Week 11.1
Week 11.1
🏷️ Replace this section with some keywords that can be used for searching, tagging and the indexing of this page.
Sections
🌱 Links to all Heading1 Blocks in this page.
- Regular Expressions
- Finite Automata (State Machines)
1.0 - Regular Expressions
1.1 - Defining Lexical Tokens using Regular Expressions
- In JFlex, we have:
Lexical tokens are specified via a regular expression
e.g. an IDENTIFIER token is specified as:
{Letter} ({Letter} | {Digit})*A regular expression is translated into a deterministic finite automaton (DFA) to recognise the tokens
DFA recognisers are very efficient (O(n) in the length of the input length n)
JFlex doesn’t directly produce a DFA - it first produces a non-deterministic finite automaton (NFA) which is then translated to a DFA to minimise size.
The DFA initially produced isn’t as small as it could be, and can be minimised to reduce the size further.
- For example, the following NFA (Left) and DFA (Right) are for matching the expression
- Non-Deteterministic Finite Automata are able to have transitions out of a state on the same symbol (e.g. transitioning out of state 1 to state 2 and 6 on the symbol )
1.2 - Regular Expressions Syntax
Regular Expressions are defined with respect to an alphabet (set of symbols)
🌱 The syntax of regular expressions in BNF is as follows
\ \ \ \ \ \ \ \ \ \ \ \ \ \ \def\rq{\text{'}} \def\or{\ |\ } e::=a\or\varepsilon\or\empty\or e\lq|\rq e\or e\ e\or e^{\lq*\rq} \or \lq(\rq\ e\ \lq)\rq
where a stands for a symbol from $\Sigma$. Repetition has higher precedence than concatenation, which has higher precedence than alternation. $a:$ Symbol from alphabet ($a\in\Sigma)$ $\varepsilon:$ Empty sequence of symbols $\empty:$ Represent matching of no input strings at all.
\def\rq{\text{'}} e\ \lq|\rq\ e:
Choice between two regular expressions $e\ e:$ Concatenation of regular expressions
\def\rq{\text{'}} e^{\lq * \rq}:
\def\rq{\text{'}} \lq(\rq\ e\ \lq)\rq:
Grouping of regular expressions - Note that regular expressions use ‘|’ to express alternatives, but is also used to represent alternatives in BNF. Hence the use of quotes around the symbol in the REGEX pattern matching string shown above. ## 1.3 - Language of Regular Expressions - Given an alphabet $\Sigma$, a regular expression defines a language (i.e. a set of strings of symbols from the alphabet). - Let “a” be a symbol, and $e, f$ be regular expressions
\def\rq{\text{'}}
\def\L{\mathcal{L}}
\begin{aligned}
\text{Regular Expression}\ &\ \ \ \ \ \ \text{Language}\\
\L(a)&=\{\lq a\rq\}\\
\L(\varepsilon)&=\{\lq\ \rq\}\\
\L(\empty)&=\{\}\\
\L(e|f)&=\L(e)\cup\L(f)\\
\L(e\ f)&=\L(e)^\frown\L(f)\\
\L(e^*)&=\cup_{n\in\mathbb{N}}(\L(e))^n\\
\L((e))&=\L(e)
\end{aligned}
$$
- Note here that the symbol indicates set concatenation. In this context, it means that we can take any string in language and concatenate it with any string in to form the new language.
- Note here in the second-last definition, the set is essentially formed by concatenating with itself times.
- In the last definition, the regular expression of a grouping is just the regular expression of the grouping itself.
1.3.1 - Concatenation of Languages
The concatenation of two languages (sets of strings), and is defined as the set of all strings formed by taking a string and and concatenating them.
For example:
1.3.2 - Iteration of Languages
The iteration of a language, to the power consists of concatenated with itself times.
