Week 7.2
Week 7.2
🏷️ Replace this section with some keywords that can be used for searching, tagging and the indexing of this page.
Sections
🌱 Links to all Heading1 Blocks in this page.
- LR(1) Parsing Scheme
1.0 - LR(1) Parsing Scheme
- The LR(0) parsing scheme that we looked at in the previous lecture uses a zero-symbol lookahead.
- The parsing items in LR(1) are extensions of the LR(0) parsing items.
- Most programming languages can be parsed using a LR(1) Parsing Automaton
1.1 - LR(1) Parsing Item
Each state in our LR(1) Parsing Automaton is comprised of sets of LR(1) Parsing Items.
An LR(1) Parsing Item is a pair:
- Where is an LR(0) parsing item, and;
- is a set of terminal symbols, called the look-ahead set (not to be confused with follow set)
A lookahead set may include , the special End-of-File symbol.
The above parsing item, indicates that in matching , has been matched and is yet to be matched in a context in which (and hence the right side of the production) can be followed by a terminal symbol contained in the set .
1.2 - LR(1) Parsing Automaton
- An LR(1) Parsing Automaton (State Machine) consists of
- A finite set of states, each of which consists of a set of LR(1) parsing items
- Transitions between states, each of which is labelled by a symbol. If there is a transition from state to on a symbol , then we say that is a goto state of on
- Each state in an LR(1) parsing automaton has associated parsing actions that are conditional on the value of the next terminal symbol in the input.
1.2.1 - LR(1) Parsing Automaton - Initial State
The kernel item of the initial state is
Where is the start symbol of the grammar, and we introduce a fresh replacement start symbol and a production . This fresh production is used to determine when parsing has completed.
The look-ahead for the initial kernel item is just the End-of-File symbol, ($) - once we finish matching everything (as everything can be derived from the start symbol), the next symbol is the End-of-File symbol.
1.2.2 - Automaton States - Derived LR(1) Items
If a state has an LR(1) item of the form
Where the non-terminal has productions
And then the state also includes the following derived items:
where if is not nullable, and if is nullable,
- If is nullable, the symbols that can follow are the union of:
- The set of symbols that can start () union-ed with the symbols that can follow (which is the set )
- If is nullable, the symbols that can follow are the union of:
1.2.3 - Automaton Transitions - Goto States
If a state has an LR(1) item of the form
where is either a terminal symbol or a non-terminal symbol, then there is a goto state, from the state on , and includes a kernel item of the form
1.2.4 - LR(1) Parsing Actions
LR(1) Parsing Actions differ from LR(0) parsing actions in that the action chosen depends on the next terminal symbol in the input, .
An LR(0) item of the form:
- where is a terminal symbol indicates that the state containing the item has a
SHIFTparsing action if the next input is a. - where is the added start symbol for the grammar indicates that the state containing the item has an
ACCEPTaction if there is no more input - it is at the end-of-file. - where is not indicates that the state containing the item has a parsing action REDUCE if the next input is in ; Note that the reduce action must specify the production
1.3 - Constructing an LR(1) Parsing Automaton for a Grammar
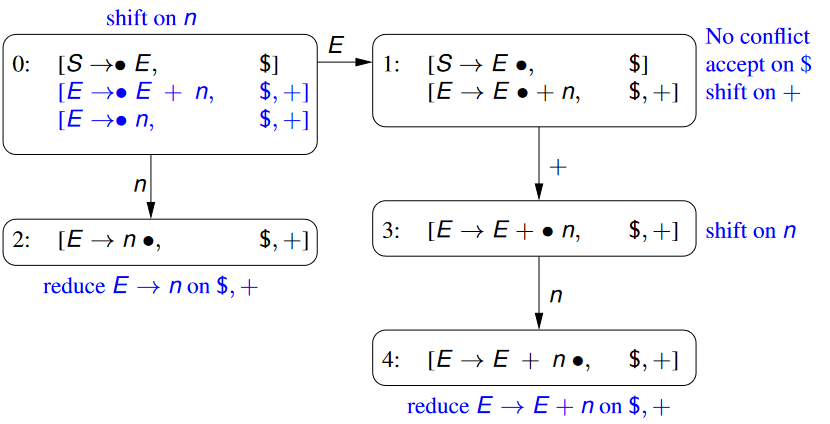
Consider constructing the LR(1) Parsing Automaton for the grammar
S\rightarrow E\ E\rightarrow E + n\ S\rightarrow n
1. **Construct the Initial State** - We start off the construction of the LR(1) Parsing Automaton with the starting state. - Our introduced starting symbol in this case is $S$, with the introduced production being $S\rightarrow E$ - Therefore, the first parsing item is given as follows. Note that for this first parsing item, no other symbols come after $E$, and therefore, the look-ahead set is just $\
$[S\rightarrow\bullet E, \$ ]$
- Our position indicator, $\bullet$ is to the left of the non-terminal symbol $E$ which has two productions
- Therefore, we have two additional derived parsing items:
- Note here that the look-ahead sets of these two derived parsing items contain the End-of-File symbol (from the original parsing item from which these were derived).
