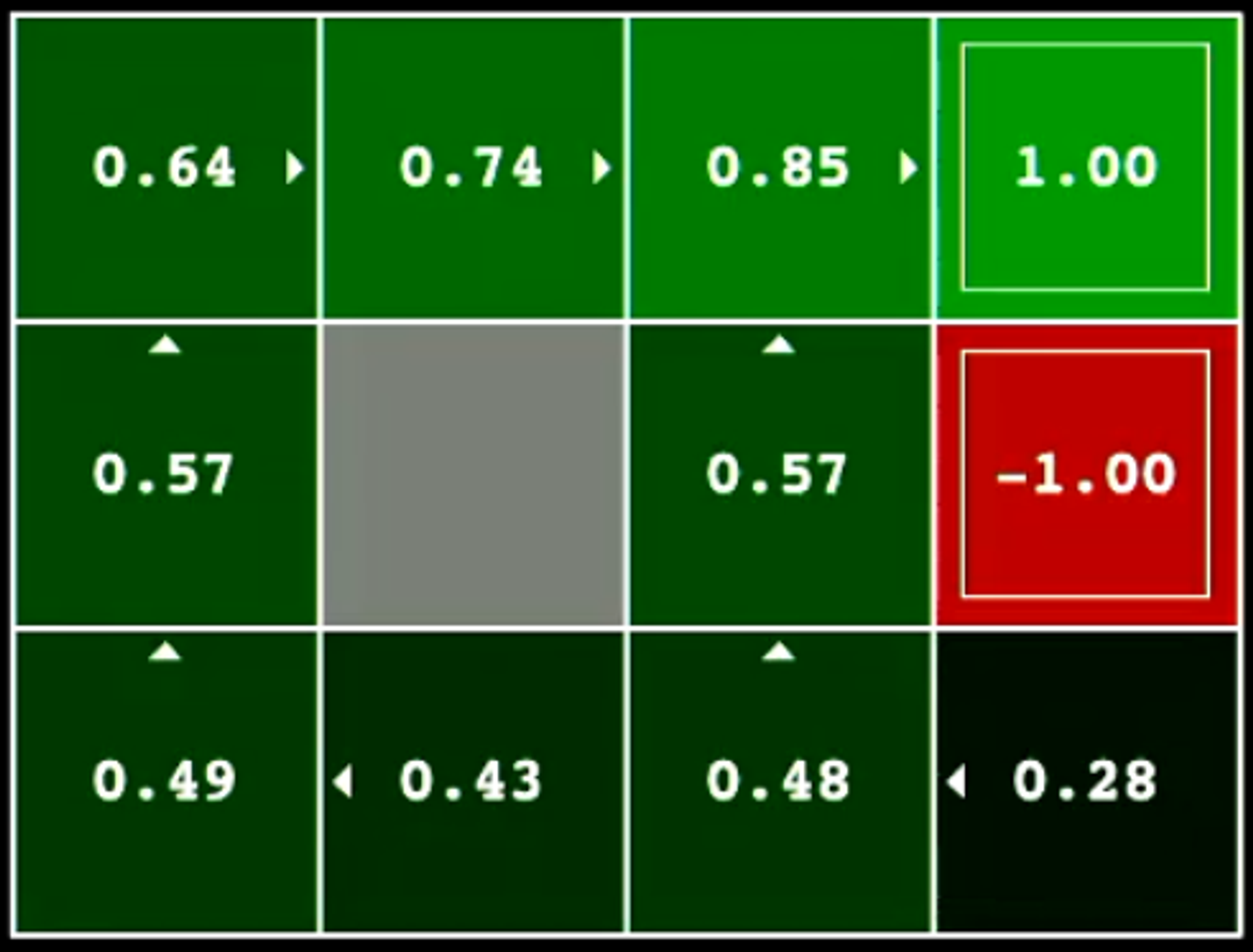
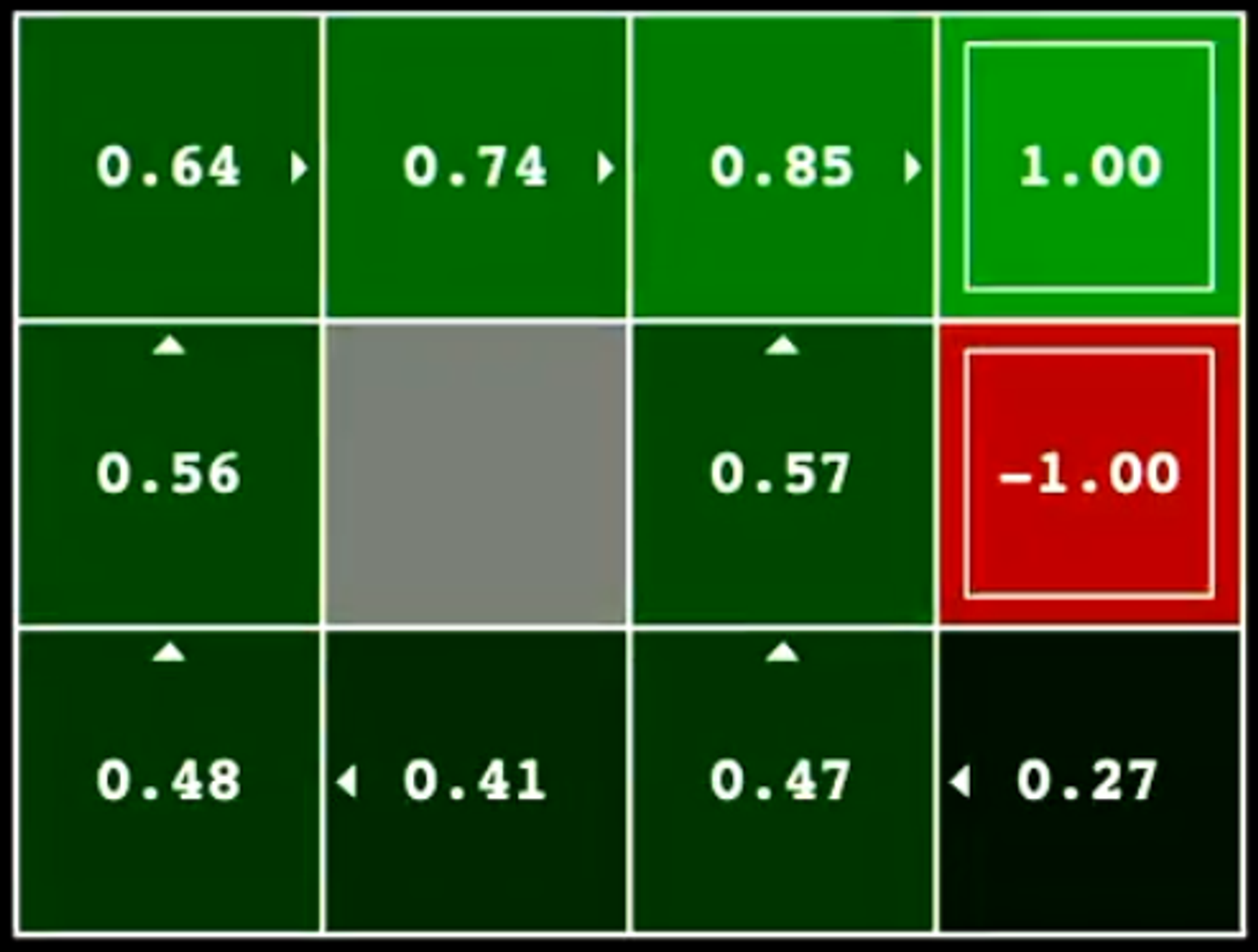
4.2 - Value Iteration Example - Grid World
Step 1 - Initialisation
After the first iteration of value iteration, we see that we have some initial results and observations
Our agent tries to move in the direction that optimises the value of the function V∗(s).
We see that for the square directly adjacent to the state [1.00] the value iteration model indicates that that is the best action is to move toward that state.
Additionally, for the squares directly adjacent to the [-1.00] square, the value iteration model indicates that the best action is to move away from that state.
The Q-Values also indicate that moving toward the [1.00] node is the best action when in an adjacent state and that moving away from the [-1.00] state is the best action when in an adjacent state.
However, when providing this information to the agent, it doesn't have enough information to efficiently solve the puzzle.
Note here that the value iteration step was performed completely offline (before the agent started interacting with the environment).
