Week 2.1
Week 2.1
🏷️ Replace this section with some keywords that can be used for searching, tagging and the indexing of this page.
Sections
🌱 Links to all Heading1 Blocks in this page.
- Context Free Grammars
- Chomsky’s Hierarchy of Grammars
1.0 - Context Free Grammars
1.1 - Recap of Context-Free Grammars
The following context-free grammar has start symbol E, non-terminals and terminals
- Our grammar is defined using a set of symbols - there are two types of symbols
Non-Terminal SymbolsTerminal Symbols- The characters are tokens, and not syntax in BNF form
- If not explicitly stated, the start symbol is the left symbol in the very top production
- Our grammar is defined using a set of symbols - there are two types of symbols
This context-free grammar is written in EBNF (Extended Backus-Naur Form)
The
start symbolof a grammar is the left symbol in the topmost production (if not defined)There must be a finite number of productions in the context-free grammar definition
The symbols on the left hand side of the productions are non-terminal symbols.
A grammar describes a language, in which a language is a set of sentences.
- Each sentence is a sequence of possibly-empty sequences in our grammar.
- Every sentence in the language can be directly derived from the start symbol of the grammar (through a series of direct derivation steps)
1.2 - Operator Precedence Example (Ambiguous Grammar)
The above grammar is ambiguous - in which order do we parse the following sentence?
Do we want these operators to be left associative or right associative?
What do we want the relative precedence of the operators to be?
🌱 Can you come up with two parse trees for the expression

Figure 1: Parse tree for 1 + 2 * 3, expanding the + operator first
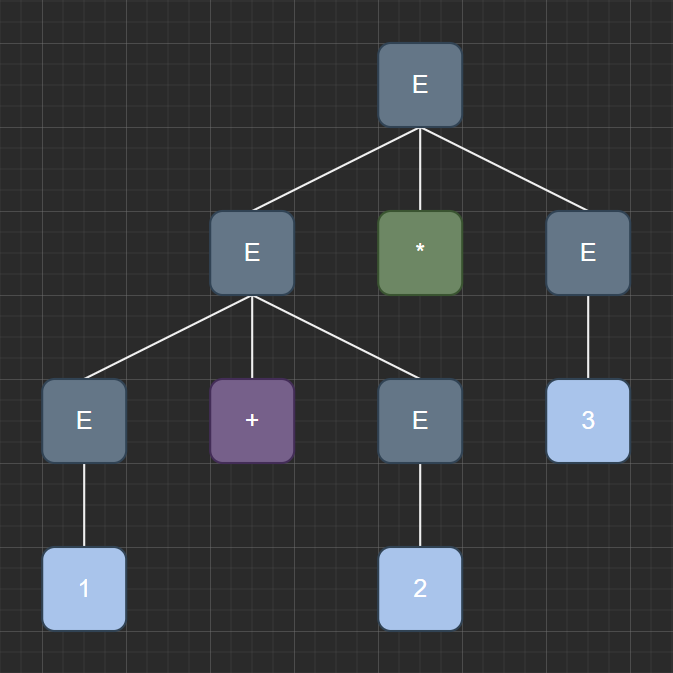
Figure 2: Parse tree for 1 + 2 * 3, expanding the * operator first
Note that in this example, the operator precedence is crucial for obtaining the right answer:
The “*” operator has higher precedence
The “+” operator has higher precedence
Observe here that the result of evaluating the two parse trees yield different numerical answers.
1.2.3 - Removing Ambiguity
🌱 Nodes further down in the parse tree (further away from the root node) get evaluated first. Therefore, operators with higher precedence should get chained further down in the productions.
Suppose that we want our operators to be left-associative (which we solved in the previous lecture) we need to solve the issue of operator precedence.
Consider the following grammar:
- We introduce a non-terminal symbol, T
- The production that defines T doesn’t have any addition in it - so we always do our rightmost addition operation first.
- We want the multiplication operation to be done first, so we add a new production for it.
- Notice that in the definition of the addition operation, we use the non-terminal symbol T
- This means that at the point in which we perform an addition operation,
- We have also introduced a new non-terminal symbol F, which enforces the left-associative nature of the multiplication operation.
- It is important that the production of F (and the subsequent productions) don’t have any occurrences of addition or multiplication in it.