For example, and
\def\rq{\text{'}} {\lq a\rq, \lq b\rq}^0 = {\lq\rq}\ {\lq a\rq, \lq b\rq}^1 = {\lq a\rq, \lq b\rq}\ {\lq a\rq, \lq b\rq}^2={\lq aa\rq, \lq ab\rq, \lq ba\rq, \lq bb\rq}\ {\lq a\rq, \lq b\rq}^3={\lq aaa\rq, \lq aab\rq , \lq aba\rq, \lq abb\rq, \lq baa\rq,\lq bab\rq,\lq bba\rq,\lq bbb\rq}
\def\rq{\text{'}} \begin{aligned} \mathcal{L}((a|b)^*)\ =\ {&\lq\rq, \ &\lq a\rq, \lq b\rq,\ &\lq aa\rq, \lq ab\rq, \lq ba\rq, \lq bb\rq,\ &\lq aaa\rq, \lq aab\rq, \lq aba\rq, \lq abb\rq, \lq baa\rq, \lq bab\rq, \lq bba\rq,\lq bbb\rq\ \ \ \ \ \ \ \ \ \ \ &\cdots} \end{aligned}
\begin{aligned}
&\color{gray}\text{iteration 0 times}\\
&\color{gray}\text{iteration 1 time}\\
&\color{gray}\text{iteration 2 times}\\
&\color{gray}\text{iteration 3 times}\\\\
\end{aligned}
- Note that this language does not include any infinite strings of symbols, because the iterations only generates finite concatenations # 2.0 - Finite Automata (State Machines) - A finite automata is a finite state machine consisting of a finite set of states, with labelled transitions between states - Each transition is labelled with either a symbol $(a\in\Sigma)$ or empty $(\varepsilon)$. - We distinguish between `deterministic` and `non-deterministic` finite automata - For a `deterministic finite automaton` (DFA), empty transitions are not allowed, and for each state and symbol, the next state (if there is one) is uniquely determined. - For a `nondeterministic finite automata` (NFA), empty transitions are allowed and there may be multiple transitions from a state to different next states on the same input symbol. - To create a DFA, we first create a NFA ## 2.1 - Deterministic Finite Automata (Formal) - A DFA, $D$ consists of - A finite alphabet of symbols, $\Sigma$ - A finite set of states, $S$ - A transition function, $T: \Sigma\times S⇸S,S$ which maps an (input) symbol and a (current) state to the (next) state; - The function T may not be defined for all pairs of symbol and state - Since the mapping may not exist for every symbol, state pair, we use the partial mapping symbol $⇸$ - A start state $s_0$ - A set of final (or accepting) states, $F$ --- 🌱 The language of a DFA is the set of strings that it can recognise. - The language $\mathcal{L}(D)$ of a DFA $D$ is the set of finite strings of symbols from $\Sigma$ such that $c\in\mathcal{L}(D)$ if and only if there exists a sequence of states $s_1, s_2, \cdots, s_n$ where $n$ is the length of $c,$ such that:
T(c_1,s_0)=s_1\\
T(c_2,s_1)=s_2\\
\vdots\\
T(c_n, s_{n-1})=s(n)\\
$$
- and is the start state and is in the set of final (or accepting) states, ’
- Through the concatenation of the labels , we should get the string that we’re trying to match.
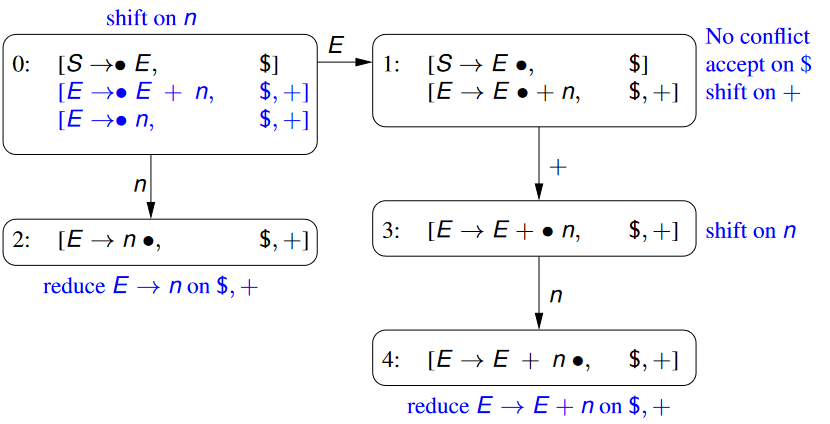
2.1.1 - DFA Example
- The following is a DFA as:
T(a,1)=2\ T(c,1)=4\ T(b,2)=3
- $s_0=1$ as denoted by the arrow pointing into the state (this is convention) - $F=\{3,4\}$ as denoted by the red double circles.  --- 🌱 What language (set of strings) does this DFA match?
\def\rq{\text{'}} \mathcal{L}(DFA)={\lq ab\rq, \lq c\rq}
\def\rq{\text{'}} {\lq ab\rq, \lq c\rq}
## 2.2 - Nondeterministic Finite Automata (NFA) 🌱 The differences between the formal definition of a DFA and NFA are very similar - the differences are highlighted here in green. - A NFA, N, consists of: - A finite alphabet of symbols, $\Sigma$ - A finite set of states, $S$ - A transition function, $T:(\Sigma\cup\{\varepsilon\})\times S⇸\mathbb{P}S$ which maps an input symbol or the empty string $(\varepsilon)$ and a current state to a set of possible (next) states; The function T may not be defined for all pairs of symbol and state - A start state, $s_0$ - A set of final (or accepting) states --- 🌱 The language of a NFA is the set of strings that it can recognise. This is similar to the definition of a language of a DFA. The differences are highlighted here in green. - The language $\mathcal{L}(D)$ of a NFA $N$ is the set of finite strings of symbols from $\Sigma$ such that $c\in\mathcal{L}(D)$ if and only if there exists a sequence $c'\in(\Sigma\cup\{\varepsilon\})^*$, such that removing all the $\varepsilon$ elements from $c'$ gives $c$ where $n$ is the length of $c',$ such that:
T(c_1,s_0)=s_1\\
T(c_2,s_1)=s_2\\
\vdots\\
T(c_n, s_{n-1})=s(n)\\
$$
- and is the start state and is in the set of final (or accepting) states, ’
- Through the concatenation of the labels , we should get the string that we’re trying to match.
