The objective of an MDP is to maximise the expected value of the rewards
E[t=0∑TγtR(St,at)]
MDPs - World State
World State: If the agent knew the world state (information contained within the world state), no information about the past is relevant to the future. This is known as the Markovian Property.
Given that Sk denotes a state at time k and action Ak is the action performed at time k,P(St+1∣S0,A0,⋯,St,At)≡P(St+1∣St,At)≡P(s′∣s,a)
Planning Horizon & Information Availability
Planning Horizon: How far ahead the planner/agent looks forward to make a decision.
Information Availability: What information is available when the agent decides what to do:
Fully Observable MDP (FOMDP): The agent gets to observe St when deciding on action At
Partially Observable MDP (POMDP): The agent has some noisy / imperfect sensor of the state
Policies
A policy is a sequence of actions, taken to move from each state to the next state over the whole time horizon.
A stationary policy is a function or map. Given a state s, the policy π(s) specifies the action takes.
An optimal policy typically denoted as π∗ is one with maximum expected discounted reward.
πmaxE[t=0∑γtR(st,π(st))]
Given that π(t) is the action taken at some time step t.
Value of a Policy
We first approach MDPs using a recursive reformulation of the objective called a value function
The value function of an MDP, Vπ(s) is the expected future reward of following an (arbitrary) policy π starting from state s, given by:
Vπ(s)=s′∈S∑P(s′∣π(s),s)[R(s,π(s),s′)+γVπ(s′)]
Where the policy π(s) determines the action taken in state s
P(s′∣π(s),s) is our transition function for our stochastic world.
R(s,π(s),s′) is our reward function
γVπ(s′) is our discounted future value function
Here, we have dropped the time index as it is redundant, but note that at=π(st)
Note that this is a recursive definition - the value of Vπ(s) depends on the value of Vπ(s′)
Given a policy π
The Q-function represents the value of choosing an action and then following policy π in every subserquent state.
Qπ(s,a), where a is an action and s is a state, is the expected value of doing a in state s, then following policy π
Note: When computing the future value, choose the best action using the policy π instead of for some arbitrary action a
Exercise 7.1
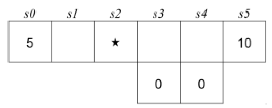
Consider the gridworld below:
An agent is currently on grid cell $s_2$, as indicated by the star and would like to collect the rewards that lie on both sides of it. If the agent is on a numbered square (0,5 or 10), the instance terminates and the agent receives a reward equal to the number on the square. On any other (non-numbered) square, its available actions are to move Left and Right. Note that Up and Down are never available actions. If the agent is in a square with an adjacent square below it , it does not always move successfully. When the agent is in one of these squares and takes a move action, it will only succeed with probability $p$. With probability $1-p$ the move action will fail and the agent will instead fall downwards into a trap. If the agent is not in a square with an adjacent space below, it will always move successfully.
Consider the policy πR which is to always move right when possible. For each state s∈{s1,s2,s3,s4} in the diagram above, give the value function VπR in terms of γ∈[0,1] and p∈[0,1]
Consider the policy πL which is to always move left when possible. For each state s∈{s1,s2,s3,s4} in the diagram above, give the value function VπL in terms of γ∈[0,1] and p∈[0,1]
Exercise 7.1a
We first recall that we're computing the value of the value function at each state, for policy πR. Under this policy, the optimal action in each state is to move right. We now recall the definition of a value function of a MDP.
Vπ(s)=∑s′∈SP(s′∣π(s),s)[R(s,π(s),s′)+γVπ(s′)]
From this, we get the result that:
VπR(s4)VπR(s3)VπR(s2)VπR(s1)=p[0+γ10]=10pγ=p[0+10pγ2]=10p2γ2=1[0+10p2γ3]=10p2γ3=1[0+10p2γ4]=10p2γ4Probability of not falling is p Next state is s5 and it has value of 10Probability of not falling is p Next state is s4 and it has value of 10pγProbability of not falling is 1 Next state is s3 and it has value of 10p2γ2Probability of not falling is 1 Next state is s2 and it has value of 10p2γ3
Exercise 7.2a
Implement the attempt_move and get_transition_probabilities methods in the Grid class according to their docstrings. The aim is to have functions that can be used on an arbitrary grid-world (i.e. do not hard-code your function just for this problem instance.)