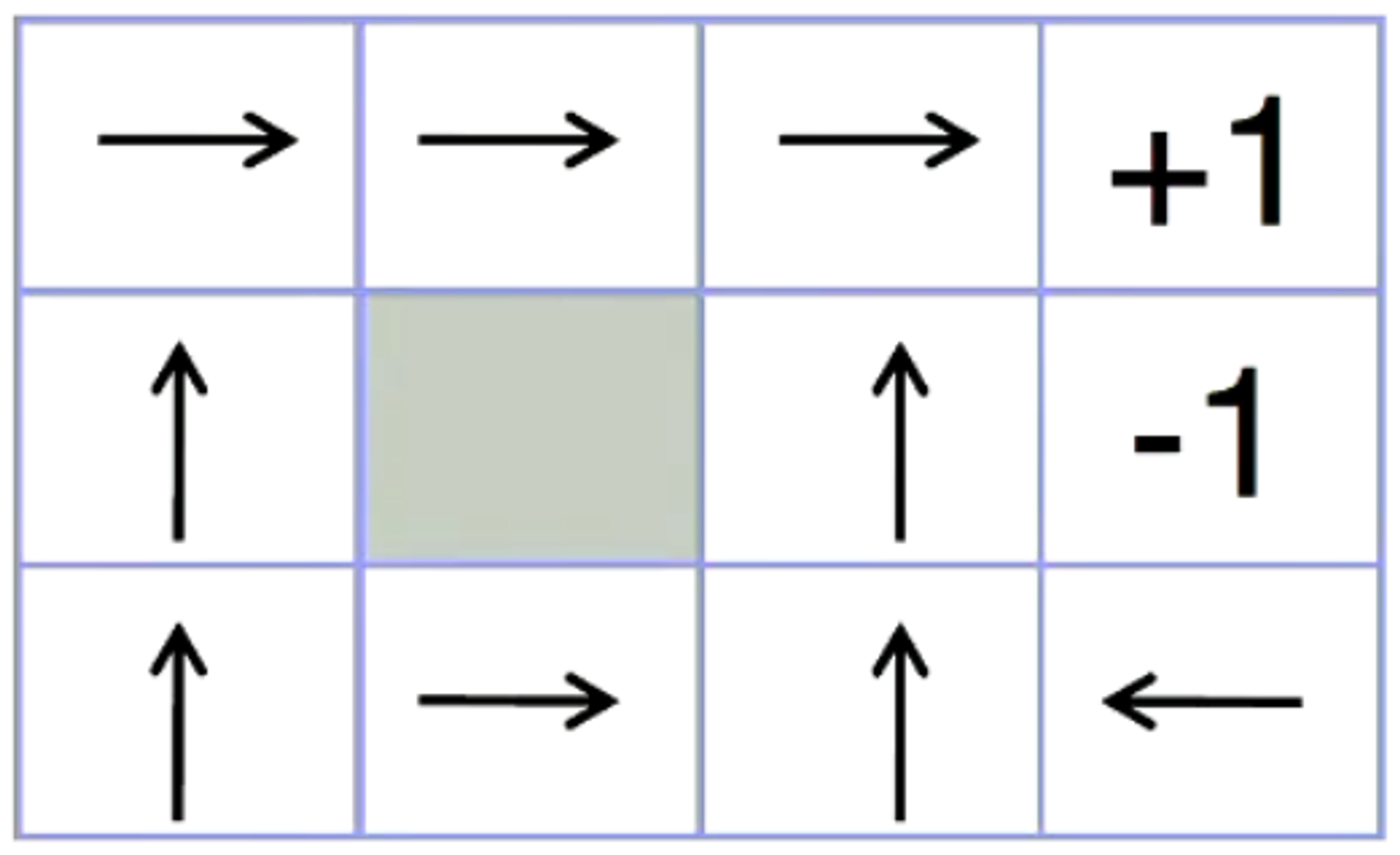
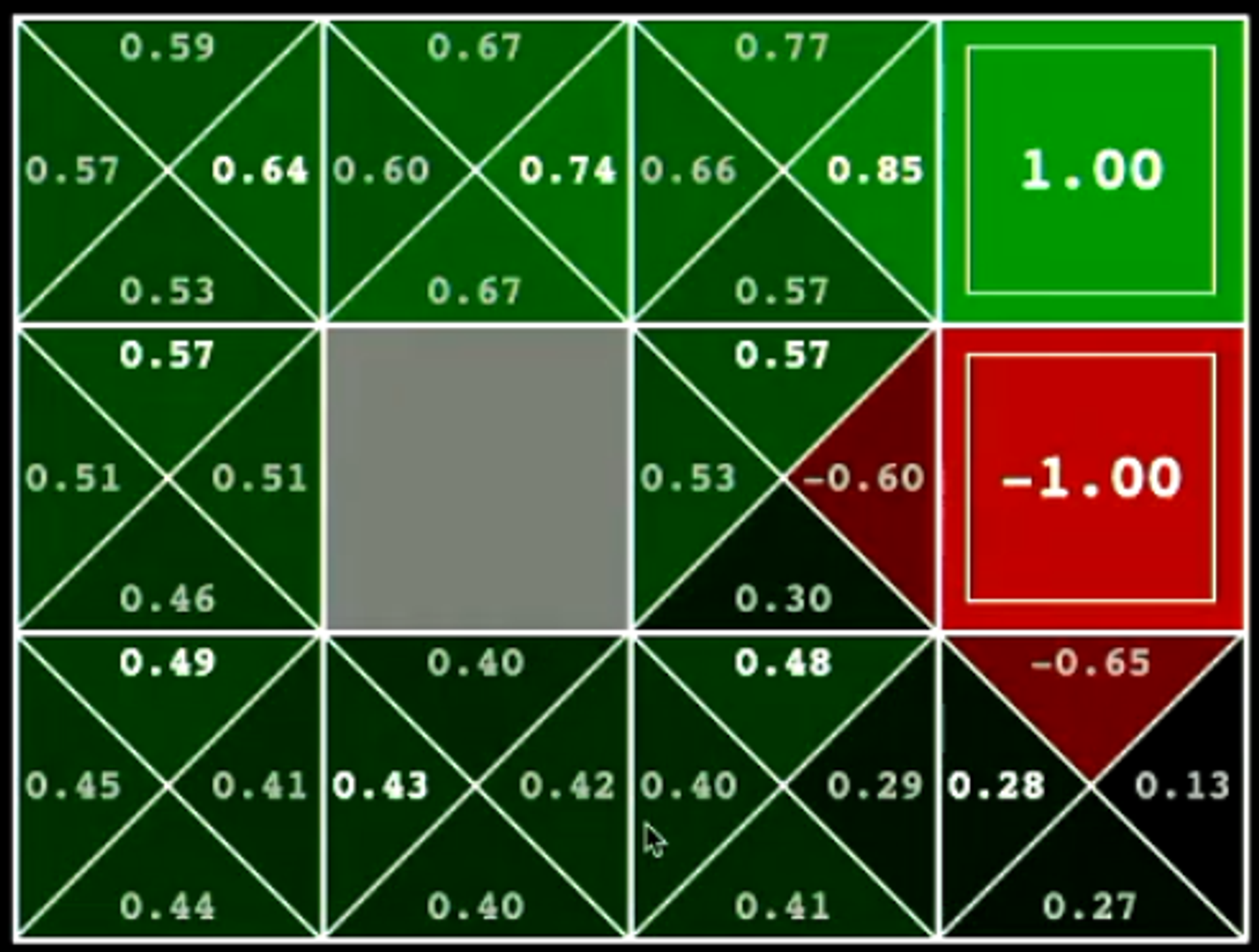
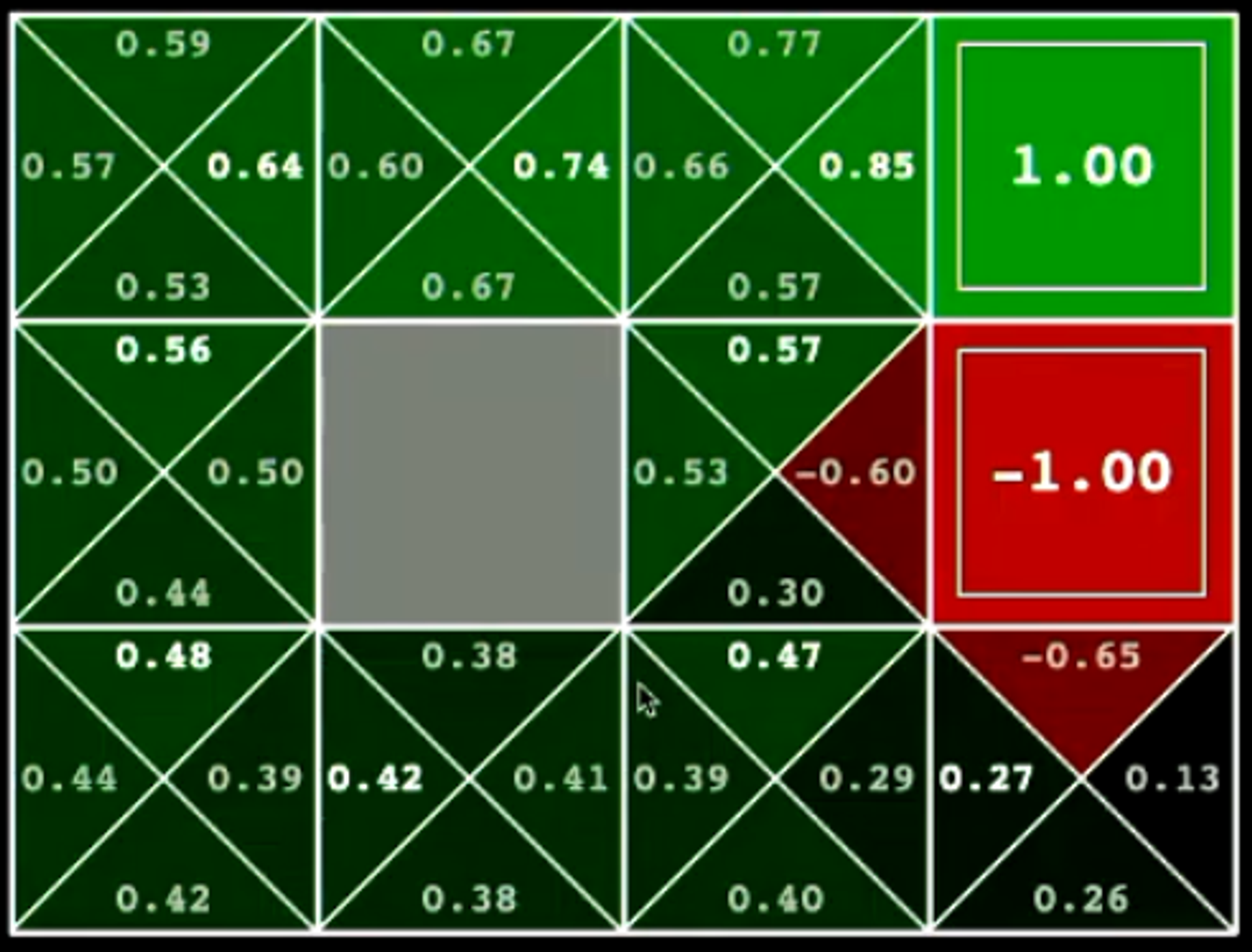
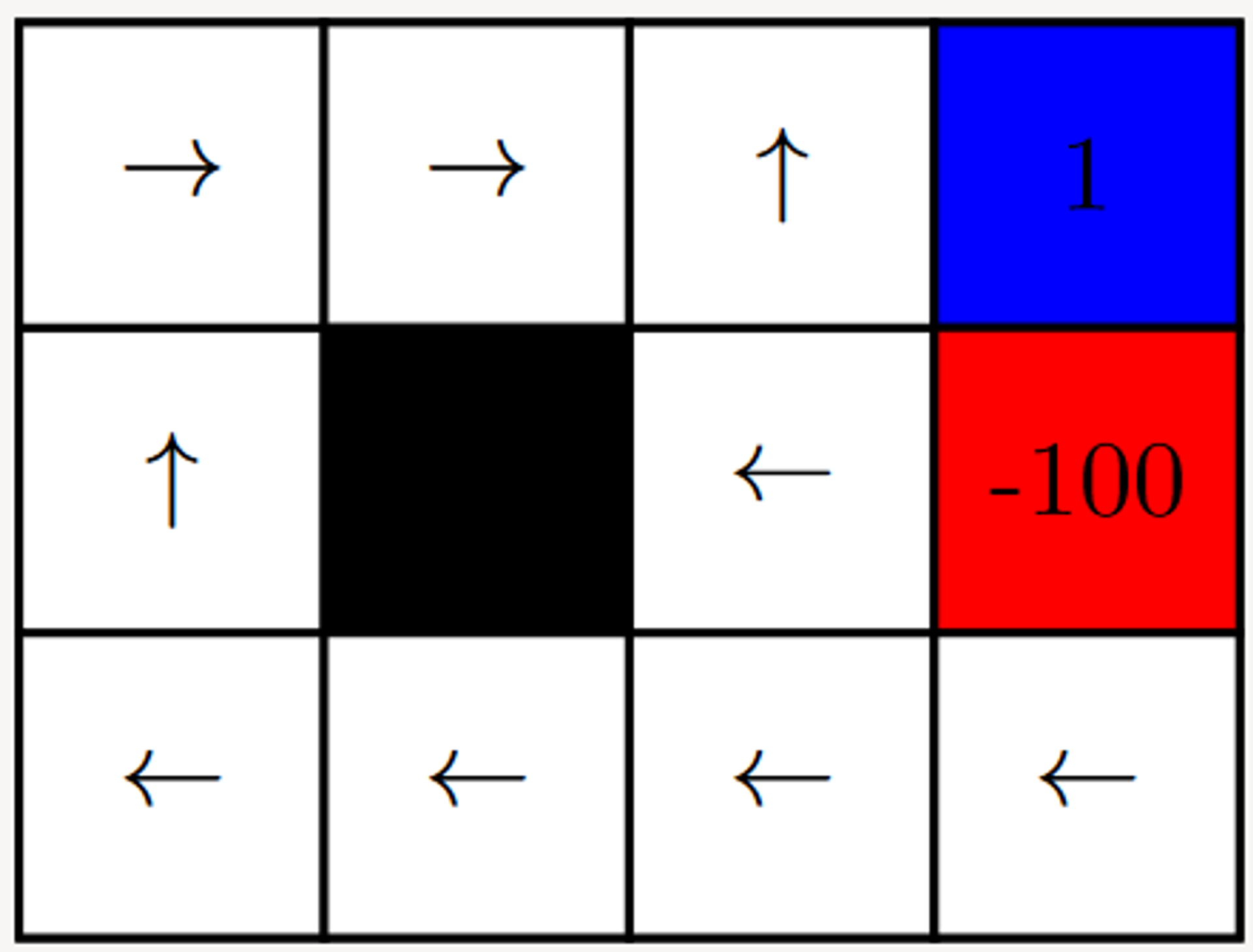
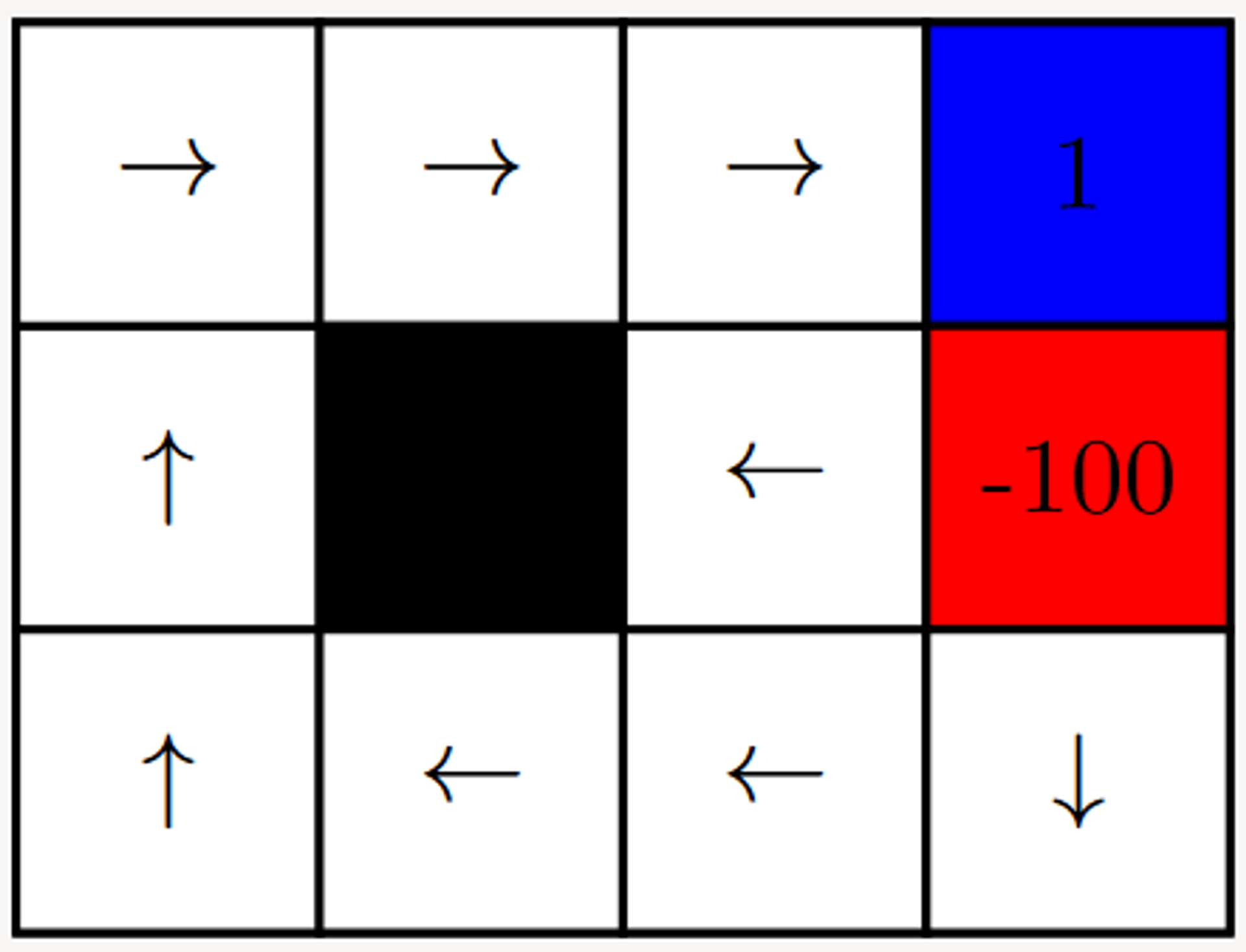
Step 10 - 10 Iterations
When we increase the number of iterations to 10, we immediately observe that the values have started to converge to the final policy (we can observe that the arrows seem to be correctly indicating the optimal solution for each state).
The Q-Values of the model further indicate the weights for each action in each state - these values determine which action is most beneficial to perform in each state.
When the agent is run on this environment, provided with the following information, it solves the environment in the most efficient way possible - it is an optimal solution.
