Week 1.2
Week 1.2
🏷️ Replace this section with some keywords that can be used for searching, tagging and the indexing of this page.
Sections
🌱 Links to all Heading1 Blocks in this page.
- PL0’s Lexical Tokens
- Concrete Syntax Trees
- Abstract Syntax Trees
- Syntax Checking and Type Checking
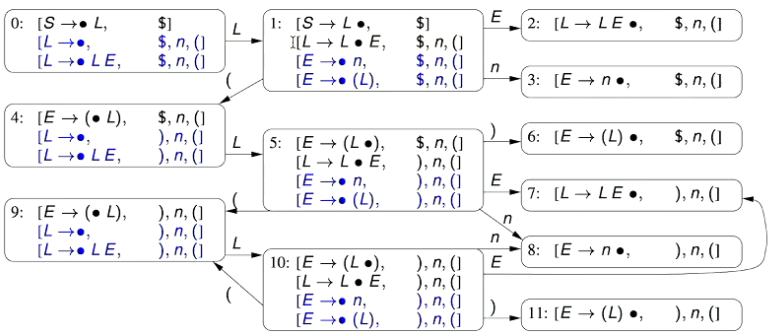
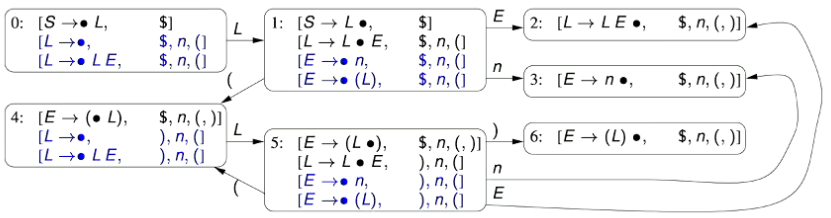
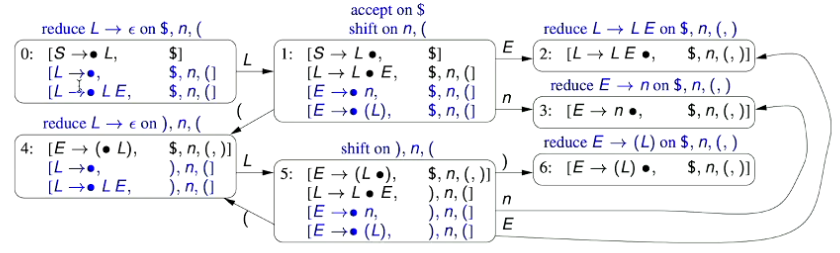
1.0 - PL0’s Lexical Tokens
1.1 - An Aside on Regular Expressions
- Lexical tokens are also called terminal symbols (as opposed to non-terminal symbols, terminal symbols are the leaf nodes of a parse tree)
- Lexical tokens for PL0 are defined in this table by grammar rules which have
regular expressionsas their right sides - A regular expression is either
- A string in quotes (strictly the concatenation of characters)
- A sequence of regular expressions representing their concatenation
- A set of alternative regular expressions separated by “|”
- A regular expression in parenthesis, “(” and “)” indicating a grouping
- A regular expression followed by a “*” indicating zero or more occurrences of the construction
- Repetition has the highest precedence followed by concatenation and then alternation (Aho 1, Sect 3.3), (Louden 4, Section 2.2)
1.2 - List of PL0 Lexical Tokens
- There are two special tokens:
EOFrepresenting the end of an input fileILLEGALrepresenting any illegal token: Any character that doesn’t match the tokens defined below and isn’t part of a comment or whitespace.
