Gather data by interacting with the world, given a sequence of experiences:
state, action, reward, state, action, reward, ...
The agent has to choose its action as a function of its history
At any time it must decide whether to:
Explore to gain more knowledge - try performing a new action
Exploit knowledge it has already discovered - continue to perform an action that we know works well
1.6 - Why is Reinforcement Learning Hard?
What actions are responsible for a reward may have occurred a long time before the reward was received.
The long-term effect of an action depends on what the agent will do in the future
The explore-exploit dilemma: at each time should the agent be greedy or inquisitive?
1.6.1 - Reinforcement Learning Approaches
Model-Based vs Model-Free - What is being learned?
Model-Based
Use data to learn the missing components of the MDP problem, i.e. Transition & Reward functions
Once we know the Transition & R, solve the MDP problem
Indirect learning, but generally most efficient use of data.
Model-Free
Use data to learn the value function & policy directly
Direct learning, generally not the most efficient use of data, but usually fast.
Passive vs Active - How is the data being generated?
Passive Fixed policy
❗ Learn the transition and reward function through passive observation
The agent observes the world by following the policy OR given a data set (e.g. from video), the agent observes to learn value function or the model (Transition and Reward functions)
Active Classical Reinforcement Learning Problem
❗ Learn the transition and reward function through performing action and observing the response
The agent selects what action to perform, and the action performed determines the data it receives, which then determines how fast the agent converges to the correct MDP model
Exploration vs exploitation dilemma in active reinforcement learning approach.
Note that we can have a combination of the two.
1.7 - Reinforcement Learning - Main Approaches
Approach One Learn a model consisting of (1) state transition function P(s′∣a,s), (2) reward function R(s,a,s′) and solve this as a MDP.
Approach Two Learn Q∗(s,a) and use this to guide the action chosen - use this function to determine how good the (s,a) pair is.
Approach Three Search through a space of policies (controllers)
In all of these cases, we face the problem of exploration vs exploitation
2.0 - Exploration vs Exploitation - Multi-Armed Bandits
2.1 - Exploration vs Exploitation
All the methods that follow will have some convergence condition like "assuming we visit each state enough", or "taking actions according to some policy"
A fundamental question - If we don't know the system dynamics, should we take actions that will give us more information, or exploit current knowledge to perform as best we can?
If we use a greedy policy, bad initial estimates in the first few cases can drive policy into sub-optimal region, and never explore further
💡 Instead of acting according to the greedy policy, act according to a sampling strategy that will explore state-action pairs until we get a "good" estimate of the function.
2.2 - Multi-Armed Bandit Problem
🧠 Assumption:
1. The choice of several arms / machines
2. Each arm pull is independent of other arm pulls
3. Each arm has a fixed, unknown average payoff
Which arm has the best average payoff? How do we maximise the sum of rewards over time?
We can determine the average payoff from each arm through sampling.
Consider a row of three poker machines.
R(win)=1 for all machines
P(A,win)=0.6,P(B,win)=0.55,P(C,win)=0.4
The expected utility theory tells us that A is the best arm, but we don't know that!
We want to explore all arms BUT if we explore too much, we may sacrifice the reward we could have gotten
We want to exploit promising arms more often, BUT if we exploit too much, we can get stuck with sub-optimal values because of a lack of exploration
We want to minimise regret → loss from playing non-optimal arm
Need to balance between exploration and exploitation
2.4 - Exploration Strategies
An exploration strategy is a rule for choosing which arm to play at some time step t given arm selections and outcomes of previous trials at times 0,1,...,t−1 (also called a policy in the MAB literature, but we'll reserve that word for MDP/RL state-action policies)
ϵ-greedy strategy choose random action with probability ϵ and choose a best action with probability 1−ϵ
Choose ϵ<0.5 (so greater probability of choosing best action)
Softmax/Boltzmann Strategy In state s, choose action a with probability ∑aeQ(s,a)/τeQ(s,a)/τwhere τ>0 is the temperature coefficient
(The term on the bottom sums to 1?)
EXP3 / Exponential-Weight Algorithm for Exploration and Exploitation is an algorithm used in adversarial cases.