We first create an array representing the set of all possible actions that the agent can perform
ACTION_NAMES = ['UP', 'DOWN', 'LEFT', 'RIGHT']
We then create an array representing all the possible states that the agent can be in:
self.states = list((x, y) for x inrange(self.x_size) for y inrange(self.y_size))
We then implement the attempt_move function
defattempt_move(self, s, a):
x, y = s
# Check absorbing stateif s == EXIT_STATE:
return s
if s in self.rewards.keys():
return EXIT_STATE
# Default: no movement
result = s
if a == LEFT and x > 0:
result = (x - 1, y)
if a == RIGHT and x < self.x_size - 1:
result = (x + 1, y)
if a == UP and y < self.y_size - 1:
result = (x, y + 1)
if a == DOWN and y > 0:
result = (x, y - 1)
# Check obstacle cellsif result in OBSTACLES:
return s
return result
And a helper function which gives us the probabilities of each action occurring in the non-deterministic environment.
defstoch_action(self, a):
""" Returns the probabilities with which each action will actually occur,
given that action a was requested.
Parameters:
a: The action requested by the agent.
Returns:
The probability distribution over actual actions that may occur.
"""if a == RIGHT:
return {RIGHT: self.p , UP: (1-self.p)/2, DOWN: (1-self.p)/2}
elif a == UP:
return {UP: self.p , LEFT: (1-self.p)/2, RIGHT: (1-self.p)/2}
elif a == LEFT:
return {LEFT: self.p , UP: (1-self.p)/2, DOWN: (1-self.p)/2}
return {DOWN: self.p , LEFT: (1-self.p)/2, RIGHT: (1-self.p)/2}
defget_transition_probabilities(self, s, a):
probabilities = {}
for action, probability in self.stoch_action(a).items():
next_state = self.attempt_move(s, action)
probabilities[next_state] = probabilities.get(next_state, 0) + probability
return probabilities
Exercise 7.2b
What is the one-step probability of arriving in each state s′ when starting from [0,0] for each a (i.e. what is P(s′∣a,[0,0])∀a,s′)
We can determine the one-step probability of arriving in each state by calling our get_transition_probabilities function for each action.
What is the one-step probability of arriving in state [1,0] from each state s after taking action a. That is, what is P([1,0]∣a,s)∀(a,s)
We can once again call the get_transition_probabilities function, iterating over all possible state and action pairs. From this, we get the following result:
Note that R(s,a,s′)=R(s) is the reward for landing on a square, which is non-zero for only the red and blue squares located at [3,1] and [3,2] respectively.
a) What is the value function estimate after 4 iterations? What is the policy according to the value function estimate after 4 iterations?
b) What is the value function estimate after 10 iterations? What is the policy according to the value function estimate after 10 iterations?
The equation given below is a version of the Bellman update equation for Value Iteration.
V[s]←amaxs′∑P(s′∣s,a)(R(s,a,s′)+γV[s′])
To implement value iteration, we want to compute ∑s′P(s′∣a,s)[R(s,a,s′)+γV[s′]] for each possible next state, s′.
We first define some functions and constants that will help with the implementation of Value Iteration. The dict_argmax function will be used as the mathematical operation maxa.
EPSILON = 0.0001defdict_argmax(d):
max_value = max(d.values())
for k, v in d.items():
if v == max_value:
return k
We then create a class containing all of the information we want to keep track of in our VI implementation
