We update the policy in every step, as opposed to running the model until convergence then updating the policy
Leads to less computational complexity in some cases.
Solving Vπi(s) means finding a solution to a set of ∣S∣ linear equations with ∣S∣ unknowns as shown earlier.
1.5 - Value Iteration vs Policy Iteration
Value Iteration
Includes finding optimal value function, then one policy extraction after convergence.
Every iteration updates both the values (and implicitly the policy since taking the maximum over the actions implicitly recalculates it)
Simpler to implement
Policy Iteration
Includes policy evaluation + policy update / improvement repeated iteratively until the policy converges
Police evaluation Perform several passes that update utilities with a fixed policy (each pass is fast because we consider only one action, not all of them)
Policy update is slow like a value iteration pass
More complicated
In practice, converges faster than VI - policy converges much faster than the values converge
i=13 for Policy Iteration
i≈100 for Value Iteration
Both are Dynamic Programming methods (Dynamic Programming methods - where you decompose the problem into small parts that can be solved recursively)
1.6 - Modified Policy Iteration
Set π[s] arbitrarily
Set Q[s,a] arbitrarily
Repeat forever:
Repeat for a while
Select state s, action a
Q[s,a]←∑s′P(s′∣s,a)(R(s,a,s′)+γQ[s′,π[s′]])
π[s]←argmaxaQ[s,a]
until πi(s)=πi−1(s)
1.7 - Special Case: Finite Horizon MDPs
For finite horizon MDPs, can use dynamic programming or "backwards induction" to compute the optimal value function:
Start from the goal state and propagate values backwards through the transition function
At each decision node, set the value function equal to
So far, we assumed we can store the values of all states, and update the value of each state sufficiently often
Infeasible in large state spaces, especially in a continuous state space
Polynomial time algorithm for large state space is still not fast enough
Not all states are relevant
Focus Bellman Update on relevant states only