Optimism in the face of uncertainty - Initialise Q to values that encourage exploration
Upper Confidence Bound Take into account average + variance information
2.4.1 - Epsilon-Greedy Exploration
🧠 If we are just considering exploitation and exploration, we *do the thing that rewards you most of the time, and sample other paths with some small probability*
Assign a weight to each sampling strategy
Start with equal weight for each strategy
Strategy with the highest weight is selected with probability (1−ϵ).
The rese are selected with probability ϵ/N where N is the number of strategies available
A typical value might be ϵ=0.1
2.4.2 - Upper Confidence Bound
UCB1 algorithm (Auer et al, 2002)
Pull every arm k≥1 times, then
at each time step, choose arm i that maximises UCB1 formula for the upper confidence bound
UCB1i=vi^+cniln(N)
vi^ is the current value (mean) estimate for the arm i
C is the tunable parameter
N is the total number of arm pulls
ni is the number of times arm i has been pilled
vi^ is the exploitation term
cniln(N) is the exploration term
UCB1i=vi^+cniln(N)
A higher estimated reward vi^ is better (exploit)
Expect "true value" to be in some confidence interval around vi
Confidence interval is large when the number of trials ni is small, shrinks in proportion to ni
High uncertainty about move → larger exploitation term
Sample more if number of trials is much less than the total number of trials.
3.0 - Model-Based Reinforcement Learning
3.1 - Asynchronous Value Iteration for MDPs (Storing Q(s,a))
If we knew the model, we would have:
A reward function R(s,a,s')
Transition function P(s'|s,a) or T(s,a,s')
And we could use value iteration to compute the optimal policy:
🧠 Initialise a table of Q values, $Q(s,a)$ arbitrarily
Repeat forever:
Select state s, action a
Q(s,a)←∑s′P(s′∣s,a)(R(s,a,s′)+γmaxa′Q(s′,a′))
In this case, we store the Q values of everything (all state, action pairs)
The catch is, we don't know P(s′∣s,a) or R(s,a,s′)
3.1.1 - Unknown Transition and Reward Function
When we don't have P(s′∣s,a) or R(s,a,s′), there is a simple approach: just estimate the MDP from the observed data
Suppose the agent acts in the world (according to some policy) and observes experience:
s0,a0,r0,s1,a1,r1,...,sn,an,rn
From the empirical estimate of the MDP via the counts:
P(s′∣s,a)=∑i=0mI(si=s,ai=a)∑i=0mI(s1=s,a1=a,si+1=s′)=# times action a performed on state s# times moved from s→s′ by performing a
R^(s)=∑i=0mI(si=s)∑i=0mI(si=s)ri=# times in state s# times in state s×immediate reward=average reward for state s
Where I(⋅) is an indicator function, =1 if the condition is true
Now solve the MDP ⟨S,A,P^,R^⟩ e.g. using value iteration
3.3.2 - Model-Based Reinforcement Learning
Model-Based Reinforcement Learning will converge to correct MDP (and hence correct value function / policy) given enough samples of each state
How can we ensure that we get the "right" samples? (This is a challenging problem for all methods we present here)
Advantages (informally) Makes efficient use of data
Disadvantages Requires that we build the actual MDP models, which is not much help if the state space is too large.
Building MDP models → Requires constructing the reward function and transition function
4.0 - Q-Learning
4.1 - Temporal Differences
Suppose we have a sequence of values v1,v2,v3,...
and we want a running estimate of the average of the first k values
Ak=kv1+⋅⋅⋅+vk
Suppose we know Ak−1 and a new value vk arrives
Ak=kv1+...+vk−1+vk
kAk=v1+...+vk−1+vk
Ak=kk−1Ak−1+k1vk
v1+...+vk−1=Ak−1×(k−1)
Let αk=k1
Ak=(1−αk)Ak−1+αkvk=Ak−1+αk(vk−Ak−1) (1) - Temporal Differences formula
Note that in this formula, the previous term is given by Ak−1 and the next term as αk(vk−Ak−1).