- We introduce a non-terminal symbol, T
1.2.4 - Parse Trees and Grammar for 1*2+3
🌱 Using the grammar defined above, create a parse tree for the sentence
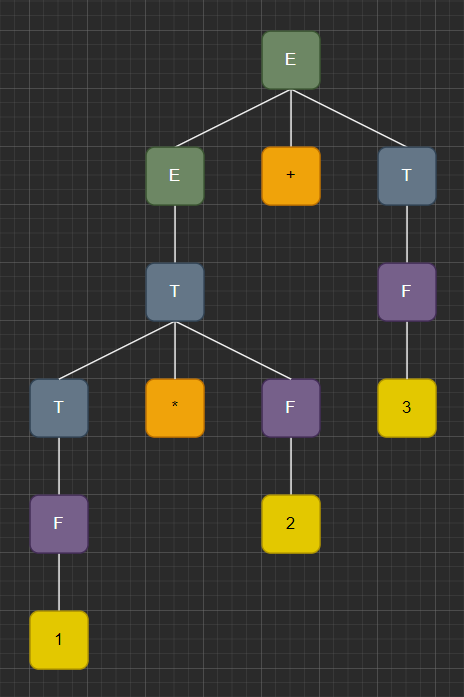
🌱 Using the grammar defined above, create a parse tree for the sentence
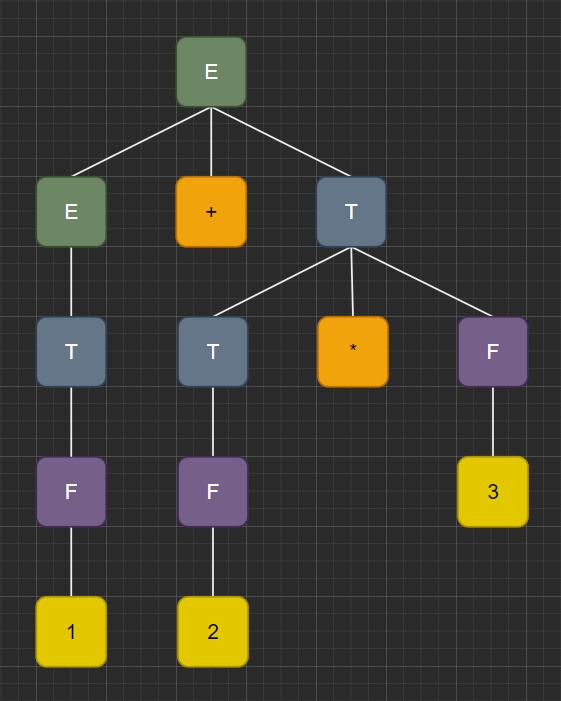
1.3 - Operator Precedence
- With a grammar like:
The precedence of the operators is not specified, so that a sentence like is ambiguous; it can be interpreted as either or where the brackets just show the grouping.
To ensure that “+” has a lower precedence than “*” and to remove that ambiguity, we can rewrite the grammar to:
- This grammar here also treats both operators as left associative.
- Note here that represents Number
1.3 - Overriding Operator Precedence Example
💡 Suppose we wanted to have the sentence in our language. How do we construct the parse tree for such a sentence? Note that by doing this, we’re essentially overwriting precedence using the parentheses.
We need to update our grammar to include the open and close parentheses
- Note here that represents Number
The parse tree should look something like this
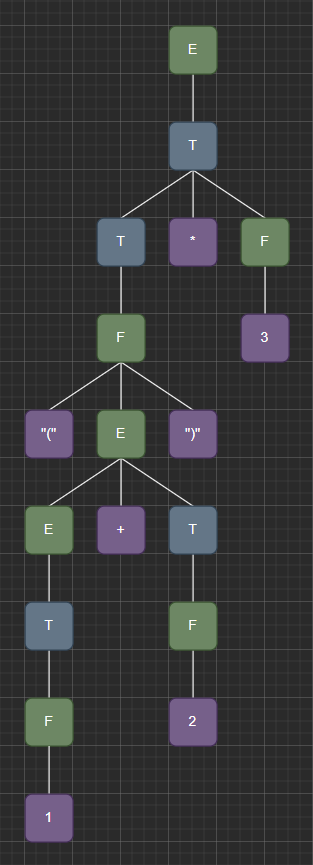
1.4 - Ambiguous Grammar for Lists
The following ins an ambiguous grammar for lists with elements corresponding to the nonterminal (not detailed here)
- Assume here that is some type of generic non-terminal symbol that we want to be able to create lists of.
For example, a sentential form corresponding to a single can be derived via the following three derivation sequences (as well as many others)
And here are the parse trees for the three different derivations.