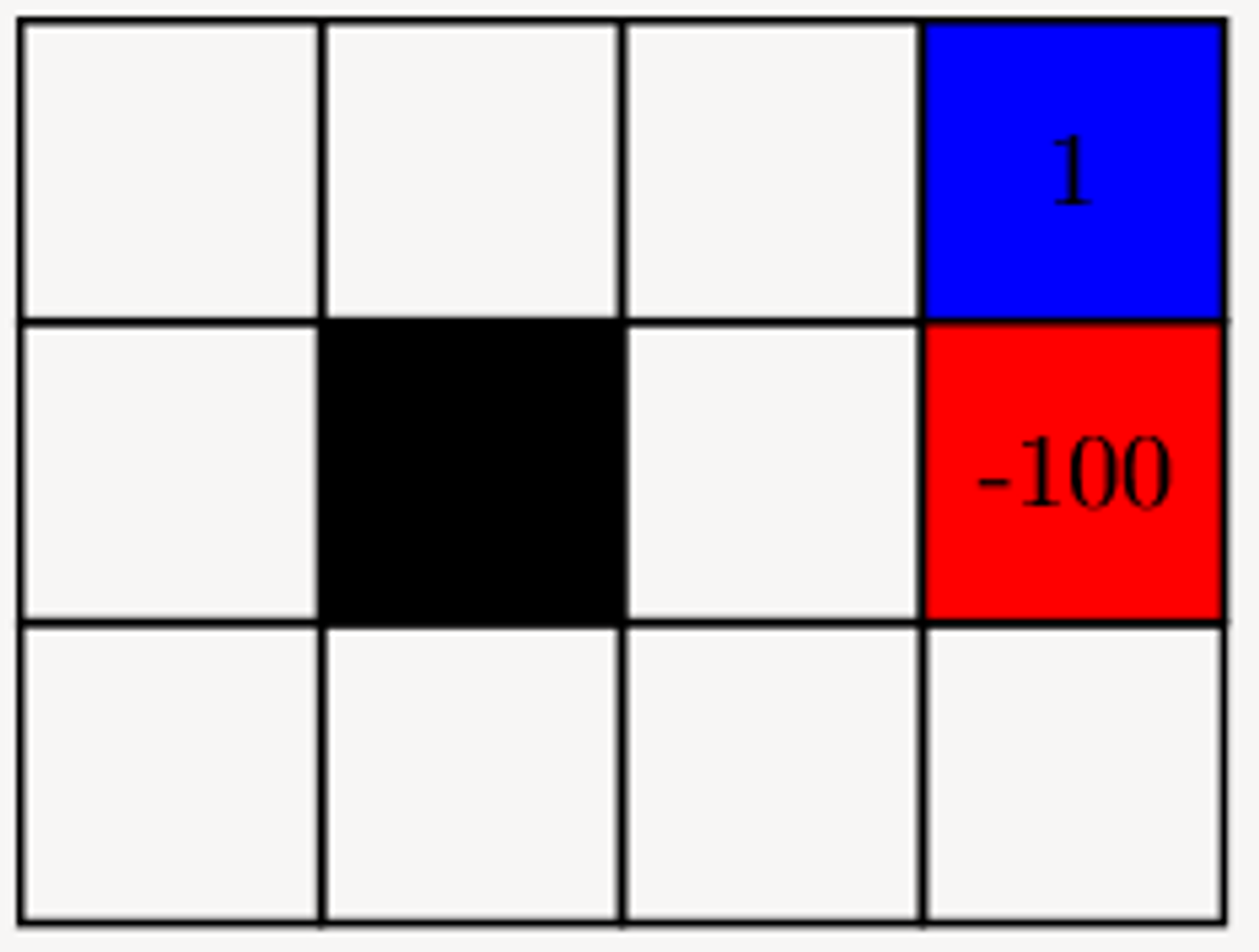
4.2.1 - Grid World Environment - Working
Suppose we have a grid world environment, with a layout as shown in the figure on the right.
Let γ=0.9
actions={up, down, left, right}
→ Move successfully with p=0.7
→ Otherwise, move perpendicular to intended direction (each direction p=0.15)
If the agent hits a wall, it says exactly where it is (state does not change)
Note that the value of the next time instant Vi+1 depends on the value of the previous time instant Vi
Note that this is the transition function, sometimes denoted T(s,a,s′)
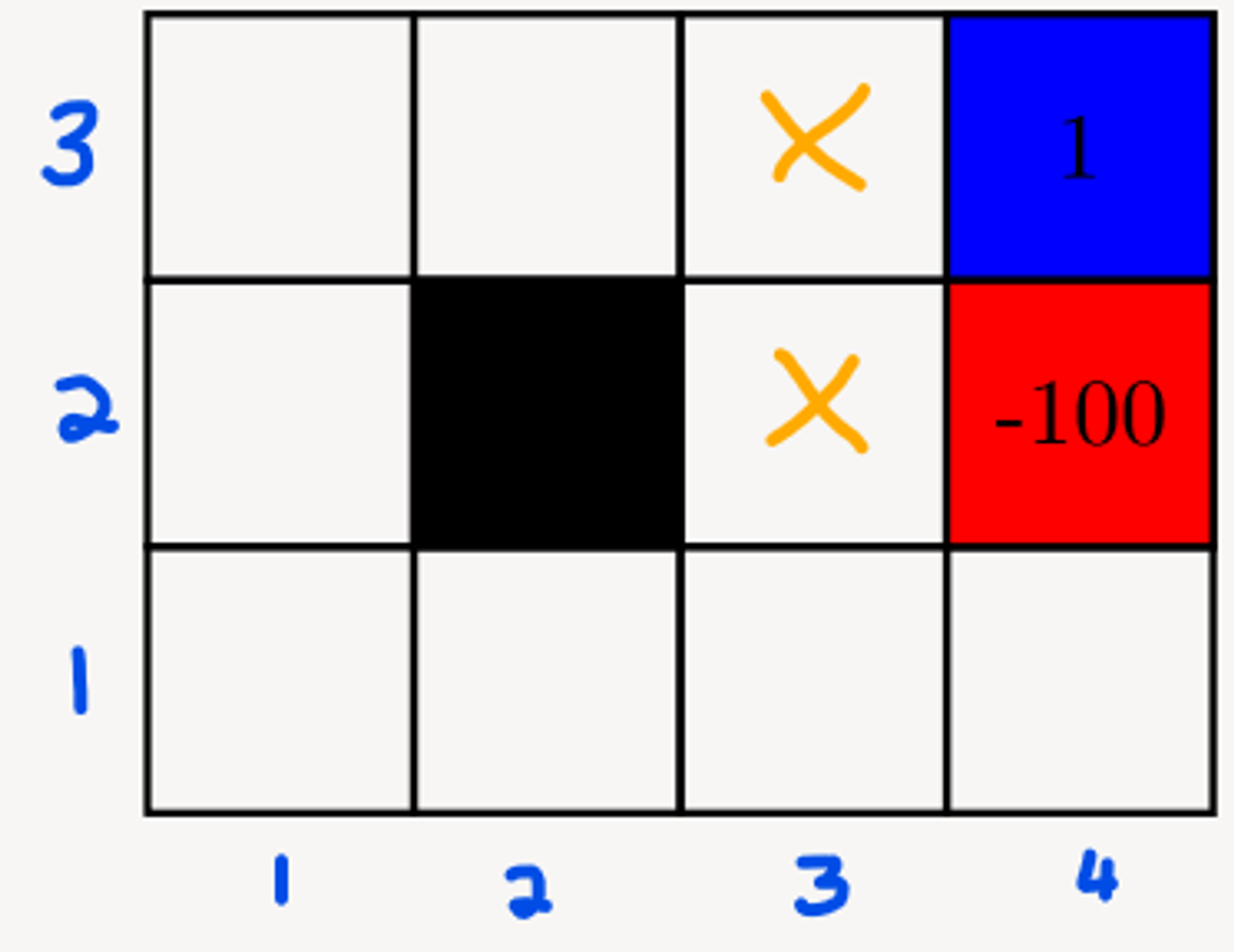
Now, we update the cells in the grid world with the probabilities from the first iteration (looking one step ahead).
Suppose we enumerate the cells as shown in the right
When looking at the cells from which the agent can move from and have a change in reward by moving from one step, note that the only two cells that will be updated are indicated in yellow - (2,3)&(3,3)
From this, and the information about the determinism of moving into a particular state, we can create a state transition table, which describes the probability of ending up in a particular state, when moving from an initial state.
Start (s) / End( s’)(2,3)(3,3)(2,4)0.70.15(3,4)0.150.7(1,4)0.15(3,3)0.15 (Transition Table for action RIGHT)
As shown in the formula V(s)=... before, we want to multiply the value of the transition function (which can be obtained from this transition function) with the reward and discounted future value (γ×Vi(s′)).