classValueIteration:
def__init__(self, grid):
self.grid = grid
self.values = {state: 0for state in self.grid.states}
self.policy = {state: RIGHT for state in self.grid.states}
self.converged = False
self.differences = []
defnext_iteration(self):
new_values = dict()
new_policy = dict()
for s in self.grid.states:
# Keep track of maximum value
action_values = dict()
for a in self.grid.actions:
total = 0for stoch_action, p in self.grid.stoch_action(a).items():
# Apply action
s_next = self.grid.attempt_move(s, stoch_action)
total += p * (self.grid.get_reward(s)
+ (self.grid.discount * self.values[s_next]))
action_values[a] = total
# Update state value with best action
new_values[s] = max(action_values.values())
new_policy[s] = dict_argmax(action_values)
# Check convergence
differences = [abs(self.values[s] - new_values[s]) for s in self.grid.states]
max_diff = max(differences)
self.differences.append(max_diff)
if max_diff < EPSILON:
self.converged = True# Update values
self.values = new_values
self.policy = new_policy
We can then write some code to determine the policy after each iteration
defrun_vi():
grid = Grid()
vi = ValueIteration(grid)
start = time.time()
print("Initial values:")
vi.print_values()
print()
for i inrange(MAX_ITER):
vi.next_iteration()
print("Values after iteration", i + 1)
vi.print_values_and_policy()
print()
if vi.converged:
break
end = time.time()
print("Time to complete", i + 1, "VI iterations")
print(end - start)
From this, we get the policy after 4 iterations:
Values and Policies after iteration 4
(0, 0) UP 0.0
(0, 1) UP 0.0
(0, 2) RIGHT 0.3732480000000001
(1, 0) UP 0.0
(1, 2) RIGHT 0.6583680000000002
(2, 0) UP 0.046656
(2, 1) LEFT 0.11728799999999999
(2, 2) RIGHT 0.7964640000000001
(3, 0) DOWN 0.0
(3, 1) UP -100.0
(3, 2) UP 1.0
(-1, -1) UP 0.0
Converged: False
And after 10 iterations
Values and Policies after iteration 10
(0, 0) UP 0.4490637007006404
(0, 1) UP 0.5362371998424762
(0, 2) RIGHT 0.61632756154903
(1, 0) LEFT 0.3679911227699528
(1, 2) RIGHT 0.7155133495934718
(2, 0) LEFT 0.28052219829783076
(2, 1) LEFT 0.28600606577514903
(2, 2) RIGHT 0.8174373191274608
(3, 0) DOWN 0.05225467158005328
(3, 1) UP -100.0
(3, 2) UP 1.0
(-1, -1) UP 0.0
Converged: False
And after 40 iterations
Values and Policies after iteration 40
(0, 0) UP 0.4800323382261456
(0, 1) UP 0.5540265799556026
(0, 2) RIGHT 0.6309786313152921
(1, 0) LEFT 0.42148665011938496
(1, 2) RIGHT 0.728236805418173
(2, 0) LEFT 0.37165369571437096
(2, 1) LEFT 0.38600516990982364
(2, 2) RIGHT 0.8293834149435776
(3, 0) DOWN 0.17564736007905382
(3, 1) UP -100.0
(3, 2) UP 1.0
(-1, -1) UP 0.0
Converged: True
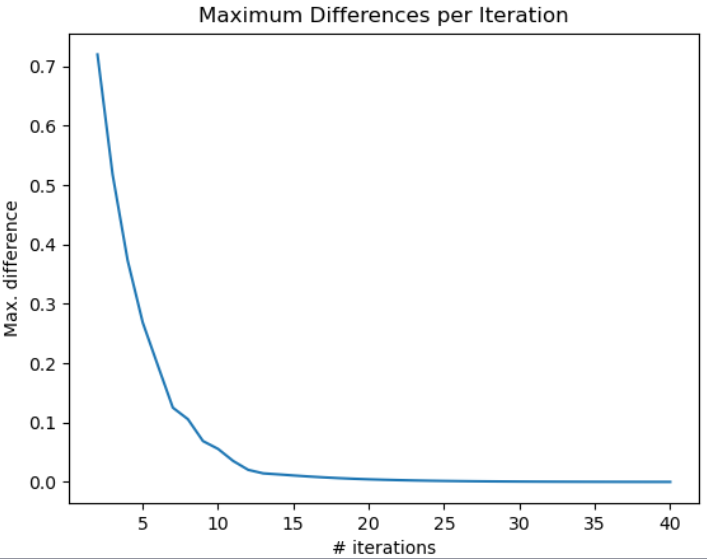
From this, we can see that as the iteration number increases, the changes between the policy values decreases (it converges toward a value). These values propagate outwards from the states in which the agent receives a reward.
7.4
How does Policy Iteration work?
Very broadly, the pseudocode for Policy Iteration is given as:
whilenot converged: # Convergence criteria - (new_policy == policy)# policy_evaluation uses linear algebra to derive a set of values# as shown above
values <- policy_evaluation(policy)
# compute a new policy using the previously computed set of values# Looks like value iteration, but only a single iteration is performed.