- Note here that the constructs Alpha and Digit are not lexical tokens for PL0; They are abbreviations for decimal digits and alphabetical characters, respectively, used in the definition of the tokens NUMBER and IDENTIFIER
- DIGIT → “0” | “1” | “2” | “3” | “4”| “5” | “6” | “7” | “8” | “9”
- ALPHA → “a” | “b” | “c” | “d” | “e”| “f” | “g” | “h” | “i” | “j”| “k” | “l” | “m” | “n” | “o”| “p” | “q” | “r” | “s” | “t” | “u” | “v” | “w” | “x” | “y” | “z” | “A” | “B” | “C” | “D” | “E”| “F” | “G” | “H” | “I” | “J”| “K” | “L” | “M” | “N” | “O” | “P” | “Q” | “R” | “S” | “T” | “U” | “V” | “W” | “X” | “Y” | “Z”
- The REGEX definition of PL0’s NUMBER token is
Digit Digit*which essentially means a digit, followed by one or more digits. - The REGEX definition of PL0’s IDENTIFIER token is
Alpha (Alpha | Digit)*which essentially means an alphanumeric character followed by one or more alphanumeric character or digit.
- To solve ambiguities in the list of lexical tokens, the lexical analyser
- First matches the longest string e.g. “>=” matches as rather than as “>” () followed by “=” () and then
- Second, matches the earliest of the rules e.g. “begin” matches as rather than as , but note that “beginx” matches as identifier as it is no longer a matches the keyword
2.0 - Concrete Syntax Trees
🌱 From the “PL0 Compiler Example” PowerPoint.
- The grammar of the language can be used to extract the structure of the program statement (from its sequence of lexical tokens)
- The structure of that can be described using a concrete syntax tree.
- From before, we know that our code can be parsed as the following lexical tokens.
KW_IF, IDENTIFIER("x"), LESS NUMBER(0), KW_THEN, IDENTIFIER("z"), ASSIGN, MINUS, IDENTIFIER("x"), KW_ELSE, IDENTIFIER("z") ASSIGN, IDENTIFIER("x")
2.1 - Parsing the Concrete Syntax Tree
(1) We start with the Statement node as our root node as we’re defining a PL0 statement.
(2) We know that it’s a conditional statement (an IfStatement) so we add that node to the tree.
- By the grammar previously defined, an
IfStatementis defined as follows
Statement → Assignment | CallStatement | ReadStatement | WriteStatement | WhileStatement | IfStatement | CompoundStatement
(3) We then expand the IfStatement node using the definitions in our Grammar.
Some of these blocks are terminal (as denoted by the boxes with sharp corners) which are the leaf nodes of our Concrete Syntax Tree.
These are our lexical tokens.
IfStatement → KW_IF Condition KW_THEN Statement KW_ELSE Statement
(4) We then expand the Condition node using the definitions in our grammar
Condition → RelCondition
RelCondition → Exp [RelOp Exp]
(5) We then expand the Expression nodes and RelOp node based on our grammar definitions
Expression → [PLUS | MINUS] Term {(PLUS | MINUS) Term)
Term → Factor {(TIMES | DIVIDE) Factor}
Factor → LPAREN Condition RPAREN | NUMBER | LValue
LValue → IDENTIFIER
RelOp → EQUALS | NEQUALS | LESS | GREATER | LEQUALS | GEQUALS
(6) We then expand the Statement nodes based on our grammar definitions
Statement → Assignment | CallAssignment | ReadStatement | WriteStatement | WhileStatement | IfStatement | CompoundStatment
Assignment → LValue ASSIGN Condition
2.1 - Lessons from The Concrete Syntax Tree
- We can see that when performing an in-order traversal of the leaf nodes, we get our initial tokens in exactly the same order.
- The Concrete Syntax Tree contains all of the information about the structure of the program
- This tree contains many nodes with single child nodes - this information is very sparsely packed and we can compact it down a lot.
- We don’t need all of this information to type-check, interpret or generate code for the program.
3.0 - Abstract Syntax Trees
🌱 We can use Abstract Syntax Trees to represent the same information as in a Concrete Syntax Tree in a denser format.
4_PL0_Compiler_Data_Structures.pdf
The Abstract Syntax Tree is represented in the compiler by three main Java classes (and their various subtypes)
DeclNodeStatementNodeExpNodes
The
DeclListNodeabstract class groups the Abstract Syntax Tree nodes for the procedures into a list - each entry in the list represents a single procedure and includes the procedure’s symbol table entry, and aBlockNoderepresenting it’s bodyDeclNode() with subclasses DeclListNode(List<DeclNode> decls) ProcedureNode(SymEntry.ProcedureEntry procEntry, BlockNode body)The
StatementNodeabstract class represents a statement in the abstract syntax tree: it has a subclass for each kind of statement.ErrorNodecaters for erroneous statements.- All statement nodes contain a Location which is the location in the source code corresponding to the node.
