Partition(A, p, r)
x = A[r]
i = p - 1
for j = p to r - 1
if A[j] <= x
i = i + 1
exchange A[i] with A[j]
exchange A[i + 1] with A[r]
return i + 1
1.0 - Average Case Analysis
-
At the start of the semester started discussing analysis of algorithms.
-
Thus far have used best and worst case analyses
-
We now consider probabilistic average-case analysis
- To compute this, we need to know the probability distribution of inputs of size .
1.1 - Hire Assistant Example
hire_assistant(n)
best = 0
for j = 1 to n
interview candidate j // at cost ci
if candidate j is better than the best candidate
best = j
hire candidate j // at cost ch
Let total number of candidates
$m:$ number of candidates hired
Our actual cost is
Our worst case is is when
This occurs when the candidates ordered from worst to best - they are all hired and then replaced
Our best case occurs when the candidates are ordered from best to worst
1.1.1 - Average Case Analysis
-
Probability of hiring the th candidate - to decide this we need to make a few assumptions
-
Assume that the candidates are in random order
-
Any of the first candidates is equally likely to be the best candidate.
-
The probability that the th candidate is the best is
-
Based on this probability, we can compute or average case. Thus the average cost of hiring candidates is
-
Recall the harmonic series:
-
We can randomise the input to the algorithm ourselves - this can be done for example, to reduce the probability of obtaining the worst-case time complexity of the algorithm
-
Also has security implications - if attackers know that a certain algorithm runs slowly (or quickly) for a certain input, we essentially “take away” their power by randomising the input order ourselves.
1.2 - Randomised Algorithms
- An algorithm is randomised if its behaviour is determined by both:
- Its inputs
- Values produced by a random number generator
- For deterministic (i.e., not randomise) algorithms, we can calculate the average running time, based on a probability distribution of inputs.
- For randomised algorithms we can calculate the expected running time - without having to make assumptions about the probability distribution of inputs.
- Note that when we
randomised-hire-assistant(n)
// randomly permute the list of candidates
for j = 1 to n
interview candidate j // at cost ci
if candidate j is better than the best candidate
best = j
hire candidate j // at cost ch
- We want a uniform random permutation - chance of each permutation of the elements of array
permute-by-sort(A)
n = A.length
let P[1..n] be a new array
for i = 1 to n
P[i] = random(1, n^3)
sort A, using P as the sort keys
-
This algorithm is guaranteed to give us elements with uniform random distribution given that the keys chosen by the random algorithm are unique.
-
The probability of this occurring is given by
-
As a lower bound, we can multiply the last tern times:
-
Chance of succeeding is going to be larger as the value of increases.
-
We can extend the previous example by randomly permuting in place.
randomise-in-place(A) n = A.length for i = 1 to n swap A[i] <-> A[Random(i, n)]- This code will produce a given random permutation with probability
- Proving this may seem tricky, but we can do it using a loop invariant.
- Terminology: A -permutation of a set of elements is defined to be the sequence containing of the elements.
- Following this definition, our invariant, denoted is that contains any i-permutation of A with probability
- Upon the loop finishing, we know that we have a given permutation of with probability
-
A loop invariant is a property that is true for:
- Before we enter the loop body for the first time
- After each execution of the loop body
-
We can prove that this invariant holds using a proof by mathematical induction
-
We now prove that the base case holds - the invariant is true when , before we enter the loop body.
-
Before the first iteration, the array contains a (given) 0-permutation with probability
-
Given that the invariant holds for , , we want to prove that the invariant holds for
-
Assume contains any permutation with probability
-
We consider the permutation
-
Let be the event that is
- We already know this probability, from the inductive assumption
-
Let be the event that the iteration places in
- This probability is given by choosing a specific from the remaining elements.
- We know that there are elements left, and thus the probability is
-
The probability of the permutation occurring is given by the probability of both and occurring:
-
-
This is the value that we get for our substitution of and thus the inductive argument is proven true.