More compact policy representation
2.1.1 - Policy Representation
If state space is extremely large, we usually run out of memory
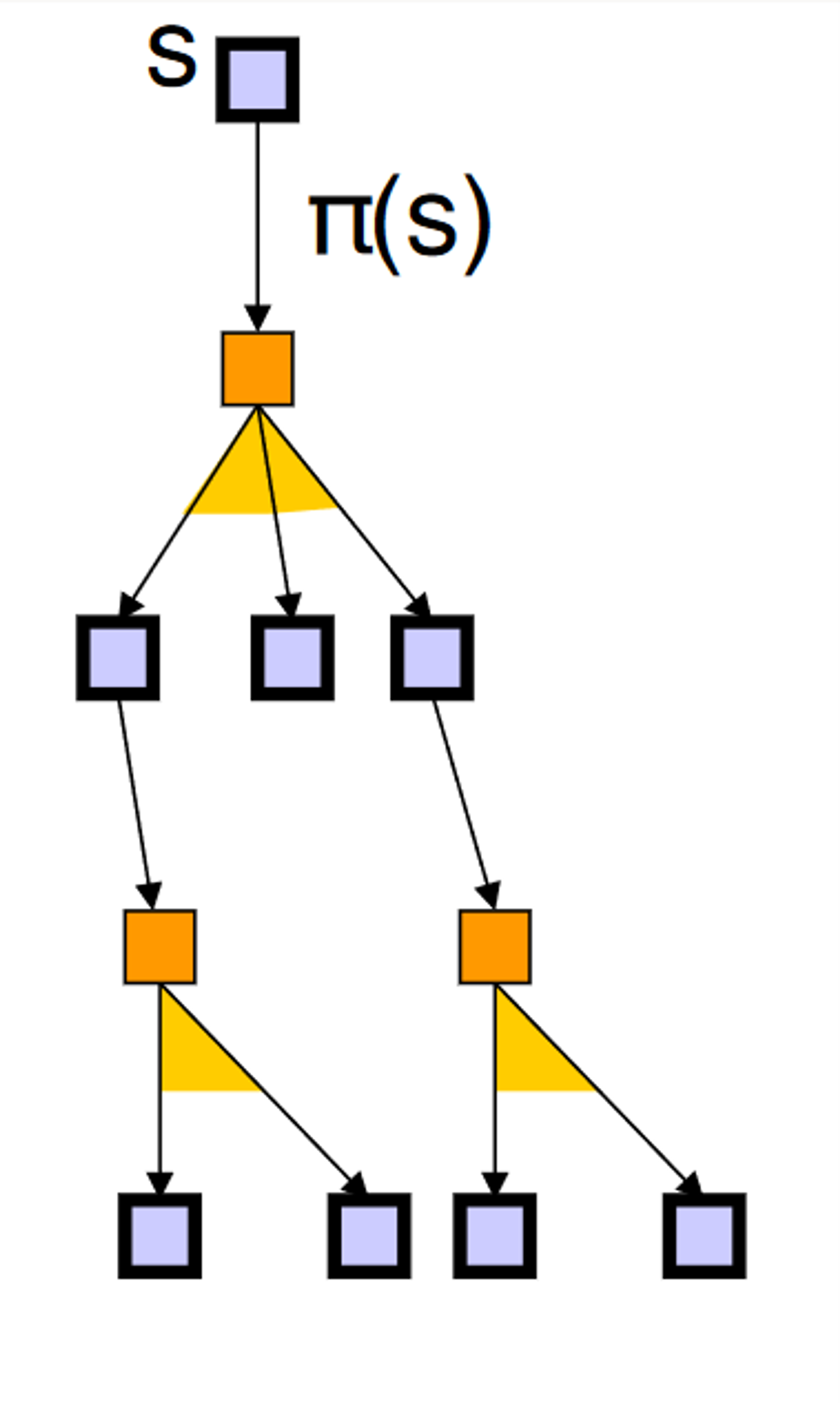
Rather than mapping from every state, we can use an AND-OR tree for policy representation
Root = initial state
Don't care about states that are unreachable from the initial state
Can define a parametric function to define the value function
2.2 - Computing the Policy Online
Problems with offline policy
Large state space and action spaces
Even a single backup operation can be expensive
Computationally expensive in time and memory
Solutions
Interleave policy computation with using the policy (online Policy iteration)
Focus on finding the optimal policy for the present state only (similar to asynchronous Value Iteration)
In general, relax the optimality requirement to approximately optimal.
2.3 - Real Time Dynamic Programming (RTDP)
Repeat until the planning (offline) time runs out:
Simulate the greedy policy from the start state until a goal state is reached
Perform Bellman backup on visited states
Greedy policy Taking the action that maximises the value
RTDP(Initial State s0,Goal State G):
Repeat until time runs out:
s=s0
While (s is not in G)
agreedy=argmaxa∈AQ(s,a)
V(s)=Q(s,agreedy)
s′=sampleFrom(P(s′∣a,s)) and set s=s′
Benefits: RTDP converges to optimality as num_iterations→∞
Drawbacks: May perform backup at state s repeatedly even when the value of s has converged to the optimal value
2.4 - Labelled RTDP
Labelled RTDP is an improvement on RTDP
Check if the value of a state can no longer improve (i.e. the isSolved function in the following algorithm)
If the value of a state s and all of its descendants (that have been visited) change less than a small value ϵ, label s as solved.
That is, we no longer have to update a state if it is solved.
RTDP(Initial State s0,Goal State G):
Repeat until s0 is solved
s=s0
While (s is not solved)
agreedy=argmaxa∈AQ(s,a)
V(s)=Q(s,agreedy)
s′=sampleFrom(P(s′∣a,s)), add s′ to a list L and set s=s′
For all states s in L, if isSolved(s), label s as solved.