- We also have the $+$ symbol in our parsing items look-ahead sets - this is as we can derive symbols in the next steps with that symbol.
$$
⁍
$$
- In the three parsing items above, we have our position indicator character to the left of two symbols - $E$ and $n$.
- Therefore, we have transitions out of this state on those symbols, as they are the symbols to be parsed next.
- Our transitions are to State 1 (on the symbol $E$) and State 2 (on the symbol $n$)
Construct the First State
- This state has two parsing items; Updated versions of the parsing items from the previous state.
- We essentially just update the position of the indicator. The look-ahead sets remain the same.
Construct the Second State
We use the parsing item from the previous state (State 0), but update the position indicator to designate that we have matched the terminal symbol
There are no derived items in this state, as the position indicator is not to the left of any non-terminal symbol.
Construct the Third State
We use the parsing item from the previous state (State 1), but update the position indicator character to designate that we have matched the symbol
Since the position indicator character is to the left of the terminal symbol we transition on it to our next state.
Construct the Fourth State
As before, we use the parsing item from the previous state (State 3), but update the position indicator
There are no more go-to states (as we are at the end of the matching) and no derivations.
Define the Parsing Action for the Initial State.
Before, we determined that there are the following parsing items in the initial state:
We know that if the position indicator is directly to the left of a non-terminal symbol, then we perform the
SHIFTparsing action on
Define the Parsing Action for the First State (State 1)
Before, we determined that the two parsing items for the first state are:
If the next symbol is , then the next symbol is a non-terminal symbol and therefore, we perform a
SHIFTactionIf the next symbol is (End-of-File), we perform an
ACCEPTactionTherefore, there’s no conflict in this state (remember in the LR(0) Parsing Automaton we had an error in this state)
Define the Parsing Action for the Second State (State 2)
Before, we determined that the parsing action for the second state is:
Therefore, we
REDUCE $E\rightarrow n$if the next symbol is either or .Otherwise, an
ERRORaction is performed.
Define the Parsing Action for the Third State (State 3)
Before, we determined that the parsing action for the third state is:
As before, since the position indicator symbol is to the left of the non-terminal symbol , we perform the
SHIFTaction on .
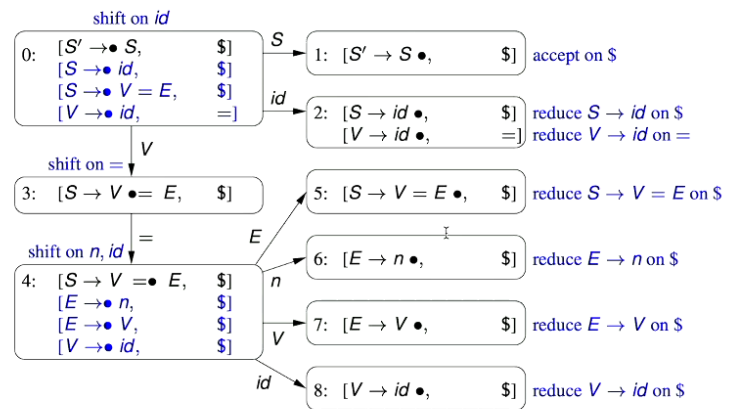
1.4 - Another LR(1) Parsing Automaton
Consider the following grammar, and its complimenting parsing automaton:
The first production is the introduced production, with our new introduced start symbol on the LHS and the original start symbol on the RHS.
The second production indicates that can either be a procedure call or an assignment statement to an expression
The third production indicates that expressions are either constant numbers or variables.