The new term vk−Ak−1 is also known as the temporal difference error / TD-error - how different the new value vk is from the old prediction Ak−1
At this step, we update the previous estimate Ak−1 by the constant αk multiplied by the TD error vk−Ak−1
That is, we update the estimate Ak−1 with the difference between the estimate and the value observed vk
Often we use this update with α fixed
We can guarantee convergence to average if
∑k=1∞(ak)=∞
∑k=1∞αk2<0
e.g. if αk=k−1 or αk=a(b+k)−1
4.2 - Q-Learning Implementation
With known reward and state-transition functions:
Q∗(s,a)=∑s′P(s′∣a,s)(R(s,a,s′)+γmaxaQ∗(s′,a))
Idea Store Q(state,action) in a table, update this as in asynchronous value iteration, but using experience, (empirical probabilities and rewards).
Suppose the agent has an experience (s,a,r,s′)
This provides one piece of data to update Q(s,a)
An experience (s,a,r,s′) provides a new estimate for the value of Q∗(s,a)
TD Target=r+γmaxa′Q(s′,a′)Q^∗(s,a)=r+γmaxa′Q(s′,a′)=reward+discounted future Q(s,a) value
Note: We potentially know nothing about the environment, but we can initialise the Q-values to all zeros.
This can be used in the Temporal Differences formula:
Q^(s,a)←Q^(s,a)+α(r+γmaxa′Q^(s′,a′)−Q^(s,a))
Therefore, based on empirical values, we can update our Q value.
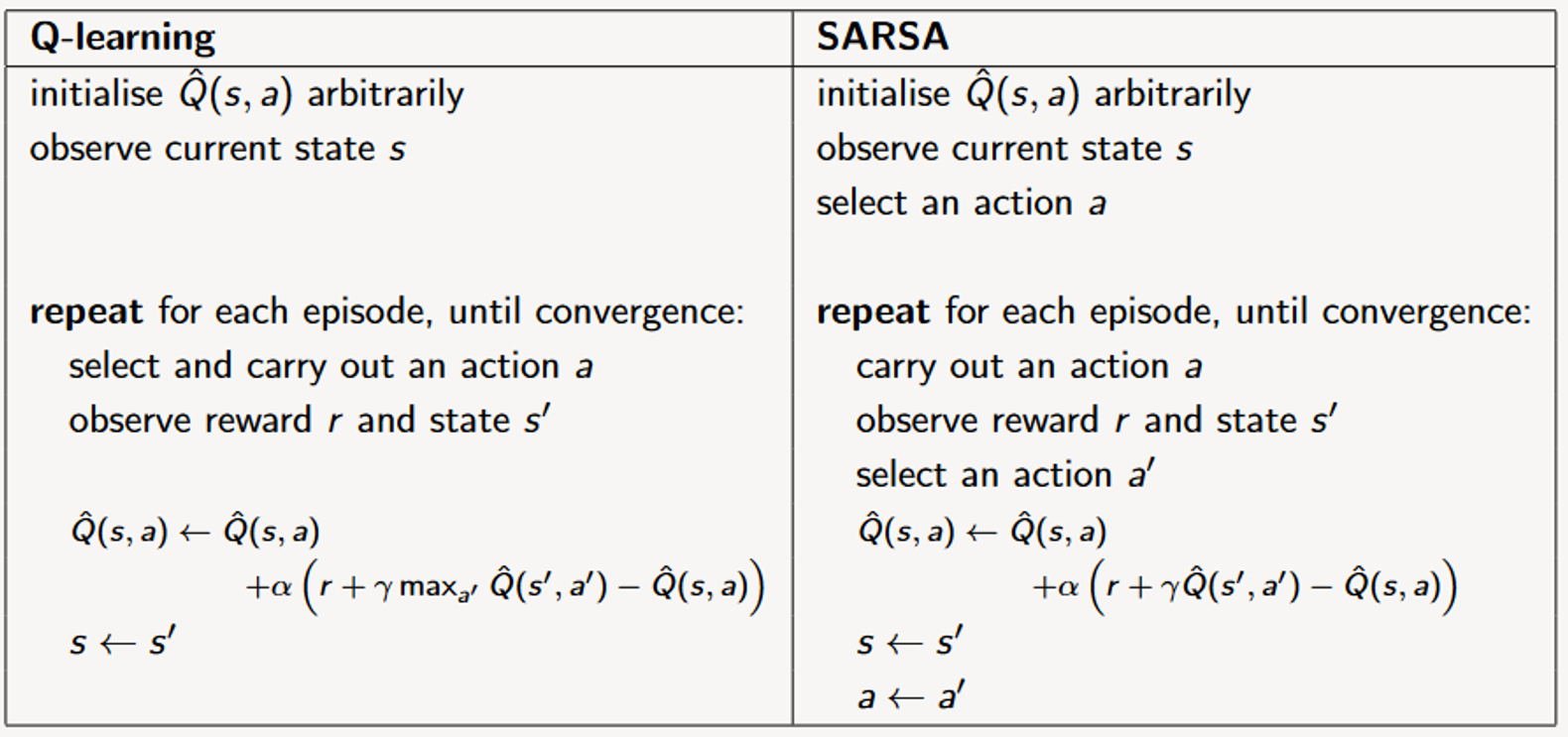
4.2.1 - Q-Learning Pseudocode
Iteratively estimate the table Q^(s,a) from experience:
Initialise Q^(s,a) arbitrarily (e.g. all zeros)
Observe the current state s
Repeat for each episode, until convergence: {Get the policy}
Select and carry out an action a
Observe reward r and state s'
Q^(s,a)←Q^(s,a)+α(r+γmaxa′Q^(s′,a′)−Q^(s,a))
s←s′
For each state s {Extract the policy - find the action that optimises the reward for each state}
π(s)=argmaxaQ^(s,a) # Greedy approach
return π,Q^
🧠 This is very similar to the Bellman equations - like Value Iteration (and somewhat like policy iteration)
On squares with an arrow exiting the grid world, the only action available to the agent is to exit and receive the reward shown.
On any other square, its actions are Left or Right
If the agent is in a square with a square below it, its action will succeed with probability p and with probability 1−p it will fail and the agent will fall into a trap
In other squares, it always moves successfully.