3.0 - Monte Carlo Tree Search (MCTS)
Alternative Approach Given a starting state, learn the (local) value model well enough to take an action in the current state, take an action, then estimate the value of the next node.
V∗(s)=maxas′∑P(s′∣a,s)[R(s,a,s′)+γV∗(s′)]
Combines tree search and Monte Carlo
Monte Carlo sampling is a well known method for searching through a large state space.
In MDPs, Monte Carlo tree search does this by making use of a generative model, or simulator of the system under control
Exploiting Monte Carlo in sequential decision making was first successfully demonstrated by Kocsis and Szepesvari, 2006 - a relatively recent development.'
MCTS can be used as a planning method (offline) or as a learning method (online)
In the online case, we can use simulations to learn the local model, then take an action in the real world and find out what state we actually ended up in next.
3.1 - Monte Carlo Methods
Monte Carlo Simulation A technique that can be used to solve a mathematical or statistical problem using repeated sampling to determine the properties of some phenomenon (or some behaviour as shown in this demonstration)
Monte Carlo Planning Compute a good policy for an MDP by interacting with an MDP simulator
3.2 - Monte Carlo Tree Search (MCTS)
MCTS is used for sequential decision making, over different states:
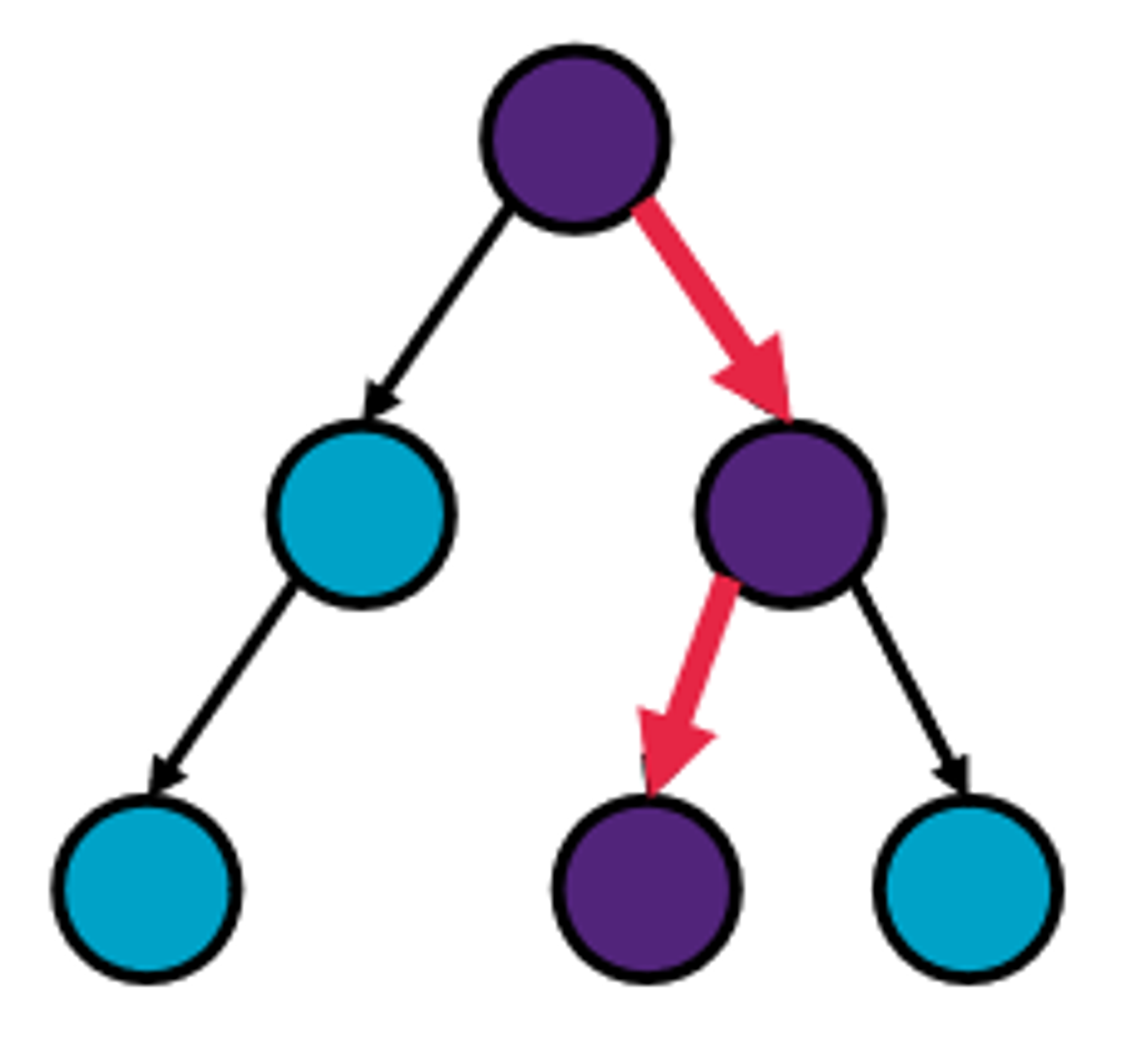
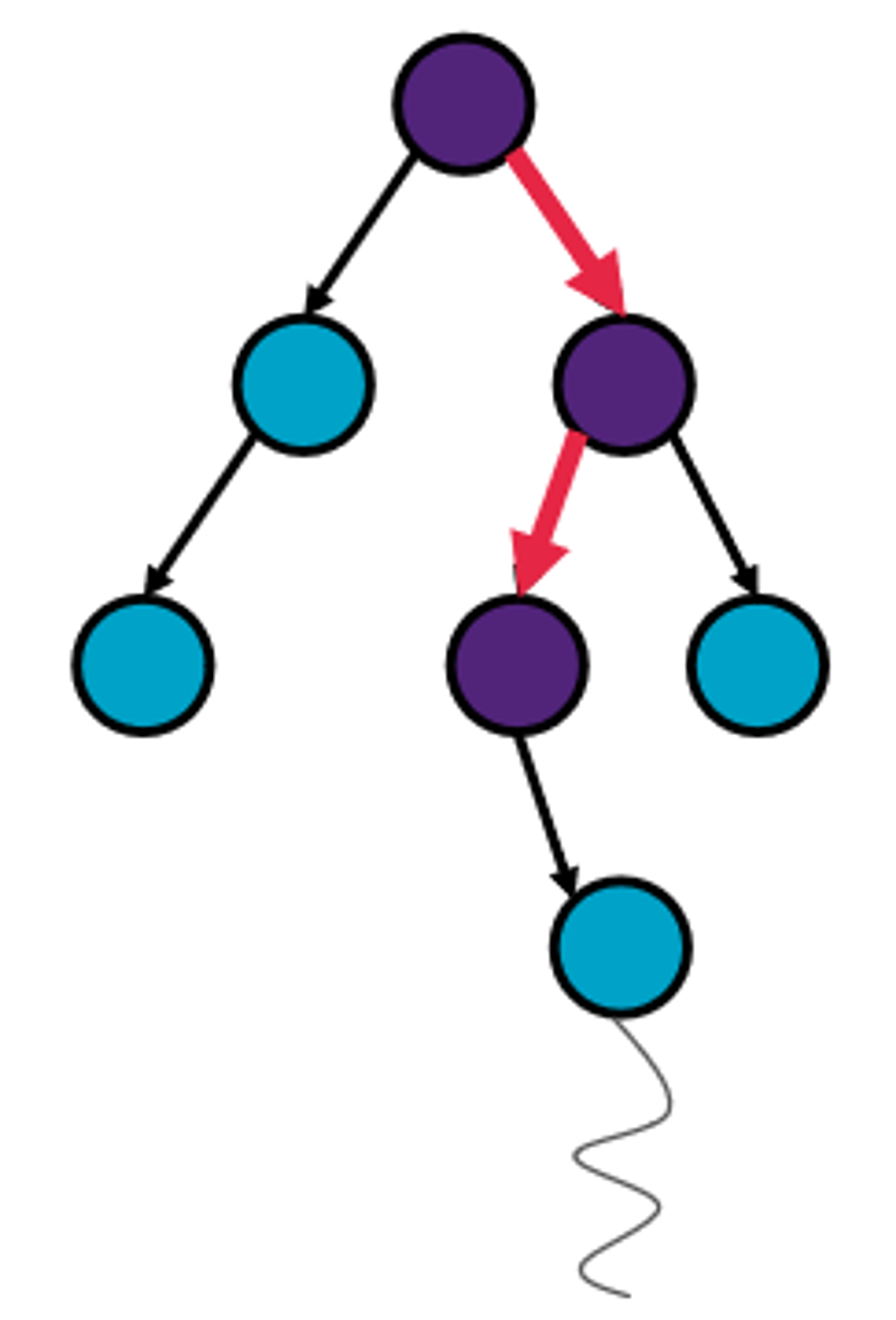