- Empty transitions are used to generate the strings, but then omitted from the strings.
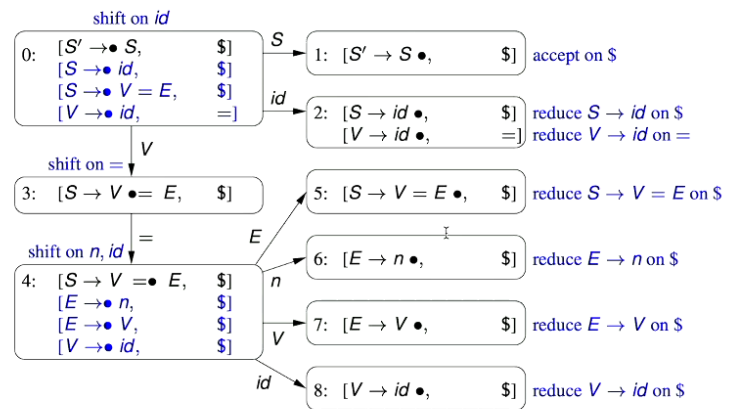
2.2.1 - NDA Example
- The following is a NDA as:
\begin{aligned} T(\varepsilon,1)&={2,6}\ \ \ \ \ \ \ \ \ \ T(b,3)&={4}\ T(c,6)&={7} \end{aligned} \begin{aligned} T(a,2)={3}\ T(\varepsilon,4}={5}\ T(\varepsilon,7}={5} \end{aligned}
- $s_0=1$ - $F=\{5\}$ 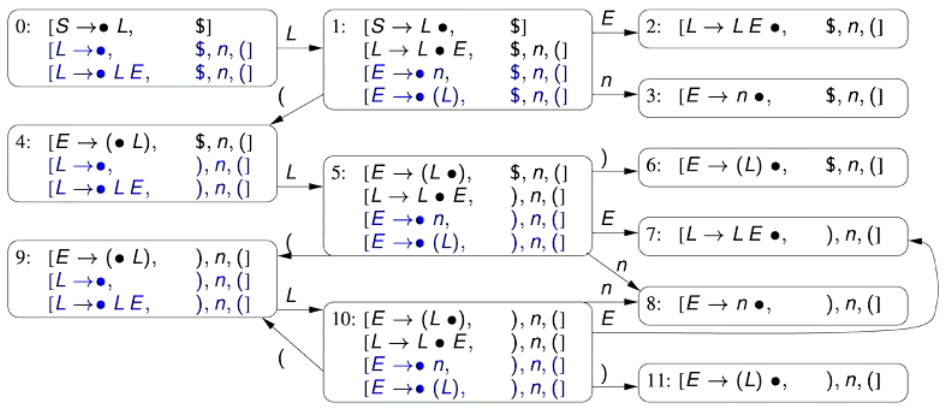 ## 2.3 - Converting a Regular Expression to NFA - The translation of a regular expression to a non-deterministic finite automaton is based on the structure of the regular expression - For each of the syntactic forms of regular expressions given in Definition 1, an NFA is given for that form. - If the syntactic form contains sub-expressions, (e.g. $e\ |\ f$ contains sub-expressions $e$ and $f$) the NFA for that form is constructed from the NFAs for the sub-expressions $e$ and $f$. 1. Single Symbol / Empty Transition 2. Concatenation 3. Alternatives 4. Repetition ### 2.3.1 - NFA for Single Symbol or Empty Transition 🌱 This is the NFA for matching a single symbol $a$ or empty transition $\varepsilon$ - Here, the final (accepting) states are indicated by a double circle. - Here, the topmost NFA matches the string $\def\rq{\text{'}}\lq a\rq$ - Additionally, the bottommost NFA matches the empty string, $\varepsilon$ 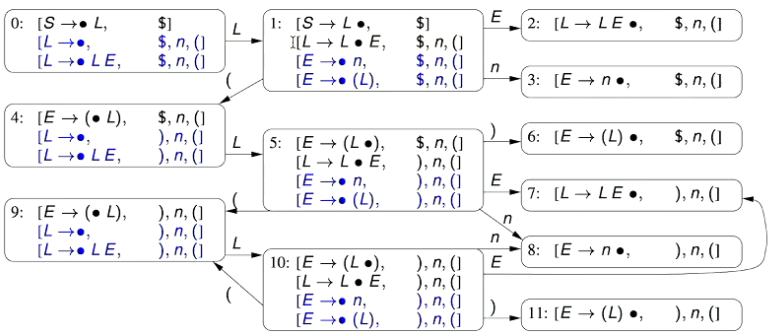 ### 2.3.2 - NFA for Concatenation 🌱 This is the NFA template for matching the concatenation of the expressions $e\ f$. 