BlockNoderepresents the body of a procedure (or the main program)
StatementNode(Location loc) with subclasses ErrorNode() # Store the errors in the AST to provide the programmer with # as much information as possible :) BlockNode(DeclListNode procedures, StatementNode body, Scope blockLocals) AssignmentNode(ExpNode lvalue, ExpNode e) WriteNode(ExpNode e) CallNode(String id) ListNode(List<StatementNode> sl) IfNode(ExpNode cond, StatementNode s1, StatementNode s2) # Conditional node WhileNode(ExpNode cond, StatementNode s)Suppose we want to construct the Abstract Syntax Tree of the following expression:
if x < 0 then z := -x else z := xWe know that our node is going to be a binary comparison node.
ExpNode(Location loc, Type t) with subclasses ConstNode(int value) IdentifierNode(String id) BinaryNode(Operator op, ExpNode left, ExpNode right)
- We have now populated the
BinaryNodewith it’s children - By constructing the AST we have essentially constructed the CST and summarised the information in a much less verbose manner.
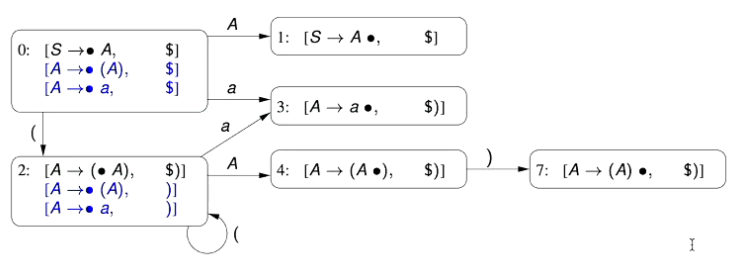
4.0 - Syntax Checking and Type Checking
4.1 - Syntax Checking
if x < 0, then z := -x else z := x
- Suppose that we required the above code to be syntactically correct, what are our requirements
- The condition x < 0 should be a Boolean
- The statements
z := -xandz := xare type correct
- For the statement
z := -xto be type correct, the variablezmust be a reference type (must have an allocated spot in memory)- We need a variable to have a memory address for it to be assigned a new value
- The expression
-xmust evaluate to an expression which is type compatible withtype(z)
- As we perform type-checking, we update our abstract syntax tree, and separately our symbol table with type information
- For example, to resolve the expression
x < 0, we will need to resolve the type ofIDENTIFIER(”x”) - Therefore, in the type checking phase, we update the abstract syntax tree with type information
- To resolve the expression
z := x, we may need to perform some coercions
- For example, to resolve the expression
4.2 - Type Checking the Abstract Syntax Tree (AST)
- The
IdentifierNodeis only used during the parsing phase to represent a reference to either a symbolic constant or a variable. - As part of the static semantics (type checking) phase, it will be transformed to either a
ConstNodeorVariableNode
4.2.1 - Coercions
A number of other node types are only introduced in the static semantics phase:
- A