- The initial state, State 0 has:
Initial kernel item
Derived items:
We know this because the initial state uses the production for its kernel item, and the non-terminal symbol has two productions:
Therefore, we have an additional two kernel items:
\begin{aligned} &{[S\rightarrow \bullet \text{id}, }\ &{[S\rightarrow V=E} \end{aligned}
\begin{aligned}
\ \ \ \ \ \ \ \ \ &\$]\\
&\$]
\end{aligned}
- We know that the End-of-File symbol ($) follows $S$, as $S'\rightarrow S$ and $\$$ follows $S'$. Therefore, $\$$ must follow $S$ and therefore the lookahead set for these two kernel items is $\{\$\}$ - We now search for derivable items from the new kernel items. Notice that $S\rightarrow\bullet V$: - Therefore, we add that as a new kernel item of our state. The look-ahead set is just the symbol $=$, as in the production from which this kernel item is derived, $=$ follows $V$ $[V\rightarrow\bullet\text{id}, \ \ \ \ \ \ \ \ \ \ \ \ \ \ =]$ - From this, we have GOTO states on: - $S$ (from the initial kernel item) - $\text{id}$ from the first derived kernel item - $V$ from the second and third derived kernel item 2. The first state, State 1 has: - A single kernel item - this is the same as the kernel item from the initial state, except we update the position of the indicator symbol
[S'\rightarrow S\bullet, \ \ \ \ \ \ \ \$]
$$
- This state doesn’t have any derived items or GOTO states.
- The second state, State 2 has:
Two kernel items - both of these are updated versions of their respective kernel items from the initial state.
Neither of these kernel items have any derived items or GOTO states
- The third state, State 3 has:
A single kernel item - an updated version of the kernel item from the initial state
This kernel item doesn’t have any derived items
Since the position indicator symbol is to the left of the non-terminal symbol , we have a GOTO on .
- The fourth state, State 4 has:
A single kernel item from the previous state, State 3
Since the position indicator is to the left of the non-terminal symbol which has the productions and , we have an additional two derived kernel items:
In the second kernel item, notice that the position indicator is to the left of the non-terminal symbol , which has production implying that we have an additional derived kernel item.
- The lookahead set for this kernel is anything that can follow - we take this from the previous state’s kernel item.
From these four kernels, we have four GOTO states:
- GOTO State 5 on
- GOTO State 6 on
- GOTO State 7 on
- GOTO State 8 on
…
1.4.1 - Proving that a Grammar is LR(1)
- To prove that a grammar is LR(1) all we have to do is deduce the actions associated with each state (remember that a state may have more than one action) and prove that there are no conflicts.
- Note that in state 2 we have two different Reduce actions, based on two different productions.
- However, there is no conflict as we’re performing them on different next-symbols (i.e. the symbol that we’re looking ahead onto is different)
1.5 - LR(1) Parsing Action Conflicts
- If a state in an LR(1) parsing automaton has more than one action for a look-ahead terminal symbol, there is a parsing action conflict.
- If there is a conflict, we need to specify which action, state and symbol we have a conflict on
- The possible conflicts are similar to LR(0) parsing conflicts, and are:
Shift/Reduce Conflictif the state has both a shift action and a reduce action on the same terminal symbolReduce/Reduce Conflictif the state has two reduce actions with different productions, on the same terminal symbolShift/Accept Conflictif the state has both a shift action and an accept action on the same terminal symbolAccept/Reduce Conflictif the state has both an accept action and a reduce action on the same terminal symbol
- There is no such thing as a Shift/Shift Conflict.
1.6 - Non-LR(1) Grammars
The easiest way to derive a non-LR(1) grammar is to create an ambiguous grammar.
For example, show that the grammar above is ambiguous
S\rightarrow L\ L\rightarrow\epsilon\ L\rightarrow E\ L\rightarrow L\ E\ E\rightarrow n\ E\rightarrow (\ L\ )
- Here, we can derive a sentential form for $E$ two different ways: 1. $S\rightarrow L\rightarrow E$ 2. $S\rightarrow L\rightarrow L E \rightarrow \epsilon E \rightarrow E$ - When we attempt to create the LR(1) Parsing Automaton for this grammar, we get: - Also observe that we don’t have to create the entire parsing automaton to find a conflict - here we have a conflict in the initial state.  **Creating the LR(1) Parsing Automaton** 1. Begin by introducing our new start symbol to the grammar, and its production. - Here, we introduce the new start symbol $S$ and the production $S\rightarrow L$ 2. The initial state is based on the production $S\rightarrow L$. - Therefore, we have the following kernel item:
\begin{aligned}
&[L\rightarrow\bullet L
\end{aligned}
\begin{aligned}
\ \ \ \ \ \ \ \ \ \ \ \ \ \ \
\$&]\\
\end{aligned}
$$
- Note that the lookahead set is $\$$, as after we have finished parsing the original start symbol there should be an EOF.