1. Firstly, we transform the expression $e$ into its NFA 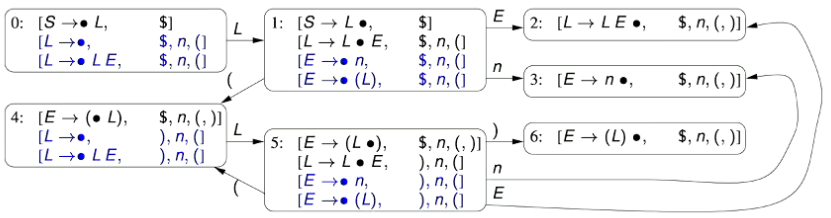 2. We next obtain the NFA for the expression $f$ 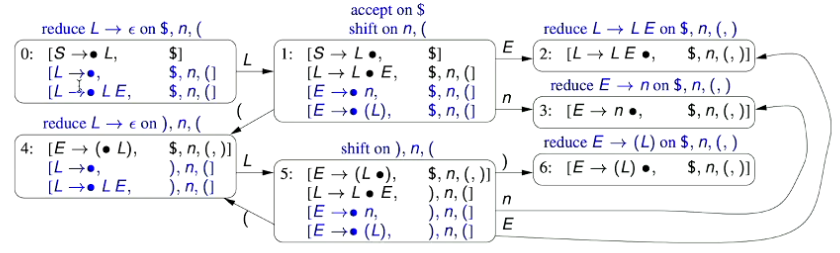 3. Joining the final state of expression $e$’s NFA to the start state of the NFA for expression $f$ gives the NFA for the concatenation of the expressions $e\ f$. - Note here that the final state of the NFA for expression $e$ is no longer a final state in the concatenated NFA.  ### 2.3.3 - NFA for Alternatives 🌱 This is the NFA template for matching the alternative expressions $e\ |\ f$ 1. Firstly, we obtain the NFA for the expression $e$  2. We similarly obtain the NFA for the expression $f$  3. Joining the two NFAs in the following configuration gives the following larger NFA for alternation  - Note that the final states of the NFAs for both $e$ and $f$are no longer final states in the larger NFA for $e\ |\ f$ ### 2.3.4 - Repetition 🌱 This is the NFA template for matching the repeated expression $e^*$ 1. Firstly, we obtain the NFA for the expression $e$  2. We the introduce a new start and end state: - The start state has the option to match the expression $e$ again, or jump to the start state - The old end state may loop back to the old start state, or jump to the new end state:  - We do this so that the repetition construct can match zero or more occurrences. ### 2.3.5 - NFA Example - Repetition and Concatenation 🌱 Construct the NFA for the Regular Expression $a\ b\ |\ c$ We want to construct the NFA for the regular expression $a\ b\ |\ c$. We recognise that the outermost construct is the alternative construct. To construct this NFA, we first need to create the NFAs for the sub-expressions $a\ b$ and $c$ 1. We first construct the NFA for the expression $a\ b$ - we recognise that this is a concatenation, and we first need to construct the NFAs for each of the sub-expressions 1. We first