Predictable, stochastic state transitions (underlying probability distribution that govern how the agent transitions from one state to another
Applications of Markov Chains include activity models, target tracking, regression models with mode-switching or reigeme-switching, simulating wind and weather patterns and finance.
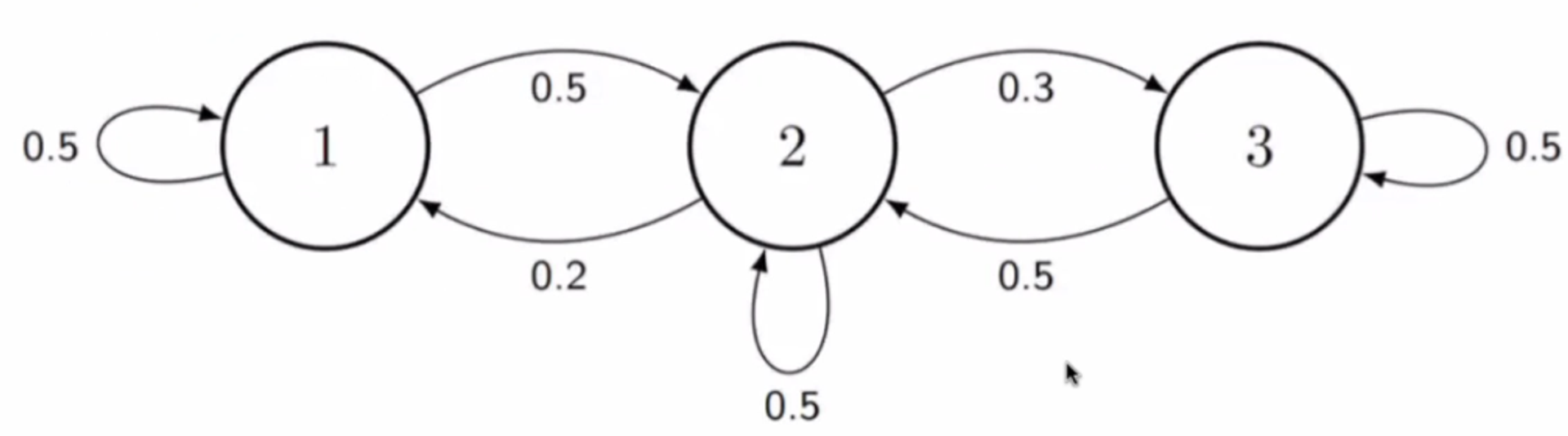
In Markov Chains, states are circles, transitions are edges and weights are probabilities.
No decision-making, purely probabilistic chances of ending up in another state.
The probability moving from state s to state s′ is given by P(s′∣s)
Edges represent transitions with >0 probability
Transitions depend on current state only, not on the full history - this is called the Markovian property. (System is memoryless)
State at time t only depends on state at time t−1
State distribution xt→ probability distribution indicating likelihood of being in each state ate time t
State distribution can be represented as a row vector; when state is known (e.g. at t=0) this vector is one-hot (one element in vector is 1, else 0)
P = 1 in the state that we know the agent is in, and 0 elsewhere.
This could be a fully-connected graph - where you can go from one state to another state in just a single step
To make this graph more readable, we avoid this.
Require this for when we create a matrix to represent the Markov chains
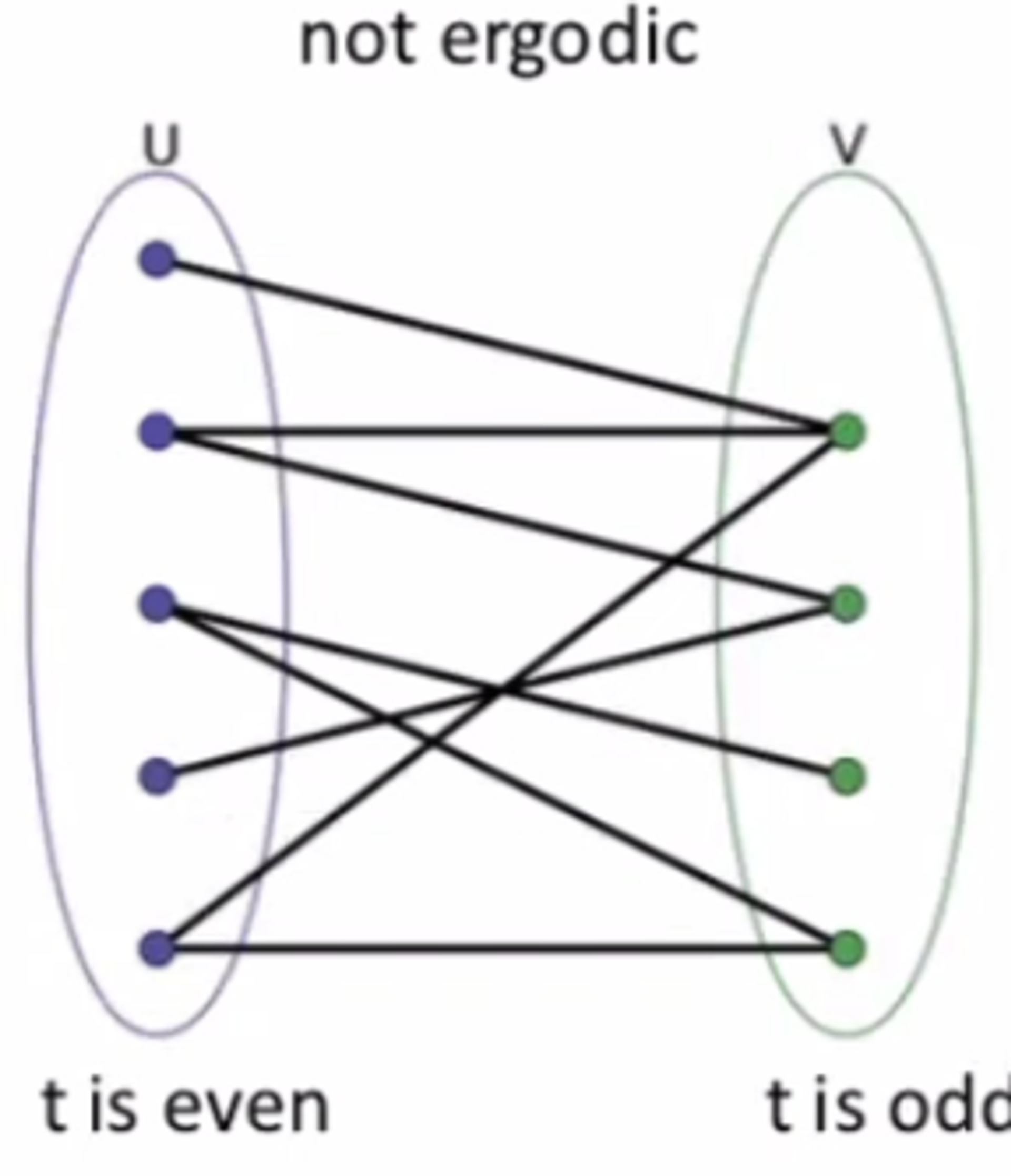
Markov Chains are ergodic if:
Each state can be reached from any other state via some path - fully connected (irreducible)
No periodic cycles - e.g. not a bipartite graph (aperiodic)
Ergodic → There exists some T such that for t>T every state has a probability >0
The graph shown is not ergodic as it violates the irreducible property.
Markov Chains as Matrices
State transition probabilities can be represented by a matrix
P=[0.50.200.50.50.500.30.5]
The size of the matrix is ∣S∣×∣S∣ where ∣S∣ is the number of states in the state space.
The probability denoted in red is the probability of transitioning from state 1 to state 2.
The state distribution at time step k is given by:
xk=xoPk
Probability of being in a given state at time step k is given by multiplying our one-hot vector with the matrix raised to the $k$th power.
Stationary distribution → A distribution xs such that xs+1=xs, i.e. xs=xsP
That is, enough time has passed (i.e. sufficiently large value of s) such that the probability distributions stabilise.
P is the transition dynamics matrix defined earlier.
Over time (as t increases), xt tends towards xs
Can approximate stationary distribution by computing xk for increasing values of k until ∣xk+1−xk∣<ϵ
Obtain the stationary distribution by continuing to iterate until the values stabilise
Stabilise → no discernible difference between xk+1 and xk (that is what $\epsilon$represents).
This will be foundational for our techniques for solving stochastic problems.
