Week 7.1
Week 7.1
🏷️ Replace this section with some keywords that can be used for searching, tagging and the indexing of this page.
Sections
🌱 Links to all Heading1 Blocks in this page.
- Bottom-Up Parsing
1.0 - Bottom-Up Parsing
- This is the theory that the Java-CUP Parser uses (Java-CUP generates a Bottom-Up Parser that uses a LALR(1) parsing scheme)
1.1 - Top-Down vs Bottom-Up Parsers
1.1.1 - Top-Down (Recursive Descent Parser) Example
Recursive Descent Parsers work top-down to recognise the input starting with a call to the parse method of the start symbol
For example, to parse ((a)) using the grammar
Step 1We start off with a parse call, toparseA()When matching the A, we recognise the open parenthesis, and recognise that we’re matching the alternative .
Step 2Therefore, we make another call toparseA().
Step 3The call toparseA()before recognises another set of parentheses, matching the alternative .- We make another call to
parseA(). Step 4The call toparseA()matches the alternative , returns and completes.Step 5Now, we’re completing the second call toparseA(), in which we match a closing parenthesis, return and complete that function call.Step 6We’re now completing the first call toparseA(), in which we match a parenthesis, return and complete- We reach the EOF symbol and we’re done.
1.1.2 - Bottom-Up Parsing (Shift/Reduce Parsing) Example
Shift/reduce parsers work bottom-up, starting from the input sequence of symbols, ending with the start symbol.
For example, to parse ((a)) using the grammar
Step 1We keep looking through the input until we get to the token ,Step 2We match the (as it matches the production ), so we construct the lowermost A node.Step 3We move along one token, and identify that the sequence matches the production
Step 4Based on the match identified in the step before, we construct the middle A node.Step 5We move along one token and see the matching closing parenthesis to and the other subsequent tokens to .Step 6Based on the previous match, construct the topmost A node, which is the start symbol. We stop.
1.2 - Bottom-Up Parsing: Shift-Reduce Parsing
- Shift/reduce parsers make use of a parse stack, and have three actions
ShiftPush the next input symbol onto the stackReduceIf a sequence of symbols on the top of the stack, matches the right side of some production , then the sequence on top of the stack is replaced by . Take something from the stack, and reduce it to the left-hand side of its production.- This type of action is called a reduction, because it goes in the opposite direction to a production
AcceptIf the stack contains just the start symbol and there is no input left, the input has been recognised and is accepted.
- There are actually other actions for errors, but they are dependent on the parsing scheme.
1.2.1 - Shift-Reduce Parsing Example
Parse “((a))” using the grammar:
S\rightarrow A\ A\rightarrow (A)\ A\rightarrow a
- When performing shift-reduce parsing, we introduce a new non-terminal symbol start symbol that produces our original start symbol to indicate that we’re finished with our parsing process. | Parsing Stack | Input | Parsing Action | Notes / Description | | --- | --- | --- | --- | | $ | ((a))$ | shift | The shift action takes the first item off the input, and pushes it onto the stack. | | $( | (a))$ | shift | | | $(( | a))$ | shift | | | $((a | ))$ | reduce $A\rightarrow a$ | We use the production $A\rightarrow a$ to reduce $a $ to $A$. Note that reduction is the inverse of a production (i.e. a production in the opposite direction). [1] | | $((A | ))$ | shift | [2] | | $((A) | )$ | reduce $A\rightarrow(A)$ | Use the production $A\rightarrow(A)$ to reduce $(A)$ to A. | | $(A | $ | shift | | | $(A) | $ | reduce $A\rightarrow(A)$ | | | $A | $ | accept | Since we’re at the end of our input, and the top of the stack is our initial start symbol, we can perform the accept action (rather than reduce $S\rightarrow A$) | [1] At this stage here, we could perform a shift operation, but then we’d get into a situation where no subsequent actions would lead to a solution [2] At this point here, we think we may be able to perform an accept action, as the last token matches our new introduced production $S\rightarrow A$. However, we can’t as we’re not at the end of our input. - Note that even initially, our parsing stack isn’t empty - we insert the $ symbol to indicate the bottom of the stack. - We use the same symbol at the end of our input to signify the end of the input # 2.0 - Shift/Reduce Parsing Schemes 🌱 Shift-Reduce Parsing Schemes define when to shift or reduce. - The trick to shift/reduce parsing is knowing when to: - `Shift` a terminal symbol onto the parse stack - this action is always possible unless one has reached the end-of file - Perform a `reduction` - this action is possible of the top of the stack matches the right side of any production. - There are a number of different schemes for determining how to choose between shift and reduce actions, including - LR(0) - SLR(1) - Simple LR(1), not covered in this course - LR(1) - LALR(1) - This is what Java-CUP Uses. - These schemes use parsing automaton to choose between actions. - We’re always in a parsing state, and the state indicates what action we should perform. ## 2.1 - LR(0) Parsing Scheme - L Parsing of the input is from Left-to-Right - R Parser produces a Rightmost-derivation sequence (i.e. in reverse) - 0 Zero symbol look-ahead (no lookahead) ### 2.1.1 - LR(0) Parsing Items - An LR(0) parsing item is of the form
N\rightarrow\alpha\bullet\beta
$$
- indicating that, in matching N, has been matched, and has been matched, where
- N is a non-terminal symbol
- and are possibly empty sequences of (terminal and non-terminal) symbols such that is a production in the grammar, and
- The “” marks the current position in matching the right hand side of the production
2.1.2 - LR(0) Parsing Automaton
An LR(0) parsing automaton (state machine) consists of
- A finite set of states, each which consists of a set of LR(0) parsing items
- Transitions between states, each of which is labelled by a symbol.