construct the NFA for the expression $a$  2. We the construct the NFA for the expression  3. Using the NFA concatenation rules, we join the two sub-NFAs into the NFA for matching the concatenation of expressions $a\ b$  2. We the construct the NFA for the expression $c$ - this is straightforward as we are only creating a NFA that matches a single character.  Joining these sub-expression NFAs using the alternation rule, we get: 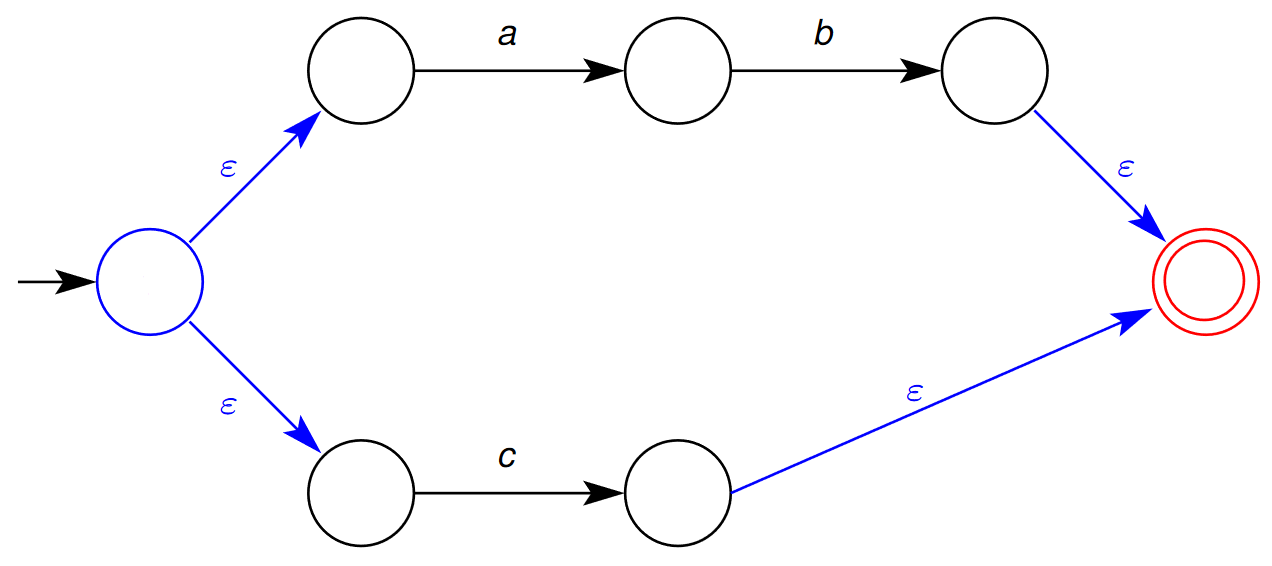 And, finally numbering the states: 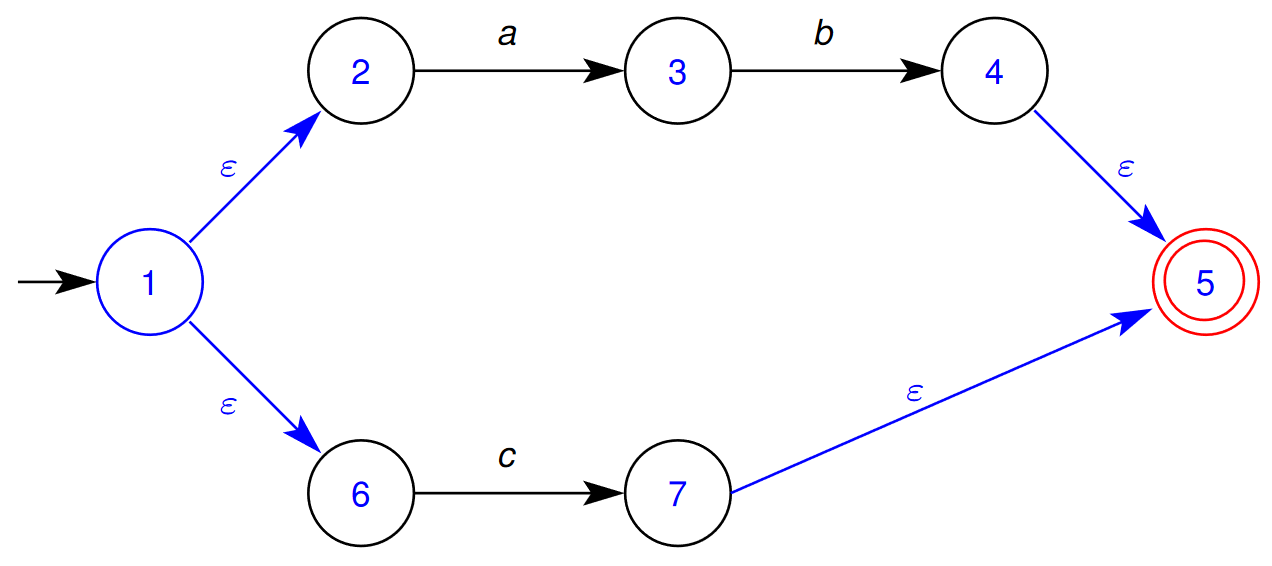 ### 2.3.6 - Example for Repetition of Alternatives 🌱 Construct the NFA for the Regular Expression $(a\ |\ b)^*$ 1. We first construct the NFA for the expression $a$  2. We the construct the NFA for the expression $b$  3. We then place the NFAs for expression $a$ and $b$ into the NFA for alternatives 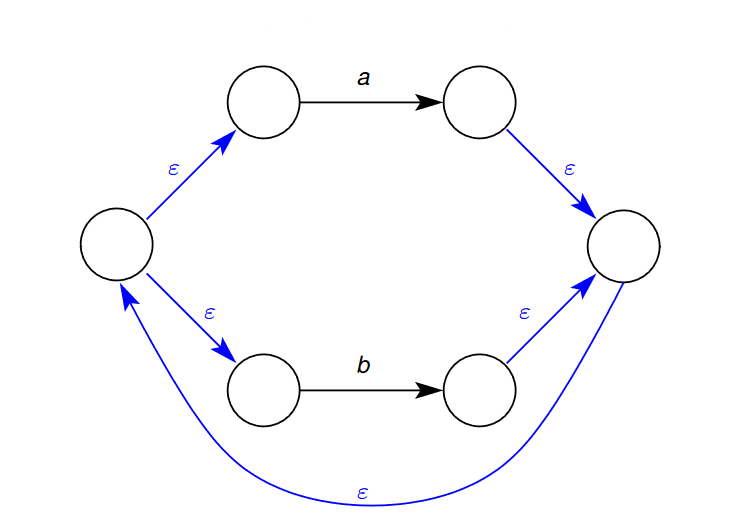 4. We then place the NFA for the expression $a\ |\ b$ into the NFA for 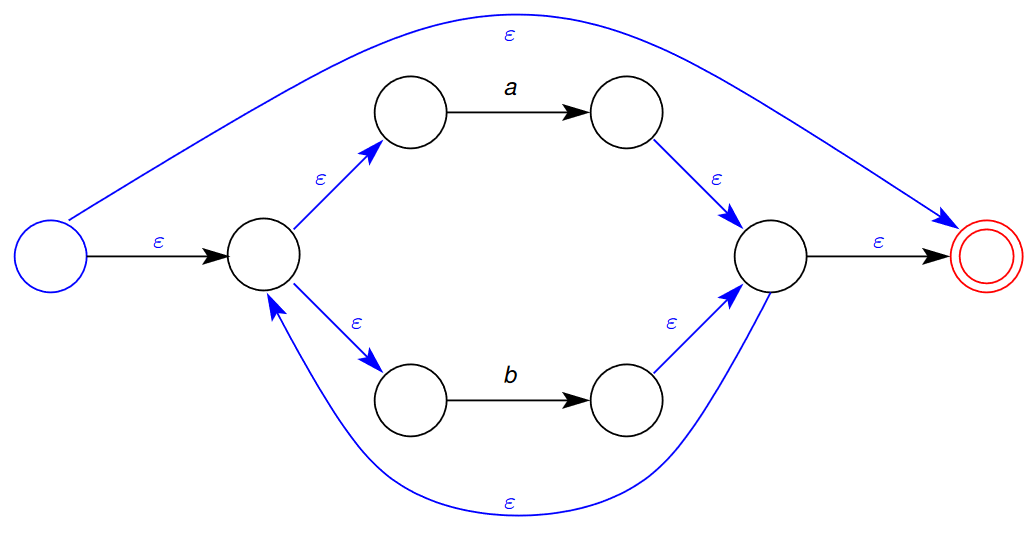 ## 2.4 - From Regular Expression to NFA In the translation from a regular expression, $r$ to an NFA, the generated NFA has a few properties that do not necessarily hold for an arbitrary NFA (i.e. one not generated from a regular expression) - The NFA has a single final (accepting) state - The initial state of the NFA only has outgoing transitions - The final state only has incoming transitions The translation rules preserve these properties. ## 2.5 - From NFA to DFA A DFA cannot have - More than one transition leaving a state on the same symbol - Any empty transitions A NFA N can be translated to an equivalent DFA $D$ - Equivalent in the sense that they accept the same languages, i.e. $\mathcal{L}(N)=\mathcal{L}(D)$ - That is, they can match the same sets of strings How is this done? - An NFA is transformed into a DFA in which the labels on the states of the DFA are sets of states from the NFA - The sets of states that label a DFA state are formed by collecting all the states that can be reached from NFA states by empty transitions. ### 2.5.1 - Empty Closure **Empty Closure of a State** - The empty closure of a state $x$ in an NFA $N$ $\varepsilon$-closure$(x,N)$, is the set of states in $N$ that are reachable from $x$ via any number of empty transitions **Empty Closure of a Set of States** - The empty closure of a set of sates $X$ in a NFA $N$, $\varepsilon$-closure$(x,N)$, is the set of states in $N$ that are reachable from any of the states in $X$ via any number of empty transitions:
\varepsilon-\text{closure}(X,N)=\bigcup_{x\in X} \varepsilon-\text{closure}(x,N)
$$
Empty Closure Example
🌱 What is the empty closure of the NFA shown?
| 1 | |
| 2 | |
| 3 | |
| 4 | |
| 5 | |
| 6 | |
| 7 |
- From state 1, we can go to state 2 or 6 only transitioning on . Therefore,
- From state 2, we can not go to any other states only transitioning on . Therefore,
- From state 3, we can not go to any other states only transitioning on . Therefore,
- From state 4, we can go to state 5 only transitioning on . Therefore,
- From state 5, we can not go to any other states only transitioning on . Therefore,
- From state 6, we can not go to any other states only transitioning on . Therefore,
- From state 7, we can go to state only transitioning on . Therefore,
2.6 - Constructing the DFA from the NFA
🌱 The first step in constructing the DFA from a NFA is determining the label of the start state.