Gradually grow the search tree
Two types of tree nodes (and and-or trees)
Decision nodes (action selection) - the algorithm selects (recursively)
Chance nodes (world selection) - the worlds selects an outcome (in the case of MDPs, these are based on known probabilities)
Returned solution - path (action from root) visited the most often
Bandit Phase Select action from the existing tree
Add Node Grow a leaf on the fringe of the search tree
Random Phase / Roll-Out Select next action to expand from the fringe
Evaluate Compute instant reward
Back-Propagate Update information in visited nodes, (like is done in dynamic programming for finite horizon MDPs)
3.2.1 - Model-Based Monte Carlo
The goal is to estimate the MDP transition function P(s′∣a,s) and reward R(s,a,s′)
Don't explicitly need to have P(s′∣a,s) or R(s,a,s′) - just run the simulation and observe the result.
Transitions - P^(s′∣a,s)=# times (s,a) occurs# times (s,a,s′) occurs
Rewards - R(s,a,s′)=r∈(s,a,r,s′)
3.3 - MCTS Example of Steps
Build the search tree based on the outcomes of the simulated plays
Iterate over the 4 main components
Selection Choose the best path
Expansion When a terminal node is reached, add a child node
Simulation Simulate from the newly added node to estimate its value
Backpropagation Update the value of the nodes visited in this iteration
The transition function is treated as a black box in MCTS
3.3.1 - MCTS for MDP
The value Q(s,a) is the average total discounted reward over the simulations that start from state s and perform action a as its first action
That is, Q(s,a) gives 'how good' a given (state, action) combination is.
Does not need the exact transition function and reward model
Only need a simulator
Computes a good policy by interacting with the simulator.
3.4 - Commonly used MCTS for MDP
Build the search tree based on the outcomes of the simulated plays.
Iterate over the four main components:
Selection: Choose the best path
Expansion: When a terminal node is reached, add a child node
Simulation: Simulate from the newly added node n, to estimate its value
Backpropagation: Update the value of the nodes visited in this iteration.
3.4.1 - Node Selection
Multi-armed bandit to select which action to use
In general, use a method called Upper confidence bound
Choose an action a to perform at s as:
πUCT(s)=argmaxa∈AQ(s,a)+cn(s,a)ln(n(s))
Exploitation Approximation based on simulations, not the actual / final value.
Exploration Try to find something that that is better than what we're doing now.
$argmax_{a \in A}$ Choose the action that maximises the reward
$c$ A constant indicating how to balance exploration and exploitation
The value of this constant needs to be decided by trial and error.
$n(s)$ The number of times node s has been updated.
$n(s,a)$ The number of times the out-edge of s with label a has been visited.