- Since our current position indicator $\bullet$ is to the left of the non-terminal symbol $L$ in the first kernel item which has productions, we have derived items. More specifically, we have 3 additional derived items from $L$’s productions, $L\rightarrow\epsilon, L\rightarrow E, L\rightarrow L\ E$
$$
\begin{aligned}
&\color{gray}[S\rightarrow\bullet L\\
&[L\rightarrow\bullet,\\
&[L\rightarrow\bullet E,\\
&[L\rightarrow\bullet L\ E,\\
\end{aligned}
\begin{aligned}
\ \ \ \ \ \ \ \ \ \ \ \ \ \ \
\color{gray}\$]&\\
]&\\
]&\\
]&
\end{aligned}
$$
- Note that in each of these, the position indicator is at the start of matching the sequences.
- Deriving our lookahead set. We know that anything that can follow L is:
- Anything that can come after $S$ - that is the EOF symbol, $\$$
$$
\begin{aligned}
&\color{gray}[S\rightarrow\bullet L\\
&[L\rightarrow\bullet,\\
&[L\rightarrow\bullet E,\\
&[L\rightarrow\bullet L\ E,\\
\end{aligned}
\begin{aligned}
\ \ \ \ \ \ \ \ \ \ \ \ \ \ \
\color{gray}\$&]\\
\$&]\\
\$&]\\
\$&]
\end{aligned}
$$
- However, since the lookahead set is comprised of anything that can follow $L$ (and $E$ follows $L$ in the last kernel item, we need to include it.)
- $E$ can either start with $n$ (from $E\rightarrow n$) or an open parenthesis (from $E\rightarrow (\ L\ )$)
$$
\begin{aligned}
&\color{gray}[S\rightarrow\bullet L\\
&[L\rightarrow\bullet,\\
&[L\rightarrow\bullet E,\\
&[L\rightarrow\bullet L\ E,\\
\end{aligned}
\begin{aligned}
\ \ \ \ \ \ \ \ \ \ \ \ \ \ \
\color{gray}\$&]\\
\$,n,(&]\\
\$,n,(&]\\
\$,n,(&]\\
\end{aligned}
$$
- Additionally, in the fourth kernel item, the position indicator is to the left of the non-terminal symbol $E$, meaning that we have more derived items. We have 2 additional derived items, from the productions $E\rightarrow n$ and $E\rightarrow (\ L\ )$
$$
\begin{aligned}
&\color{gray}[S\rightarrow\bullet L\\
&[L\rightarrow\bullet,\\
&[L\rightarrow\bullet E,\\
&[L\rightarrow\bullet L\ E,\\
&[E\rightarrow\bullet\ n\\
&[E\rightarrow\bullet(\ L\ )
\end{aligned}
\begin{aligned}
\ \ \ \ \ \ \ \ \ \ \ \ \ \ \
\color{gray}\$&]\\
\$,n,(&]\\
\$,n,(&]\\
\$,n,(&]\\
&]\\
&]\\
\end{aligned}
$$
- The look-ahead set for $E$’s kernels are derived from the third and fourth kernel item, in which it is the last item. We propagate these changes.