The label of the start state of the DFA consists of the set of states containing the start state of the NFA plus all the states in the NFA that are reachable from its start state by one more more empty transitions:
The process for forming a DFA works with a set of unmarked DFA states by selecting an unmarked DFA state and considering all transitions from it on symbols
The initial set of unmarked states contains just
- Starting from the initial state, we go through every state that is reachable from the initial state.
The following process is repeated until there are no unmarked DFA states left.
- An unmarked DFA state is selected (the first one is )
- For each symbol a (every symbol in the alphabet)
- We consider the set of states that can be reached from any state in S by a transition on a call a;
- call this set of states X
- if X is nonempty, we add a new state to the DFA labelled with , unless a state with that label already exists (in which case it is re-used)
- A transition from to is added to the DFA
- The state is marked as having been processed.
2.6.1 - NFA to DFA Process - Simple Example
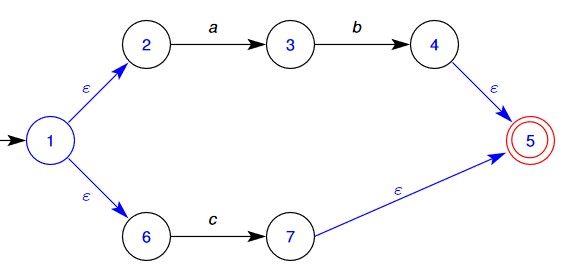
🌱 Consider the following NFA and follow the (above) process to turn it into a DFA
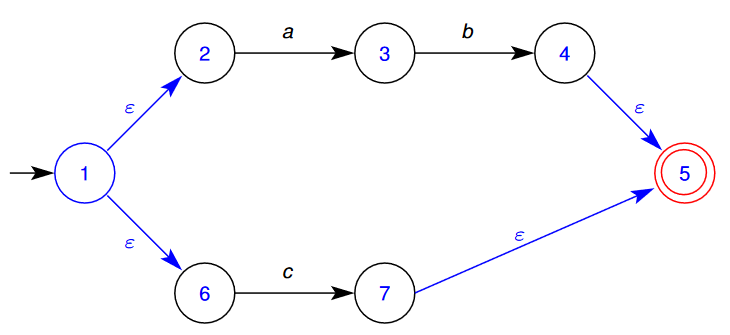
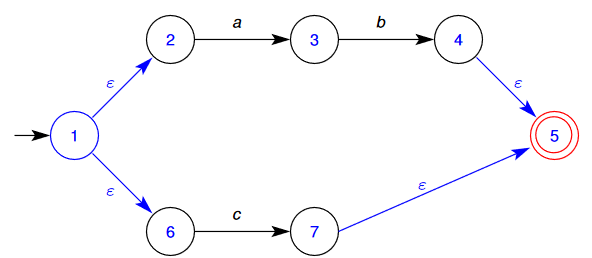
- The start state of the DFA is going to consist of the initial start state, and all of the states that can be reached by state 1 by empty transitions. That is, our new initial stages merges the old states
- We now need to determine what states can be reached from this new state:
- We can go from 2→3 on “a”
- We can go from 6→7 on “c”
- On that transition to state 3, we transition to a new state that is state 3 + any state that we can reach from state 3 + empty transitions.
- Since there are no such states, we just leave it as is
- We can transition out of this state on “b”
- On that transition to state 7, we transition to a new state that is state 7 + any empty transition.
- We can transition to state 5, therefore, the new state is
- Revisiting the transition out of state 3 on “b”, we can get to state 4
- This state also has a null transition to state 5:
- The states that include are final or accepting states as 5 was the original accepting state.
2.6.2 - NFA to DFA Process - Example 2
🌱 Consider the following NFA and follow the above process to turn it into a DFA for the REGEX statement for
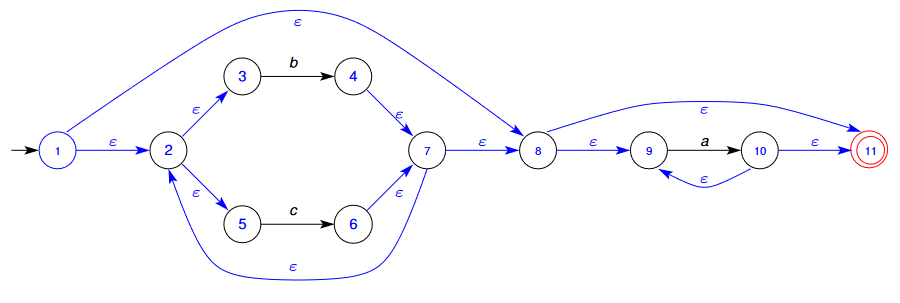
- We start from the initial state of the DFA.