DereferenceNoderepresents a dereference of a variable address (left value) to access its (right) value NarrowSubrangeNodeAn expression of a type, T, can be narrowed to a subrange of T (for the purpose of coercing a larger subrange into a smaller subrange)WidenSubrangeNodeAn expression of a subrange type can be widened to the base type of the subrange
ExpNode(Location loc, Type t) with subclasses DereferenceNode(ExpNode leftVaue) NarrowSubrangeNode(ExpNode e) WidenSubrangeNode(ExpNode e)- A
In this example, we are type checking the abstract syntax tree for the following PL0 code
if x < 0 then z := -x else z := x
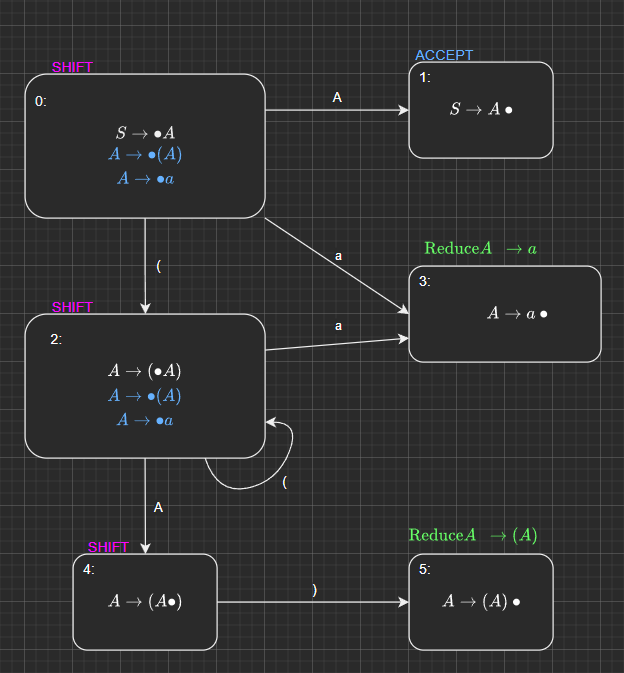
We first evaluate the expression
x < 0- we need to determine whether the expression has a Boolean value.We’re essentially checking the
BinaryNodeand its children nodes (as indicated by the orange box)We notice that the
BinaryNodespecifies the use of LESS_OP which is the less than operator.The less than operator takes two integers and returns a Boolean value, i.e.
We need to check that both the Identifier “x” and the Constant 0 are both integers, or coerce them into Integers if they are not.
- We resolve the type of the identifier “x” by looking it up in our symbol table.
- By looking up the type of the identifier “x” we may see that its type is
ref(int)(that is, a reference to an integer) - We need to dereference the identifier “x” - so we’re actually performing the LESS_OP operation on the dereferenced (reference to) an integer and a constant integer.
Therefore, the statement is type correct for its usage within this specific conditional statement.
After type checking the expression
x < 0our symbol table looks like this:
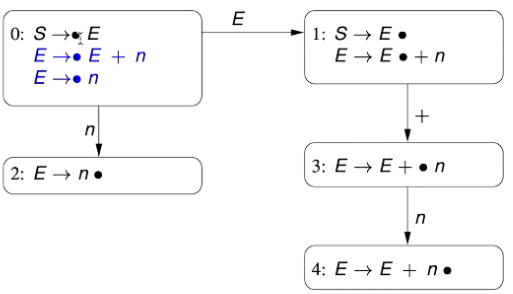
We then evaluate the expression
z := -xto check whether it’s well formed.The
AssignmentNodehas a left value ofIdentifierNode(”z”)and we need to resolve the identifier node’s reference just as we did forIdentifierNode(”x”)in the step above.By looking up the type of
Identifier(”z”)in our symbol table, we may discover that it has typeref(int)We now want to check the right child of the
AssignmentNodeto see whether it is an expression that evaluates to be the same type - the expression is the minus operator (MINUS_OP) being applied to the identifier “x”- The MINUS_OP takes an integer and returns an integer (
- Therefore, this expression should be well typed as long as the input value we’re passing it is an integer.
- We’ve already looked up IDENTIFIER(”x”) before and we know it’s an integer variable.
- It’s not exactly an integer, so we have to coerce it into an integer (this is done by dereferencing the integer).
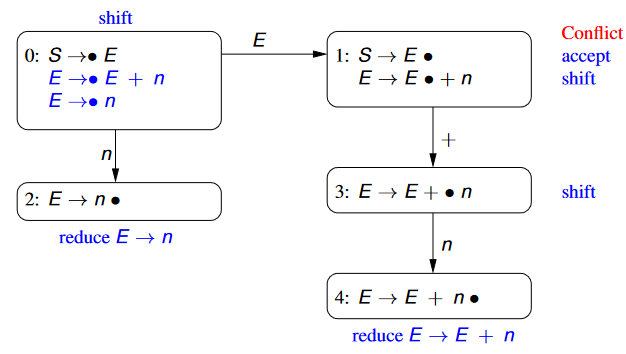
Likewise, we check the other assignment.