In this step, the agent is updating its estimates from the observations gained from the current episode
In this step, we could use some multi-armed bandit techniques
4.2.3 - Q-Learning Example - Grid World
Using the Q-learning algorithm, the agent quickly determines which actions are the best to perform in each state.
4.3 - Properties of Q-Learning
Q-learning converges to an optimal policy, no matter what the agent does, as long as it tries each action in each state enough times.
But, what should the agent do? Use an exploration strategy to:
Exploit When in state s, select an action that maximises Q(s,a)
Explore Select another action (either arbitrarily or according to some probability)
Choose these strategies from the Multi-Armed Bandits discussed earlier.
4.4 - Problems with Q-Learning
It does one backup between each experience - is this appropriate for a robot interacting with the real world?
An agent might be able to make better use of the data by doing multi-step backups or building a model and using MDP methods to determine the optimal policy
Perform multi-step backups as in TD
It learn separately for each state, might be able to learn better over collections of states (feature-based RL)
5.0 - SARSA (State-Action-Reward-State-Action)
5.1 - On-Policy Learning
Q-Learning does off-policy learning - it learns the value of an optimal policy, no matter what it does
This could be bad if the exploration policy is dangerous
On-learning policy learns the value of the policy being followed.
e.g. act greedily 80% of the time and act randomly 20% of the time
Why? If the agent is actually going to explore, it may be better to optimise the policy it is going to do
SARSA uses the experience (s,a,r,s′,a′) to update Q(s,a)
That is, SARSA uses the actual action that was performed to update the policy.
This leads to better usage of data collected - i.e. less costly mistakes made - learns from mistakes
5.2 - SARSA Pseudocode
Initialise Q^(s,a) arbitrarily (e.g. all zeros)
Observe the current state s
Select an action a
Repeat for each episode, until convergence:
carry out an action a
Observe reward r and state s'
Q^(s,a)←Q^(s,a)+α(r+γQ^(s′,a′)−Q^(s,a)) # here, modifies based on the action that was perf
s←s′
a←a′ # Here we're also looking at the action performed - the agent remembers the action that was performed.
In this, use a MAB or Epsilon-Greedy policy to balance exploration and exploitation