- If there is a transition from state to on a symbol , we say that is a
goto stateon on
- If there is a transition from state to on a symbol , we say that is a
- Each state in an LR(0) parsing automaton (with no conflicts) has one associated parsing action
We introduce a new start symbol - The kernel item of the initial state is
- Where is the start symbol of the grammar, and we introduce a fresh replacement start symbol and a new production .
- This fresh production is used to determine when parsing has completed.
- This production essentially says that we haven’t matched anything yet, but we want to match everything in the grammar (i.e. everything derived from the original start symbol)
Automaton States - Derived LR(0) Parsing Items
If a state has an LR(0) item of the form
Where the non-terminal M has productions
Then the state also includes the following derived items
Automaton Transitions - Goto States
If a state has an LR(0) item of the form
Where is either a terminal symbol or a non-terminal symbol, then there is a goto state, from the state on and includes a kernel item of the form
If there are multiple items in with the same immediately to the right of the , then the goto state includes all of those items, but with the right after that occurrence of rather than before it.
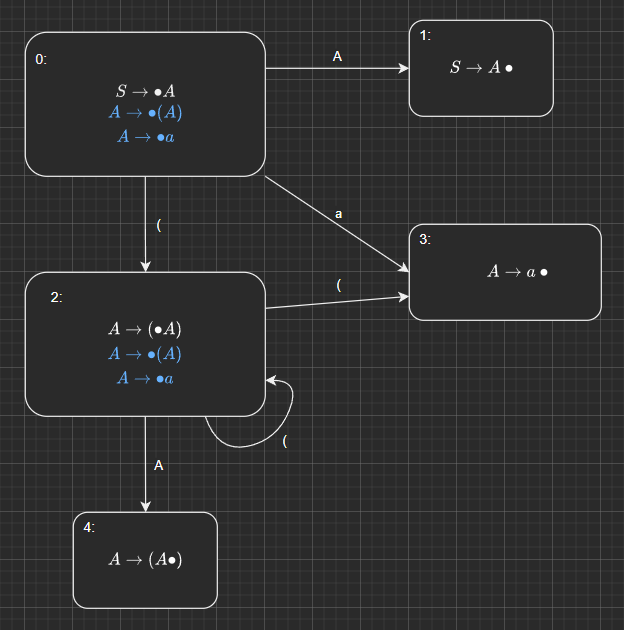
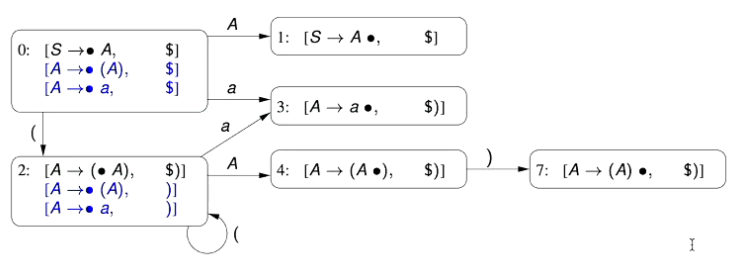
2.1.3 - LR(0) Parsing Automaton Example
🌱 Let’s generate the LR(0) Parsing Automaton for the grammar
Step 1: Start at the Start Symbol of the Grammar
We first introduce a new production which is a new production that produces the original start symbol
First, we create the initial state of our Automaton.