Example Summary
- Lexical Analysis of the sequence of program characters produced a sequence of lexical tokens
- Syntax Analysis of the sequence of lexical tokens was used to produced
- A concrete syntax tree (not actually produced by the compiler)
- An abstract syntax tree (AST)
- Static Analysis was used to:
- Resolve references to identifiers;
- Type check the abstract syntax tree
- Update the Abstract Syntax Tree with type coercions
5.0 - Context Free Grammars
5.1 - Writing Context-Free Grammars
The following context-free grammar has start symbol E, non-terminals and terminals
- Our grammar is defined using a set of symbols - there are two types of symbols
Non-Terminal SymbolsTerminal Symbols- The characters are tokens, and not syntax in BNF form
- If not explicitly stated, the start symbol is the left symbol in the very top production
- Our grammar is defined using a set of symbols - there are two types of symbols
This context-free grammar is written in EBNF (Extended Backus-Naur Form)
The
start symbolof a grammar is the left symbol in the topmost production (if not defined)
5.2 - Definition of Context-Free Grammars
A context-free grammar consists of
- A finite set, , of terminal symbols
- A finite nonempty set of non-terminal symbols (disjoint from the terminal symbols)
- Disjoint, not part of another set (i.e. a symbol cannot be both terminal and non-terminal)
- A finite nonempty set of productions of the form , where A is a nonempty terminal symbol and is a possibly empty sequence of symbols, each of which is either a terminal or non-terminal symbol
- A start symbol that must be a non-terminal symbol
A grammar defines a language; A language is a set of sentences.
- Each sentence is a finite sequence of terminal symbols in the grammar
- From before, our grammar can be (more concisely defined as)
🌱 This is a leftmost derivation, as at every step we choose to expand the leftmost non-terminal symbol
A leftmost derivation sequence for
3 + 4is given by:- Each sentence in the grammar can be derived from the start symbol, using a series of direct derivation steps.
- Direct Derivation - replace a non-terminal symbol by the right hand side of one of its productions. Use a double arrow to signify a direct derivation.
Recognise that E can expand to
E Op E, and3 + 4is of the formE Op ERecognise that we can replace the left hand E with its value
We now recognise that we can replace the Op with its respective symbol
And like before, we recognise that we can replace the symbol E with its respective number value
- Each sentence in the grammar can be derived from the start symbol, using a series of direct derivation steps.
A leftmost derivation sequence for
3 - 4 - 2is given by:- We recognise that we could express the sequence as
E Op E
At this point, notice that we have two options:
- Expand the leftmost
Eto (3-4) and the rightmost E to be 2 - Expand the leftmost
Eto 3 and the rightmost E to be (4 - 2) - Let’s expand the leftmost
Eto beE Op Eto have three productions
- Expand the leftmost
Recognise that the leftmost E can be expanded to a number (3)
Recognise that the next leftmost symbol is op - Let’s expand that to the symbol
-Recognise that the next leftmost non-terminal symbol is E, expand it to a number, 4
Recognise that the next leftmost non-terminal symbol is Op, expand it to -
Recognise that the next leftmost non-terminal symbol is E, expand it to 2
- We recognise that we could express the sequence as
5.3 - Directly Derives (Formal Definition)
Let both and be possibly empty sequences of terminal and non-terminal symbols, and N a nonterminal symbol
If there is a production of the form , then a derivation step can be applied to a sequence of symbols of the form to replace the N by the sequence to give the sequence .
We say directly derives
5.4 - Sequences of Derivations
🌱 We say that derives (i.e. ) if there is a sequence of direct derivations from to (this sequence being where and )
We say a sequence of terminal and nonterminal symbols derives a sequence , written
If there is a finite sequence of zero or more direct derivation steps starting from and finishing with .