-
We now need to prove that the loop does in fact terminate which is easy to argue
-
On termination, holds, that is, contains any of the original array, with probability
-
Therefore A contains any permutation of the original array with probability
-
Therefore, each of the possible permutations of the original arary is equally likely - a uniform distribution of outcomes.
2.0 - Analysis of Comparison Based Sorting Algos
Merge SortDivide and ConquerHeap SortBuild and manipulate a heapQuick SortPre-process array by partitioning into elements greater-than and less-than some elements (the “pivot”)- Merge-Sort and Heap-Sort have worst case time complexity, where Quick-Sort has time complexity.
2.1 - Quick-Sort
-
Quick Sort- Pre-process data into “low” and “high” elements.quicksort(A, p, r) if (p < r) q = partition(A, p, r) quicksort(A, p, q-1) quicksort(A, q+1, r) -
All elements from in the subrange are less than elements from
-
Given these two partitions, we recursively call the quicksort algorithm on both sub-partitions
- Note that these sub-partitions are not of equal size, and thus the time complexity analysis for quick sort is more complicated.
2.1.1 - Partition
-
The partition(A, p, r) algorithm rearranges A at the subrange (in place).
-
The element is the pivot value for this example
-
In this example, we choose as the pivot
Partition(A, p, r) x = A[r] i = p - 1 for j = p to r - 1 if A[j] <= x i = i + 1 exchange A[i] with A[j] exchange A[i + 1] with A[r] return i + 1 -
We then continue running the algorithm, until everything less than the pivot is to its left, and everything greater than the pivot is to the right.
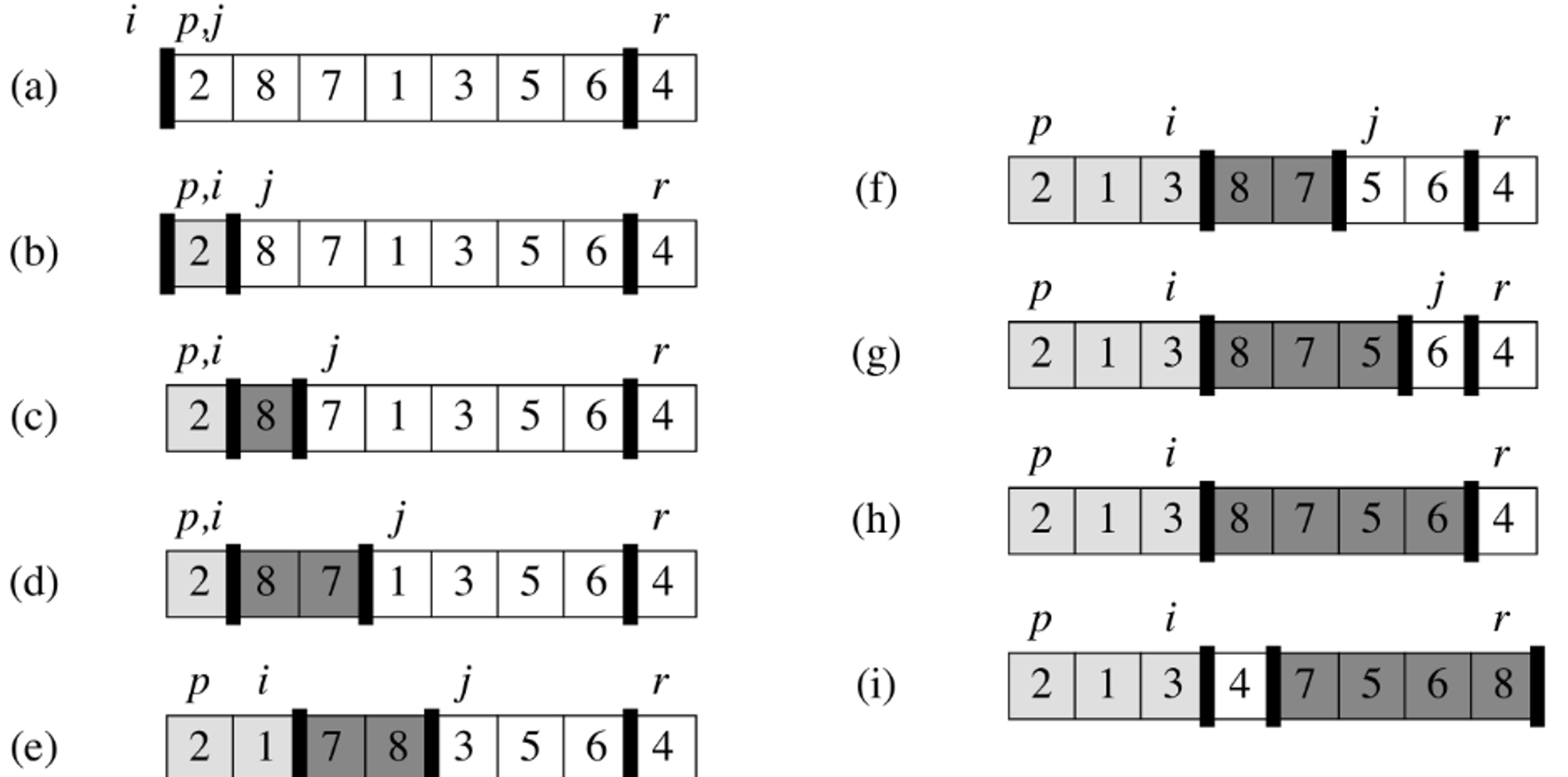
-
The partition algorithm keeps track of two indices = which have initial values:
-
Initially, the portion of the array from and will be empty.
-
As the algorithm progresses, we maintain the invariant that the elements in and
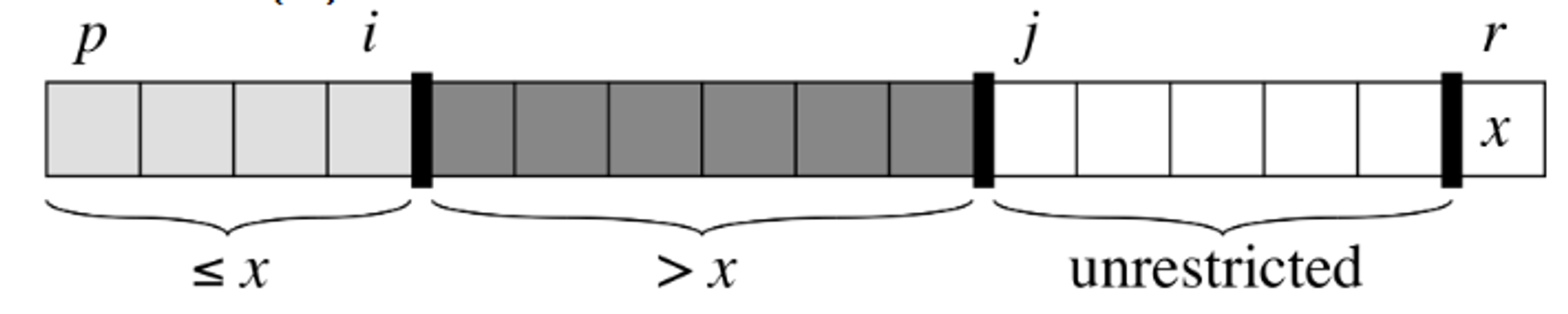
-
We maintain the invariant by checking the element and comparing it with the pivot element,
-
If the element is less than or equal to , we place it at the end of the first portion. This overwrites the first element in the portion of elements so we place the displaced element where the element we’re inserting came from.
-
Otherwise, (if the element is greater than ) we don’t need to perform this swapping procedure, and can simply just increment the value of through the for-loop.
-
Upon completing the for-loop iterations, we can insert in-place between our two partitions
2.2.2 - Analysis of Quick Sort
-
The performance of the quick-sort algorithm depends on the element chosen as pivot
- Best and Average Case
- Worst Case = insertion sort
-
Worst case occurs when the input array is sorted.
-
When array is almost sorted (or is sorted) insertion sort runs in near-linear time.