The first Kernel Item in our Automaton’s initial state is formed by the new production that we add.
We add our current position indicator, to the start of the RHS of this production to form the first kernel.
Since the position of our current indicator is to the left of the non-terminal symbol , and has two productions associated with it in the grammar, we have to add two derived items to the initial state.

Step 2: Transitions out of Initial State (#0)
- Note that we have three kernels in this initial state, in which the position indicator is to the left of the following symbols .
- Therefore, we must have transitions on these characters.
- The first transition out of the initial state, is derived from the first kernel; in this new state, we move the position indicator “over” the .
- The second transition out of the initial state is derived from the second kernel; in this new state, we move the position indicator “over” the parenthesis.
- The third transition out of the initial state is derived from the third kernel; in this new state, we move the position indicator “over” the token .
Step 3: Second State (#1)
This second state is derived from the first kernel in the initial state, .
In this new state, we have parsed , and therefore, move the position indicator to its right.
Since we are at the end of the sequence to parse, there are no more derived items or transitions out of this state.
Step 4: Third State (#2)
This third state is derived from the second kernel of the initial state, .
Since we transition on the parenthesis, we move the position indicator over the parenthesis
Since the position indicator is directly to the left of the non-terminal symbol , and there are two productions in the grammar with on the LHS, we have two derived kernels.
Step 5: Fourth State (#3)
This fourth state is derived from the third kernel of the initial state,
Since we transition on the token , we move the position indicator over the token, to the end of the production
Like the second state, since the position indicator is at the end of the production, there are no derivations or transitions out of the state.
Step 6: Transitions out of the Third State (#2)
Let’s revisit the third state, and look at the transitions out of it.
There are three kernels in this state:
- Note that in these kernels, the position indicator is directly to the left of the symbols respectively.
- Therefore, we will have transitions on these tokens.
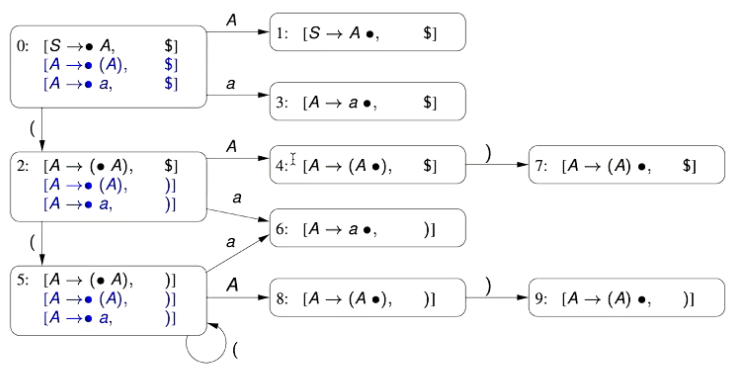
Step 7: Fifth State (#4)
The fifth state is derived from the first kernel of the third state - .
Since we transition on the non-terminal symbol , we move the position indicator over the symbol:
Since the positional indicator is immediately to the left of a terminal symbol, there are no derived kernels.
However, we have a transition, on the parenthesis token.
Step 8: ??Sixth State??
The supposed sixth state is derived from the second kernel item of the third state -
Since we transition on the parenthesis, we move the position indicator over it.
However, we notice that this identical to the kernel for the third state (#2) - therefore, we have a circular transition, back to the original state.
Step 9: ??Sixth State, Part II?
The supposed sixth state is derived from the third kernel item of the third state
Since we transition on the token we move the position indicator over it
We observe that this is the same kernel as State 4 (#3) so we make that link
Step 10: Sixth State, actually
The actual sixth state is derived from the only kernel of the fifth state,
Since we transition on the close parenthesis symbol, we move the position indicator over it
This new state doesn’t have any kernel derivations or transitions as the position indicator is at the end of the sequence to be matched.