MCTS + UCB is often called Upper Confidence Bound for Trees (UCT)
Additional Exploration component as compared to RTDP.
3.4.2 - Simulation
Often called rollout
Essentially, a way to estimate the optimal value of the newly added state
In practice, how we do this is very important for the performance of the algorithm
Use a heuristic e.g. greedy, solution of deterministic case
Greedy - choose best action with respect to immediate reward.
Important for performance.
3.4.3 - Backpropagation
Essentially, updating the Q values
Q(s,a)=N(s,a)+1Q(s,a)×N(s,a)+q=total# times visited×value - Compute the Q value using the Monte Carlo approximation.
N(s)=N(s)+1
N(s,a)=N(s,a)+1
4.0 - Example of MCTS
5.0 - Value Function Approximation (VFA)
5.1 - Large Scale Problems
MDPs and Reinforcement learning should be used to solve large-scale problems. For example:
Backgammon: 1020 states - 1020×num_actions×1020
Chess: 1030 to 1040 states
Computer Go: 10170 states
Quad-copter, bipedal robot: Enormous continuous state space
Tabular methods (that perform computation on every explicit state) cannot handle this.
If the state space is large, several problems arise
The table of Q-value estimates can get very large
Q-value updates can be slow to propagate.
High-reward states can be hard to find
State space grows exponentially with feature dimension.
5.2 - MDPs and Reinforcement Learning with Features
Usually we don't want to reason in terms of states, but in terms of features
In state-based methods, information about one state cannot be used by similar states
If there are too many parameters to learn, it takes too long.
Express the value function as a function of the features
Most common is a linear function of the features
5.3 - Linear Value Function Approximation
Learn a reward/value function as a linear combination of features
We can think of feature extraction as a change of basis
For each state encountered, determine its representation in terms of features
Perform a Q-learning update on each feature
Value estimation is a sum, over the state's features
A linear function of variables x0,...,xn is of the form
fWˉ(x1,...,xn)=w0+w1x1+...+wnxn
where Wˉ=(w0,w1,...,wn) are weights (and by convention x0=0)
Additionally, ∑i=0nwi=1
weights signify how important each feature is - convert each feature into a value
5.4 - Q-Learning with Linear Value Function Approximation
Given $\gamma =$ discount factor and $\eta=$ step size
Assign weights $\bar{w}=(w_0, ..., w_n)$ arbitrarily
Observe the current state, $s$
**repeat** each episode, until convergence:
select and carry out action a
observe reward r and state s'
select action a' (using a policy based on $Q_{\bar{w}}$ which is a Q-table indexed by features)
let $\delta=r+\gamma Q_w(s', a')-Q_w(s,a)$
for $i=0$ to n - update the weights as follows.
$w_i=w_i+\eta\delta F_i(s,a)$
$s\leftarrow s'$
Intuition: This is performing gradient descent across all features, effectively adjusting feature weights to reduce the difference between the sampled value and the estimated expected value.
5.5 - Advantages and Disadvantages of VFAs
Advantages
Dramatically reduces the size of the Q-table
States will share many features
Allows generalisation to unvisited states
Makes behaviour more robust - making similar decisions in similar states
Handles continuous state space
Disadvantages
Requires feature selection - this often must be done by hand
Restricts the accuracy of the learned rewards - learned reward is not precisely for that state.
The true reward function may not be linear in the features.
5.6 - General VFAs
In general, VFA can replace tables with a general parameterised form
Next Time:
Online methods weren't planning but learning → reinforcement learning
There was an MDP, but using learning to estimate the Value, and it wasn't solved with just computation
In reinforcement learning:
Exploration You have to try unknown actions to get information
Exploitation Eventually you have to use what you know
Regret Even if you learn intelligently, you make mistakes
Sampling Because of chance, you have to try things repeatedly
Difficulty Learning can be much harder than solving a known MDP