new_policy <- policy_improvement(values)
if new_policy == policy:
# Convergence criteria matched, return the policyreturn policy
# Convergence criteria not matched, set the policy and perform# another iteration
policy <- new_policy
To implement Policy Iteration, we begin by creating a class to store the required values, as with Value Iteration
classPolicyIteration:
def__init__(self, grid):
self.grid = grid
self.values = {state: 0for state in self.grid.states}
self.policy = {pi: RIGHT for pi in self.grid.states}
self.r = [0for s in self.grid.states]
self.USE_LIN_ALG = False
self.converged = False# Full transition matrix (P) of dimensionality |S|x|A|x|S| since its# not specific to any one policy. We'll slice out a |S|x|S| matrix# from it for each policy evaluation# t model (lin alg)
self.t_model = np.zeros([len(self.grid.states), len(self.grid.actions),
len(self.grid.states)])
for i, s inenumerate(self.grid.states):
for j, a inenumerate(self.grid.actions):
transitions = self.grid.get_transition_probabilities(s, a)
for next_state, prob in transitions.items():
self.t_model[i][j][self.grid.states.index(next_state)] = prob
# Reward vector
r_model = np.zeros([len(self.grid.states)])
for i, s inenumerate(self.grid.states):
r_model[i] = self.grid.get_reward(s)
self.r_model = r_model
# lin alg policy
la_policy = np.zeros([len(self.grid.states)], dtype=np.int64)
for i, s inenumerate(self.grid.states):
la_policy[i] = 3# Allocate arbitrary initial policy
self.la_policy = la_policy
defnext_iteration(self):
new_values = dict()
new_policy = dict()
self.policy_evaluation()
new_policy = self.policy_improvement()
self.convergence_check(new_policy)
defpolicy_evaluation(self):
ifnot self.USE_LIN_ALG:
# use 'naive'/iterative policy evaluation
value_converged = Falsewhilenot value_converged:
new_values = dict()
for s in self.grid.states:
total = 0for stoch_action, p in self.grid.stoch_action(self.policy[s]).items():
# Apply action
s_next = self.grid.attempt_move(s, stoch_action)
total += p * (self.grid.get_reward(s) + (self.grid.discount * self.values[s_next]))
# Update state value with best action
new_values[s] = total
# Check convergence
differences = [abs(self.values[s] - new_values[s]) for s in self.grid.states]
ifmax(differences) < EPSILON:
value_converged = True# Update values and policy
self.values = new_values
else:
# use linear algebra for policy evaluation# V^pi = R + gamma T^pi V^pi# (I - gamma * T^pi) V^pi = R# Ax = b; A = (I - gamma * T^pi), b = R
state_numbers = np.array(range(len(self.grid.states))) # indices of every state
t_pi = self.t_model[state_numbers, self.la_policy]
values = np.linalg.solve(np.identity(len(self.grid.states)) - (self.grid.discount * t_pi), self.r_model)
self.values = {s: values[i] for i, s inenumerate(self.grid.states)}
defpolicy_improvement(self):
if self.USE_LIN_ALG:
new_policy = {s: self.grid.actions[self.la_policy[i]] for i, s inenumerate(self.grid.states)}
else:
new_policy = {}
for s in self.grid.states:
# Keep track of maximum value
action_values = dict()
for a in self.grid.actions:
total = 0for stoch_action, p in self.grid.stoch_action(a).items():
# Apply action
s_next = self.grid.attempt_move(s, stoch_action)
total += p * (self.grid.get_reward(s) + (self.grid.discount * self.values[s_next]))
action_values[a] = total
# Update policy
new_policy[s] = dict_argmax(action_values)
return new_policy
defconvergence_check(self, new_policy):
if new_policy == self.policy:
self.converged = True
self.policy = new_policy
if self.USE_LIN_ALG:
for i, s inenumerate(self.grid.states):
self.la_policy[i] = self.policy[s]
The initial policy values affects how many iterations it takes to reach convergence.
Exercise 7.4b
Let Pπ∈R∣S∣×∣S∣ be a matrix containing probabilities for each transition under some policy π, where
Pijπ=P(st+1=j∣st=i,at=π(st))
Calculate the size of Pπ in this grid world, where the special pseudo state is included.
Excluding the obstacle at (1,1) as an unreachable state, but include the exit state, then the size of Pπ is 12x12. Including the obstacle brings the size to 13x13 but the transition probability to (1,1) is 0 from all states
Exercise 7.4c
Set the policy to move right everywhere, π(s)=RIGHT∀s∈S. Calculate the row of pRIGHT corresponding to the initial state at the bottom left corner, (0,0) of the gridworld.
i.e. The probability of starting in state (0,0) and moving to state j==s' when performing the action RIGHT has the probability ___.
P((0,0)∣(0,0),RIGHT)=0.1
The probability of starting in state (0,0) and moving to state (0,0) when action RIGHT is performed has probability 0.01 of occurring - this is the first perpendicular state.
P((0,1)∣(0,0),RIGHT)=0.8
The probability of starting in state (0,0) and moving to state (1,0) when action RIGHT is performed has probability of 0.8 occurring - this is the chosen direction
P((0,0)∣(0,0),RIGHT)=0.1
The probability of starting in state (0,0) and moving to state (2,0) when action RIGHT is performed has probability of 0.8 occurring - this is the second perpendicular state.
Exercise 7.4d
Write a function to calculate the row of PRIGHT corresponding to an initial state at the bottom-left corner, (0,0) of the gridworld for any action or deterministic π((0,0)).