-
The best occurs when (best case occurs when QuickSort behaves like mergesort)
-
Constant Ratio Split:
-
That is, consider what happens if we have elements in the first partition and in the second partition
-
-
The worst case occurs when we have one partition with no elements, and thus the call size decreases by 1 each iteration (for the other partition)
- The worst case is:
2.2.3 - Intuition for “Constant Ratio Split”
-
Suppose
<figure style="display:flex;justify-content:center;max-width:60%;"> <img src="./assets/constant-split-ratio.png"> -
At each level we perform work
-
The upper (or lower) bound on the tree is dependent on the height of the tree
-
Lower bound derived by tracing down the leftmost branch where we reduce by a factor of each time
-
Upper bound derived by tracing down the rightmost branch where we reduce by a factor of each time
-
Even in the worst case, we have a time complexity of
-
2.2.4 - Average Case Analysis for Quick-Sort
- Consider the total number of comparisons of elements done by partition over all calls by quicksort.
- Label the elements of A as with being the smallest element.
- Let
- Consisting an input array consisting of in any order, and assume that the pivot is 4
- The array is partitioned into two sets:
- In partitioning:
- The pivot 4 is compared with every element
- But no element from the first set is (or ever will be) compared with an element from the second set.
**********************Probability compared with
-
For any elements and , once a pivot is chosen such that
and can never be compared in the future
-
If is chosen as a pivot before any other element in (that is, , then will be compared with every other element in
-
Likewise, if
-
Thus, and are compared if and only if the first element chosen as a pivot in is either or
-
Any element in is equally likely to be chosen as a pivot and has elements.
-
That is, each element occurs with probability:
-
Analysis of Quick Sort
-
Each pair of elements is compared at most once because in the partition algorithm, elements are compared with the pivot only at most once, and an element is only used as a pivot in at most one call to partition.
Number of Comparisons over all calls to Partition
- To determine the number of comparisons over all calls to the partition algorithm, we must consider all combinations of and
2.2.5 - Randomised Quick-Sort
- Despite the bad worst-case bound, Quicksort is regarded by many to be a good sorting algorithm
- Good expected-case performance can be achieved by randomly permuting the input before sorting.
- This permuting can be done in
- In practice, an even simpler approach specific to QuickSort is to choose a pivot from a random location.
- This just requires a constant-time swap of some random element with
- Having done this, the worst-case is unlikely, and the expected time complexity of the algorithm becomes
2.2 - Merge Sort
-
Merge Sort- post-process sorted data into a single, sorted arraymerge-sort(A, p, r) if (p < r) q = floor((p+r)/2) merge-sort(A, p, q) merge-sort(A, q+1, r) merge(A, p, q, r) -
Sort then post-process (merge)
-
At each stage, we’re calling merge-sort on subproblems that are exactly half the size.
-
Thus, the recurrence that describes this algorithm’s running time is:
3.0 - Randomised Algorithm Example
💡 Given a procedure, biased-random() that returns 0 with probability and with probability , where , how can you implement a procedure that returns 0 or 1 with equal probability
3.1 - Algorithm Construction
random()
a = biased-random()
-
Flipping the coin once gives the following:
-
Flipping the coin twice gives the following
-
Thus,
-
Finally, our algorithm is:
Random() a = biased-random() b = biased-random() while a == b: a = biased-random() b = biased-random() return a -
This algorithm has almost-certain termination, but there is a probability that it continues forever (with probability )
3.2 - Expected Running Time
-
We can count the expected running time of the algorithm as a function of the number of times that it runs.
-
Let be the probability that
-
Probability of terminating after 0 loop iterations is
- That is, our first coin flip yields our desired result.
-
Probability of terminating after 1 loop iterations is
- is the probability of a “bad” flip occurring
-
Probability of terminating after 2 loop iterations is
-
Probability of terminating after loop iterations is
-
Using this result, the expected number of loop iterations is
-
If then we would expect to perform 1 iteration
-
The more unfair our coin gets, the more iterations we expect to perform