For State (3,3), we have:
{(3,3)→(2,4)}:(0.15×−1){(3,3)→(3,4)}:(0.7×1){(3,3)→(3,3)}:(0.15×0)Vi+1=γ×right∑=(0.15×−1)+(0.7×1)=0.7−0.15=0.9×(0.55 [For moving in the Right] direction+{Repeat for the other actions}......)
4.3 - Asynchronous Value Iteration
This was quite a computationally expensive operation
The agent doesn't need to sweep through all the states, but can update the value functions for each state individually
Do update assignments to the states in any order we want, even randomly
This converges to the optimal value functions, if each state is visited infinitely often in the limit
We update the policy in every step, as opposed to running the model until convergence then updating the policy
Leads to less computational complexity in some cases.
Solving Vπi(s) means finding a solution to a set of ∣S∣ linear equations with ∣S∣ unknowns as shown earlier.
Note The Week 7 lecture slides state that there are ∣S∣×∣A∣ linear equations with ∣S∣×∣A∣ unknowns. This is incorrect as clarified in the Week 8 Lecture thread.
5.1.1 - Policy Iteration Example - Grid World Environment
Observe that in this example, we take much fewer steps as compared to Value Iteration.
Set the policy to an arbitrary value for every state.
Solve for Vπi for each state
Choose the action that will optimise the value for each state and update the policy.