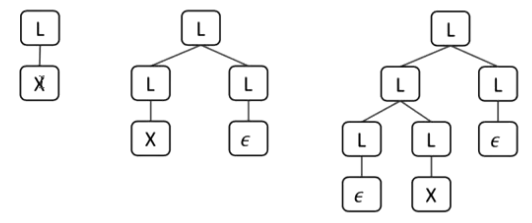
💡 This grammar that we’ve defined is ambiguous - how do we modify it such that the definition is not ambiguous
Suppose we modified our grammar from before from:
to:
Though this grammar is still ambiguous, we can only derive the sentence using two parse trees
(An improvement from before)
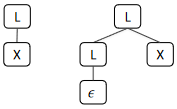
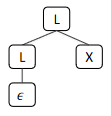
- Now suppose that we remove the middle production from our grammar:
- By this definition, there is only one possible parse tree for the production of the sentence
- Removing the production works as we already have a way of producing it through , where in the RHS of the equation,
In the above grammar, the production generates ambiguity because, if it is used in a derivation step, it generates containing , and then, for example either symbol (the left or the right ) may be expanded to get the same sequence .
The ambiguity can be resolved by replacing the production, with say:
In addition, the definition of our grammar as and together generate any sequence of zero or more occurrences of , including a single occurrence, meaning that the second alternative is redundant and introduces ambiguity.
An unambiguous grammar that generates the same language (set of sentences) is:
1.5 - Statement Sentence
Context Free Grammars for Programming Language Constructs - Statement Sequence
🌱 Define a grammar for a statement sequence, where each statement is separated by a semicolon (;)
- That is, our sentential forms are made out of the sentences:
- …
- These sentences can be generated using the following grammar:
🌱 Define a grammar for a statement sentence, where each statement is terminated by a semicolon (;)
These sentences can be generated using the following grammar:
- Essentially when each statement is generated inside the production, a complimentary delimiter is added.
1.6 - Other Common Idioms
🌱 Suppose you want to want to have a single symbol or sequence , followed by zero or more symbols or sequences of
- This means that you can generate as follows:
- You could have
🌱 Suppose you wanted zero or more occurrences of followed by a symbol
- Observe that all we’ve essentially done is swapped the position of or with
- i.e. from to
🌱 Programming Language Constructs - If Statement
In PL0, If Statements are currently specified as follows:
We can then add the option for an optional
elseportion:However, if we do this our grammar is ambiguous - consider the following sentence:
We have two possible parse trees generated for this statement.
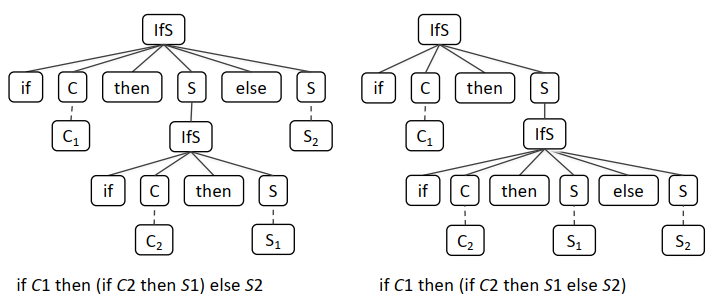
Ambiguity like this is possible in Java and C, and the ambiguity is resolved in the parser.
- Mistake made in the definition of ALGOL60
- In both languages, the else statements are always matched with its closest if.
- This would then generate the parse tree shown on the RHS
How do we implement the optional else statement without having any ambiguity
- Have brackets around the contents of the statements for the
thenandelsestatements.- E.g.
- Note that we don’t have to specifically have brackets - we could have
beginandendkeywords that indicate where sequences of statements start and end.
- Modify the grammars t o denote when each of the conditional statements have ended.
- Have brackets around the contents of the statements for the
2.0 - Chomsky’s Hierarchy of Grammars
- A significant amount of research has been put into characterising and describing the grammars.
- Chomsky’s Hierarchy of Grammars lists grammars in order of their expressivity.
Least ExpressiveType 3Left (or or right) Linear Grammars- Able to have productions of the following forms:
- Same expressivity as
Regular Expressions(REGEX) andFinite Automatons(State Machines) - Since we use REGEX to describe the formatting of our lexical tokens, and we use Context-Free Grammars to describe the grammars of our programming languages, this ultimately means that the language that we use to express our lexical tokens is less expressive than the language that we use to describe our programming language.
Type 2Context-Free Grammars- Have the same expressivity as
Pushdown Automatons(automaton with a stack)
- Have the same expressivity as
Type 1Context-Sensitive Grammars- You’re able to say “You’re able to replace with if and only if it is preceded by the sequence and proceeded by the sequence ”
- Note here that and being (sequence of empty symbols) is allowed.
- You’re able to say “You’re able to replace with if and only if it is preceded by the sequence and proceeded by the sequence ”
Type 0Unrestricted Grammars- In an unrestricted grammar, the only restriction is that
- Have the same expressivity as a
Turing Machine- we could describe any program as an Unrestricted Grammar.