- This state contains the NFA’s start state , and any state that we can get to via empty transitions
- Therefore, the empty closure of the start state is
- This means that the start state of the DFA merges these states from the NFA
- We now determine the transitions out of this state
- We have a transition out on as
- We have a transition out on as
- We have a transition out on as
- We now mark the initial state as seen or visited, and move to other states.
- We now consider the transition out of the initial state on :
- From NFA state 9, we can transition to state 10 on
- From state 10, we can get to state 11 and back to state 9 on empty transitions
- Therefore, the empty closure of this state is
- We now consider the transition out of the initial state on :
- From NFA state 4, we can transition to the following states on empty transitions:
- From this state, we can transition out on , from which takes us to a state containing the empty closure of 10 (which is the state above)
- From this state, we can transition out on , from which takes us to a state containing the empty closure of 4 (which is this state)
- From this state, we can transition out on , from which takes us to a state containing the empty closure of 6 (which is the state below)
- We now consider the transition out of the initial state on :
- From NFA state 5, we can transition to state 6 on
- From state 6, we can get to the following states on empty transitions: (this is state 6’s empty closure)
- From this state, we can transition out on , from which takes us to a state containing the empty closure of 10
- From this state, we can transition out on , from which takes us to a state containing the empty closure of 4
- From this state, we can transition out on , from which takes us to a state containing the empty closure of 6 (which is this state)
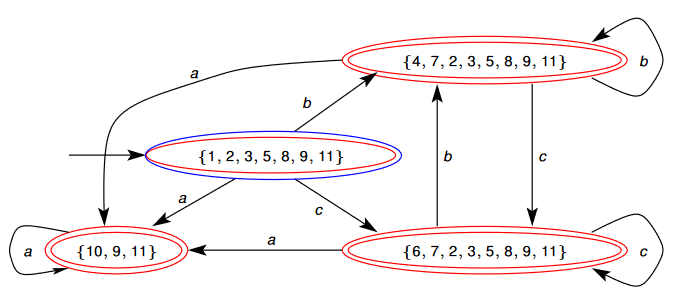
2.7 - Minimising a DFA
- The DFA generated in the above example can be simplified to one with only two states.
- To the right is a simplified version of the DFA with the states re-labelled to A, B, C and D
- To minimise the DFA, we merge states that have the same transition to equivalent states.
- For example, the states A, B and C are equivalent as they all:
- Transition out on onto
- Transition out on onto
- Transition out on onto
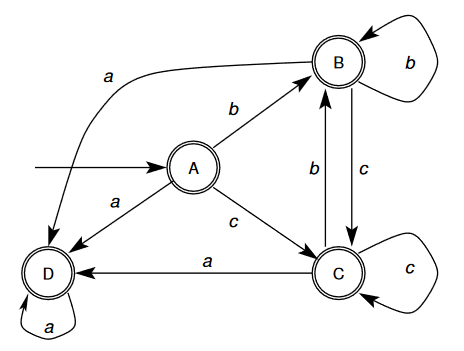
- Therefore, the DFA can be minimised:
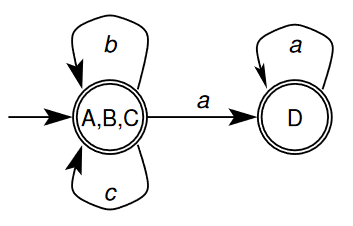
2.7.1 - Process for Minimising a DFA
Start by partitioning the states into a group of final states, and a group of non-final states.
For example, in the example above, all of the states are final states so we just get the one group
For each symbol we require all sates in a group to transition to the same group . For the example a transition on takes states back to the same group but there is no transition on from state , and hence we must split the group into groups and
Once that is done for every symbol , the transitions from all states in each group on are to the same group, and hence we have finished.
3.0 - Regular Expressions for Lexical Analyser
- The lexical analyser generator JFlex makes use of translating regular expressions into DFAs in order to build the scanner
- The input to the lexical analyser generator is a list of regular expressions, along with an action to be taken when that token is matched.
- The generated lexical analyser matches:
- The longest prefix of the input from the current position that matches any of the regular expressions in the list and
- If the prefix of the input matches more than one regular expression, the action associated with the first matching regular expression in the list is executed.
- For PL0, the string “end” followed by a blank matches both:
- The regular expression for the keyword “end” and
- The regular expression for an identifier
- The action selected for “end” is that for the keyword “end” because the regular expression for the keyword appears before the regular expression for an identifier
- The string “ending” followed by a blank matches only the regular expression for an identifier; it will not be split into the keyword “end” followed by the identifier “ing”
- But the string “end ing” will be matched as the keyword “end” followed by the identifier “ing”