$$
\begin{aligned}
&\color{gray}[S\rightarrow\bullet L\\
&[L\rightarrow\bullet,\\
&[L\rightarrow\bullet E,\\
&[L\rightarrow\bullet L\ E,\\
&[E\rightarrow\bullet\ n\\
&[E\rightarrow\bullet(\ L\ )
\end{aligned}
\begin{aligned}
\ \ \ \ \ \ \ \ \ \ \ \ \ \ \
\color{gray}\$&]\\
\$,n,(&]\\
\$,n,(&]\\
\$,n,(&]\\
\$,n,(&]\\
\$,n,(&]\\
\end{aligned}
$$
- GoTo States
- From this, we deduce that we have GOTO states on:
- (from the first and fourth kernel items)
- from the third kernel item
- from the fifth kernel item
- from the sixth kernel item
- From this, we deduce that we have GOTO states on:
- Parsing Actions
\def\spaces{\ \ \ \ \ \ \ \ \ \ \ \ \ \ } [L\rightarrow\bullet, \spaces$, n, (]
Reduce parsing action if the next symbol is $\$, n, ($. Based on production $L\rightarrow\epsilon$ -
\def\spaces{\ \ \ \ \ \ \ \ \ \ \ } [E\rightarrow\bullet n,\spaces$,n,(]
Shift on $n$ -
\def\spaces{\ \ \ \ \ \ } [E\rightarrow\bullet (\ L\ ), \spaces$,n,(]
Shift on $($ - Therefore, we have a conflict: - If our next symbol is $n$, we don’t know whether to Shift or Reduce $L\rightarrow\epsilon$ - If our next symbol is $($, we don’t know whether to Shift or Reduce $L\rightarrow\epsilon$ 🌱 Therefore, this grammar is ambiguous and not LR(1). Therefore, we can’t parse it using a LR(1) Parsing Automaton. ### 1.6.1 - Modifying a Non-LR(1) Ambiguous Grammar to a LR(1) Grammar - We can modify the grammar from above to be non-ambiguous
S\rightarrow L\ L\rightarrow \epsilon\ L\rightarrow L\ E\ E\rightarrow n\ E\rightarrow (\ L\ )
- Since this grammar is now LR(1), we can generate its LR(1) Parsing Automaton. 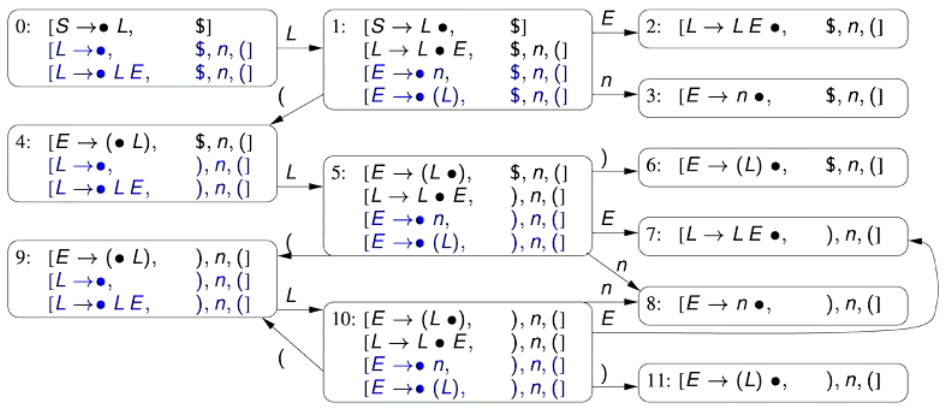 # 2.0 - LALR(1) Parsing Scheme - The same in terms of functionality as an LR(1) parsing automaton, but less states - therefore, more efficient - Retain the benefits of a LR(1) parsing scheme, and looking ahead one symbol, but with the added efficiency that comes from a simpler state machine. - Look-Ahead merged LR(1) Parsing - LALR(1) Parsing - The class of LALR(1) grammars is more restrictive than LR(1) grammars, but results in an automaton with less states - Each state of a LALR(1) automaton consists of a set of LR(1) automaton - An LALR(1) parsing automaton can be formed from an LR(1) parsing automaton by merging states that have identical sets of LR(0) items, but possibly different look-ahead sets. - Each item in the merged state consists of one of the LR(0) items in the states being merged with a look-ahead set that is the union of the look-ahead sets of that item in all the states being merged. - The parsing actions for LALR(1) parsing are the same as for LR(1) parsing. ## 2.1 - Generating a LALR(1) Parsing Automaton 🌱 We just need to figure out which states to merge. - In generating a LALR(1) Parsing Automaton, we merge states that have the same LR(0) parsing items (but potentially different look-ahead sets). - Consider the following grammar, and its associated LR(1) Parsing Automaton