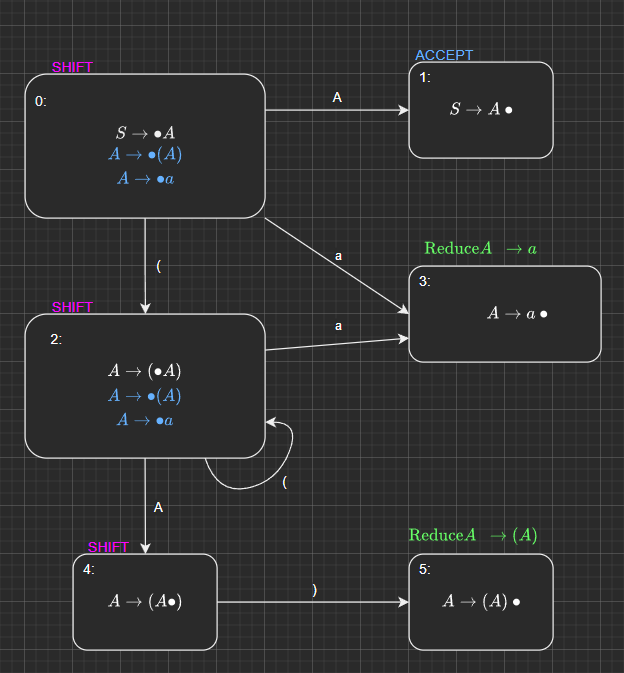
2.1.4 - LR(0) Parsing Actions
🌱 Which action do we associate with each state in the Parsing Action Automaton
An LR(0) item of the form
- , where is a terminal symbol indicates the state containing the item has a
SHIFTparsing action - , where is the (introduced) start symbol for the grammar, indicates that the state containing the item has an
ACCEPTaction - i.e. there is nothing further to match on its right side, where is not the (introduced) start symbol for the grammar, indicates that the state containing the item has a parsing action
REDUCE $N\rightarrow\alpha$- note that is a necessary part of the action.
A shift action at end-of-file is an error, as is an accept action when the input is not at the end-of-file
- Based on these, we can identify what action should be performed in each state of the automaton that we created before.
For State #0
- Since in the kernel , the position indicator occurs to the left of the terminal symbol ( which means that it has a
SHIFTparsing action. - Since in the kernel , the position indicator occurs to the left of the terminal symbol , which means that it has a
SHIFTparsing action (we already knew this from the kernel above
For State #1
- Since the new start symbol we introduced was , with the new production as . Therefore, we perform an
ACCEPTaction
For State #2
- Since in the kernel , the position indicator occurs to the left of the terminal symbol ( which means that it has a
SHIFTparsing action. - Since in the kernel , the position indicator occurs to the left of the terminal symbol , which means that it has a
SHIFTparsing action (we already knew this from the kernel above
For State #3
- Since in the kernel , since the position indicator is at the end of the production, which is NOT the start state production that we introduced, we perform a
REDUCE $A\rightarrow a$operation
For State #4
- Since in the kernel , the position indicator occurs to the left of the terminal symbol ), we perform a
SHIFTparsing action.
For State #5
- Since in the kernel , since the position indicator is at the end of the production, which is NOT the start state production that we introduced, we perform a
REDUCE $A\rightarrow (A)$operation
2.2 - Shift/Reduce LR(0) Parsing
🌱 We now combine the Shift/Reduce Parsing from before with the Automata defined in the section above
Now, the stack will not only contain tokens to parse, but also the current state that we are in.
Parsing Stack Input Parsing Action 1 $0 ((a))$ SHIFT 2 $0(2 (a))$ SHIFT 3 $0(2(2 a))$ SHIFT 4 $0(2(2(a3 ))$ REDUCE 5 $0(2(2(A4 ))$ SHIFT 6 $0(2(2(A4)5 )$ Reduce 7 $0(2A4 )$ SHIFT 8 $0(2A4)5 $ Reduce 9 $0A1 $ ACCEPT
- Note that in the previous iteration of parsing with a stack, we started off with the stack initially empty. In this version, we also push the state number. Here, we start in the initial state, which has a parsing action of
SHIFT - We perform the
SHIFTaction from the previous step, which puts us in State 2 (which we also pushed onto the stack). In State 2, the parsing action is aSHIFTaction. - We perform the
SHIFTaction from the step before, in which we remain in the same state (which is also pushed onto the stack). The parsing action from the second state is aSHIFTaction. - From the second state, we
SHIFTthe symbol onto the stack, which puts us in state 3. In this state, the parsing action isREDUCE $A\rightarrow a$. - We perform the reduce action from the previous state,
REDUCE $A\rightarrow a$. This action replaces the on the stack with , and we go back to the second state. However, since we’ve pushed an to the stack in the second state, we end up in the fourth state. This state has a parsing action ofSHIFT. - We perform the
SHIFTaction from the previous step, which pushes the closing parenthesis character onto the stack (along with the state number). The parsing action of this state isREDUCE $A\rightarrow (A)$ - We perform the
REDUCE $A\rightarrow (A)$action from the previous step, in which replace (A) with A. After performing the reduction action, we are in state 2 as our stack changes from to . We then push onto the parsing stack. This means that we are now in state 4 as we have pushed from state 2 (We push the new state onto the stack). This new state has a parsing action ofSHIFT - We perform the
SHIFTparsing action from the previous state, in which the parsing stack changes to $0(2A4)5 since we push a closing parenthesis onto the stack from the fourth state. This fifth state has the parsing actionReduce $A\rightarrow (A)$. - We perform the
Reduce $A\rightarrow (A)$parsing action from the previous state, in which we remove from the stack (which puts us in state 0). Whilst in state 0, we push onto the stack, which puts us in State 1 (which is the final state, indicating that our parsing process has finished).