That is, there must exist one or more sequences, such that,
Note that because zero steps are allowed, for any .
- For the example above, we have
5.5 - Nullable
A possibly empty sequence of symbols, is nullable if it can derive the empty sequence of symbols, i.e., written as one of the following
- Here, we use to denote the empty sequence of symbols
Typically, the derivation is preferred to as it may look like we’ve forgotten something.
- Rules for nullable
- is nullable (symbol can derive itself)
- Any terminal symbol is not nullable (no further derivations for a terminal symbol)
- A sequence of the form is nullable if all of the constructs is nullable.
- A set of alternatives is nullable if at least one of the alternatives is nullable.
- EBNF constructs for
optionalsandrepetitionsare nullable - A nonterminal N is nullable if there is a production for N with a nullable right side.
5.6 - Language Corresponding to a Grammar
The (formal) language corresponding to a grammar, G, is the set of all finite sequences of terminal symbols that can be derived from the start symbol of the grammar using its productions
where is the start symbol of and is its set of terminal symbols.
5.7 - Sentences and Sentential Forms
SentenceA sequence of terminal symbols such that is called a sentence of the languageSentential FormA sequence of terminal and non-terminal symbols , such that , is called a sentential form of the language- Hence, all sentences are also sentential forms
- Notice in the derivation shown on the right all of the derivation steps shown in green are
Sentential Formsbut are notSentences(as they contain non-terminal symbols. - In the derivation, also note that the derivation step in blue is both a
SentenceandSentential Form
6.0 - Language Examples
From the production, we know that the starting symbol is
- The shortest sentence in our language is
- Our language contains an infinite number of sentences, each with finite length
We have another infinite language, with an infinite number of sentences (each with finite length)
Once again, we have another infinite language, but this time, we can have the empty set.
This language has no symbols.
- The language is empty - there are no sentences as there are no derivations with terminal symbols only.
- Note the distinction between the example above, where the language contains the empty set and this example, where the language doesn’t contain any sentences
6.1 - Parse Trees
- A derivation sequence for a string in the language (a sentence) defines a corresponding parse tree
- A direct derivation step corresponding to the production generates a parse tree with as its root node and the symbols in as the children
- A derivation sequence generates a parse tree by applying each derivation step to progressively build the parse tree
- Note that two different derivation sequences may give rise to the same parse tree due to non-terminals being expanded in different orders.
Parse Tree Example
🌱 This is the parse tree for the previous example, where we try to parse
- When performing an in-order traversal of all of the leaf nodes, notice that we get
- As mentioned before, we could expand the
-before the firstEbut that would still yield the same parse tree. - We could also expand out the non-terminal terms in a different order, resulting in
6.2 - Ambiguous Grammars
🌱 In general, we don’t want our grammars to be ambiguous
Ambiguous Grammar for SequenceA grammar, , is ambiguous for a sentence, , in , if there is more than one parse tree forAmbiguous GrammarA grammar, is ambiguous if it is ambiguous for any sentence in- The following grammar is ambiguous:
- We always start by expanding the starting symbol E to E Op E
- From there, we could either:
- Expand the leftmost
EtoE Op E(Left associative) - Expand the rightmost
EtoE Op E(Right associative)
The following is an ambiguous grammar for expressions with the binary operator “-”, in which N represents a number.
💡 Key Idea is to add a new non-terminal symbol to break the symmetry of the production
To remove the ambiguity and treat “-” as a
left-associativeoperator as usual, we can re-write the grammar to- Add a new non-terminal symbol (T) - in this particular configuration, it forces the evaluation of any minuses from left to right as the symbol on the right has another layer of expansion to be performed before reaching the terminal symbol.
- This is as we have to evaluate E before evaluating T
And likewise to treat “-” as a
right-associative(not the usual interpretation) we use- This works as we have to evaluate E before evaluating T
Parse Tree Using Left-Associative Unambiguous Grammar
🌱 Creating a parse tree for the example using left-associative unambiguous grammar
- Note that the E on the second level (indicated here in orange) must expand to as this is the only way that we can have two minuses.
- Therefore, we expand from the left-hand side first.