Exercise 6.1 - Restless Robot
Robot has no AI. At each time step, it either moves left or right (each with at 50% chance)
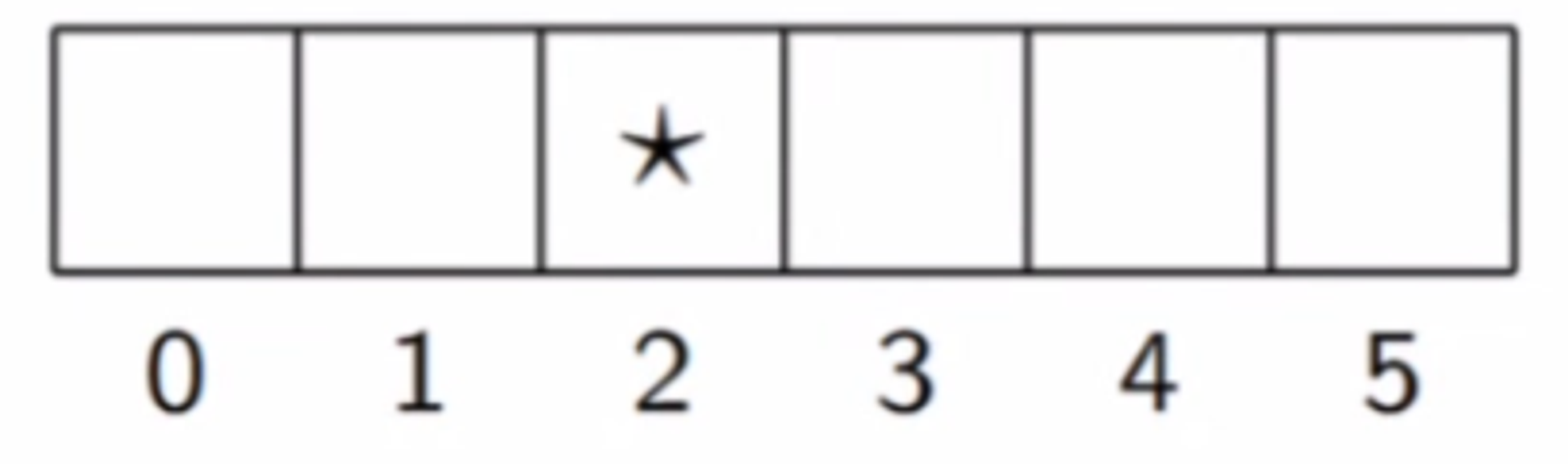
Moving into an edge (e.g. moving left at state 0) causes the robot to stay in the same state. The robot starts in state 2. This system can be modelled as a Markov Chain.
A grid world with a single axis of movement - LEFT and RIGHT.
Robot has no AI → no decision-making capability, but transitions between states using a simple model.
**a)** What are the dimensions of the transition matrix? **b)** Construct the transition matrix in code
The size of the transition matrix is determined by the number of states.
c) Give the initial state vector for starting at state 2, and compute the state distribution at t=1
# Initial state distribution at time t=0. This is our one-hot vector
x0 = np.array([0, 0, 1, 0, 0, 0])
# matrix multiplication instead of element multiplication
x1 = np.matmul(x0, p)
x1 = [0.0, 0.5, 0.0, 0.5, 0.0, 0.0]
d) Compute the state distribution for t=2, t=4, t=10, t=20
From this, we can see that the value of x converges as it grows.
The difference from t=10 to t=20 is significantly less than the difference from t=1 to t=2 or t=2 to t=4
Exercise 6.2 - Navigation Agent
Round UP to closest 15-minute interval.
The solution is found when the root can be labelled as "solved" → propagating the 'solution' label up to the root.
Parts of the AND-OR Tree
Situations where a choice is made (e.g. choosing which road to follow at an intersection) are represented by OR nodes.
Path taken chosen by the user / agent
To solve, there must be at least one path which can be chosen which is solved (guaranteed to reach the goal within the given duration)
Random outcomes (e.g. different amounts of time taken to reach the end of a road due to traffic on that road) and represented by AND nodes
Path taken chosen by world dynamics / environment.
To solve, every path (including the worst possible outcome/worst possible traffic) must be solved
Solving the tree provides a worst-case guarantee.
Another possible way of representing the tree structure's average time to solution would be to take the weighted average of the solution time (weighted by the probability of going down that branch).
If traffic is better than the worst case, it may still be possible to reach the goal within the time duration
Not guaranteed to make it to the goal in time
Important consideration for safety-critical systems
Exercise 6.3 - Car Rental
Choose the most rational (i.e. highest expected utility) opinion out of the following:
Buy x5 GenCar for $40,000 each. Guaranteed rental with $175 income, $25 in expenses per day per car, for 330 days of the year. Not rented for 35 days of the year, with $30 expenses per day
Buy x2 Tesla for $120,000 each. 75% chance of rental with $500 income, $10 in expenses per day per car, and 25% chance of not being rented in $5 in expenses per day per car for 330 days of the year. Not rented for 35 days of the year, with $30 expenses per day
Buy x2 upgraded Tesla for $140,000 each with $600 in rental income, otherwise the same as the base Tesla.
Solved by constructing a rational decision tree
Related to the AND-OR tree
Want to find the highest effective utility
Found by sum of product x utility for each possible outcome