2.2.1 - LR(0) Parsing Action Conflicts
- If a state in an LR(0) parsing automaton has more than one action, there is a parsing action conflict.
- Possible conflicts are:
Shift/Reduce Conflictif the state has both a shift action and a reduce actionReduce/Reduce Conflictif the state has two reduce actions with different productions, e.g. andShift/Accept Conflictif the state has both a shift action and an accept actionAccept/Reduce Conflictif the state has both an accept action and a reduce action
- Note that the only outcome for a state that has more than one action is Shift and Shift - there is no such thing as a
Shift/Shift Conflict.
🌱 A grammar is LR(0) if none of the states in its LR(0) parsing automaton contains a parsing action conflict.
2.2.2 - Parsing Automaton for a Grammar that is not LR(0)
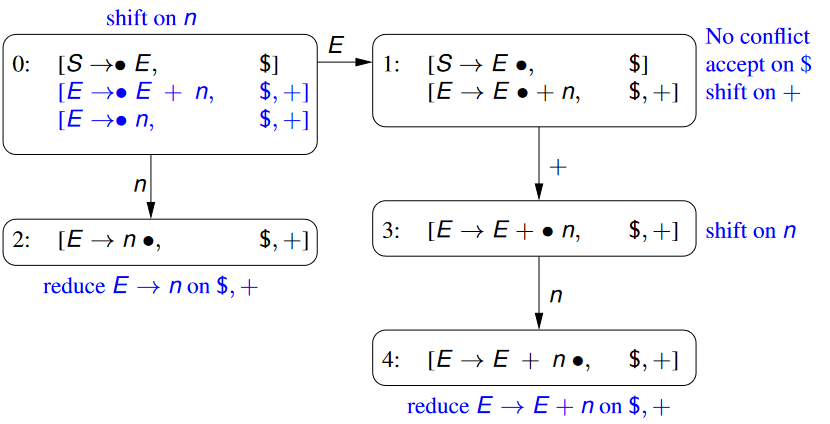
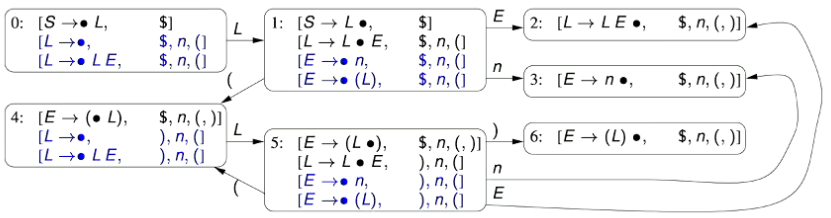
Consider the grammar, and its complementing Parsing Automaton
\begin{aligned} S&\rightarrow E\ E&\rightarrow E+n\ E&\rightarrow n \end{aligned}
- Note here that we’ve introduced a new start symbol / state $S$, and a new production $S\rightarrow E$ 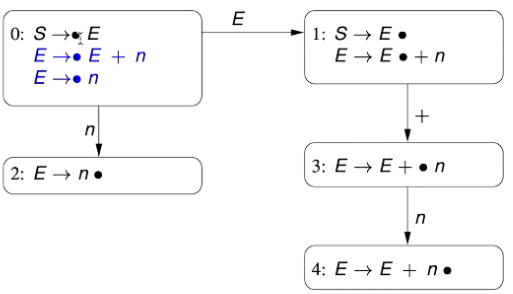 1. The initial state (State 0) has a kernel item that is formed by the new, introduced kernel $S\rightarrow E$ in which we place the position indicator $\bullet$ at the start, indicating that nothing has been matched yet
S\rightarrow\bullet E
$$
Since the position indicator is to the immediate left of the non-terminal symbol $E$, we need to include the two productions associated with $E$. Therefore, we add the following two derived items
$$
E\rightarrow\bullet E + n\\
E\rightarrow\bullet\ n
$$
Based on these three kernels, we know that our initial state has two transitions, on the symbols $E$ and $n$.