S\rightarrow L\ L\rightarrow\epsilon\ L\rightarrow L\ E\ E\rightarrow n\ E\rightarrow (\ L\ )
\def\spaces{\ \ \ \ \ \ \ \ \ \ \ \ } [L\rightarrow L\ E\ \bullet,\spaces $, n, (, )]
\def\spaces{\ \ \ \ \ \ \ \ \ \ \ \ }[E\rightarrow n\ \bullet, \spaces$,n,(,)]
\def\spaces{\ \ \ \ \ \ \ \ \ \ \ \ } \begin{aligned} &[E\rightarrow(\bullet L\ ), \ &[L\rightarrow\bullet,\ &[L\rightarrow\bullet\ L\ E, \end{aligned}
\begin{aligned} \spaces$, n,(,)&]\ \spaces (,\ n,\ )&]\ \spaces (,\ n,\ )&]\ \end{aligned}
\def\spaces{\ \ \ \ \ \ \ \ \ \ \ \ } \begin{aligned} [&E\rightarrow (L\ \bullet),\ [&L\rightarrow L\ \bullet\ E,\ [&E\rightarrow\bullet n,\ [&E\rightarrow\bullet\ (L)\ \end{aligned}
\begin{aligned} \spaces $, n, (, )&]\ ), n, (&]\ ), n, (&]\ ), n, (&]\ \end{aligned}
[E\rightarrow (L)\ \bullet \ \ \ \ \ \ \ \ \ \ $, n, (, )]
Transitions are carried across to the new state. The new Parsing Automaton is given below;. 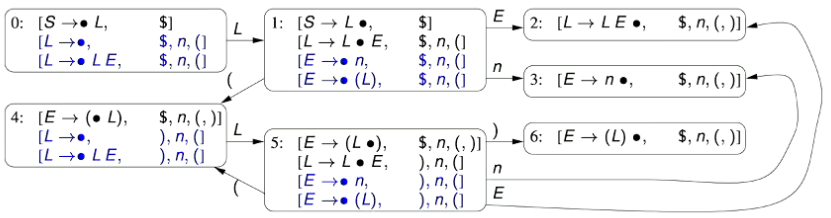 - When we merge together states to form a LALR(1) parsing automaton, we may introduce get conflicts. - The only type of conflicts that we can introduce are Reduce/Reduce conflicts (as that depends on the lookahead set). - We go through every state and figure out what the parsing actions are 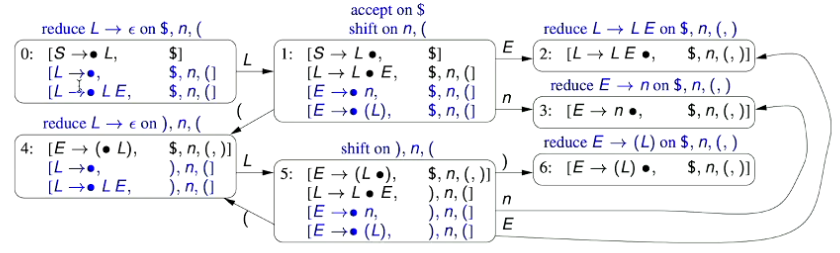 ### 2.2.1 - Another Example - Given the following grammar and its LR(1) Parsing Automaton, convert it to a LALR(1) Parsing Automaton.
S\rightarrow A\ A\rightarrow (\ A\ )\ A\rightarrow a
\def\spaces{\ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ }
\begin{aligned}
&[A\rightarrow(\bullet A),\\
&[A\rightarrow\bullet(\ A\ )\\
&[A\rightarrow\bullet a\\
\end{aligned}
\begin{aligned}
\spaces
\$,)&]\\
)&]\\
)&]\\
\end{aligned}
$$
State 3 - State 6 has the same LR(0) Parsing Items, so we combine these two states together, taking the union of their look-ahead sets.
State 4 - State 8 has the same LR(0) Parsing Items, so we combine these two states together, taking the union of their look-ahead sets.
State 7 - State 9 has the same LR(0) Parsing Items, so we combine these two states together, taking the union of their look-ahead sets.
Our condensed LALR(1) Parsing Automaton is given as follows
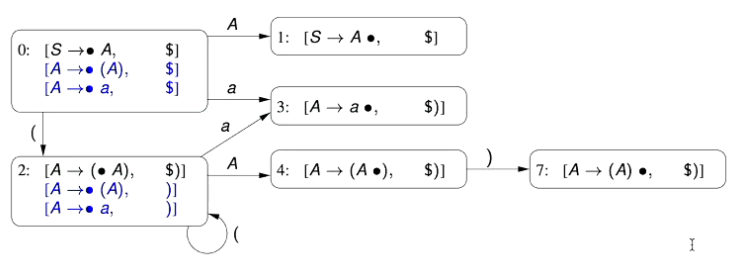
We then check what the parsing actions are, to ensure that the new Parsing Automaton doesn’t introduce any conflicts.