- We transition on $E$ for the kernels $S\rightarrow \bullet E$ and $S\rightarrow \bullet E + n$ (State 1)
- We transition on $n$ for the kernel $E\rightarrow\bullet n$ (State 2)
State 1 has two kernel items that have as the next character to match.
To update both of these kernel items, we update the position indicator to jump over the token . Therefore, our updated kernel items are:
There are no derived items for this state, as the position indicator is not to the left of any non-terminal symbols.
The second kernel item is to the left of the symbol . Therefore, we have a single transition, on the “+” symbol.
State 2 has a single kernel item, as identified earlier.
We update the kernel item by moving the position indicator over the matched token
This state doesn’t have any transitions, as the position indicator is at the end of the sequence to match
State 3 has a single kernel item, which is an updated version of the kernel item from the first state.
We update the kernel item by moving the position indicator over the matched token
We have one transition out of this state, on
State 4 has a single kernel item, as identified in State 3
We update the kernel item by moving the position indicator over the matched token
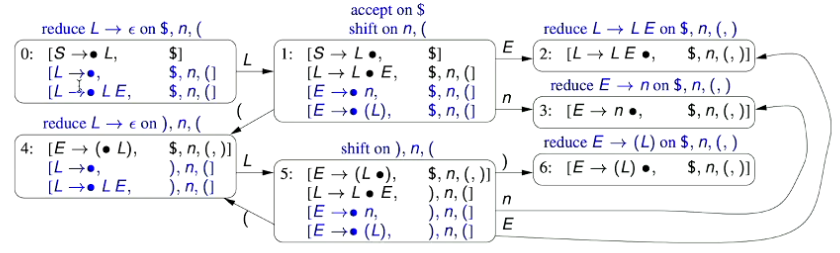
We now go back through the states, and assign an action for each state in the parsing automaton.
In State 0, we have the parsing items:
- Since our position indicator character is in front of the terminal symbol , we assign this state a
SHIFTaction.
- Since our position indicator character is in front of the terminal symbol , we assign this state a
In State 1, we have the parsing items:
- Based on the first parsing item, and the position of the position indicator, we should perform an
ACCEPTaction - Based on the second parsing item, and the position of its parsing indicator, we should perform a
SHIFTaction - Therefore, we have a conflict of actions in this state, and therefore the grammar is not LR(0)
- If we could use a single-symbol lookahead we could solve this problem - if the next symbol is EOF then accept, otherwise continue parsing.
- Based on the first parsing item, and the position of the position indicator, we should perform an
In State 2, we have the parsing items
- Since our position indicator character is at the end of the kernel, we perform a REDUCE action, on the kernel, i.e.
REDUCE $E\rightarrow n$ - Note that since is not our introduced start symbol, we don’t perform an accept action here.
- Since our position indicator character is at the end of the kernel, we perform a REDUCE action, on the kernel, i.e.
In State 3, we have the parsing item
- Since our position indicator character is before a terminal symbol , we perform a
SHIFTaction.
- Since our position indicator character is before a terminal symbol , we perform a
In State 4, we have the parsing item
- Since we’re at the end of this parsing item (and it isn’t the introduced start symbol), we perform a
REDUCE $E\rightarrow E+n$action
- Since we’re at the end of this parsing item (and it isn’t the introduced start symbol), we perform a
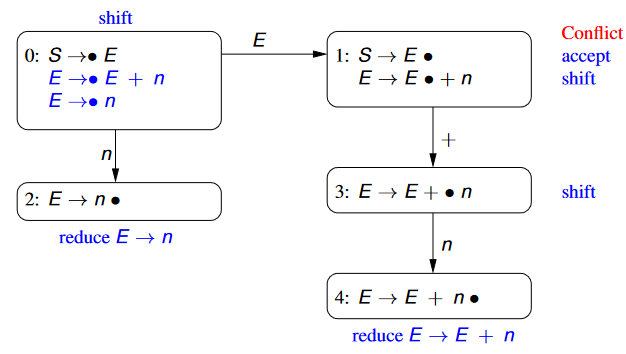
- Therefore, the (conflicting) parsing automaton for a non-LR(0) grammar is as follows