COMP4702 Chapter
COMP4702 Chapter
A summary of Lindholm Chapter 3
Note With Linear Regression, guaranteed to get the optimal solution (can be calculated in a single step using the closed form) but Decision Trees not guaranteed to get optimal solution (might get it by luck but not guaranteed)
Linear Regression
RegressionLearning the relationship between input variables and a numerical output variable .Inputs can either be categorical or numerical.
Goal is to learn a mathematical model :
- This function maps the input to the output
- is the error term that describes everything about the input-output relationship that cannot be captured by the model.
- Consider as a random variable, noise.
Linear Regression Model
- The linear regression model assumes that the output variable can be described as an affine [1] combination of the input variables plus a noise term .
- Refer to the coefficients as parameters of model.
- Refer to specifically as the intercept or offset term of the model.
- The noise term accounts for random errors in the data not captured by the model.
- Assumed that this noise is assumed to have a mean of 0 and to be independent of .
- A more compact representation of Eq. 3.2 is achieved by introducing a parameter vector, and extend the vector with a constant in the first position:
Note In this context, is used to denote the input vector matrix, both with and without the leading constant 1.
Additionally note that is a -vector, of error / noise terms.
Linear regression as in Eq 3.3 is a parametric function, in which the parameters can take any arbitrary values.
The values that we assign to the parameters control the input-output relationship described by the model.
The learning of the model is then attempting to find suitable values of based on observed training data.
Goal of supervised machine learning is to make predictions for new, previously unseen test input .
- Suppose parameter values have already been learned (here denotes that contains learned values of the unknown parameter vector )
[1] Affine Linear function plus constant offset
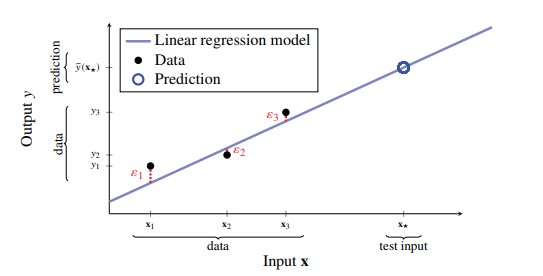 Figure 1 - Linear Regression with p=1. Black dots represent data-points, blue line represents learned regression model. Model doesn’t fit data perfectly, so remaining error corresponding to random noise ε for each data-point is shown in red. The model can be used to predict (blue circle) the output ŷ=𝐱★ for a test input 𝐱★
Figure 1 - Linear Regression with p=1. Black dots represent data-points, blue line represents learned regression model. Model doesn’t fit data perfectly, so remaining error corresponding to random noise ε for each data-point is shown in red. The model can be used to predict (blue circle) the output ŷ=𝐱★ for a test input 𝐱★
- Since we assume that noise term is random with zero-mean and independent of all variables, it makes sense to set for prediction.
- A prediction from a linear regression model is of the general form:
Training a Linear Regression Model
- Want to learn from training data with data-points with inputs and output in the matrix and -dimensional vector .
- Where each
Defining a Loss Function
We introduce a loss function, as a way to measure how
similarorwellour model fits the training data, denoted which measures how close the model’s prediction matches the observed data .If the model fits the data well (), then the loss function should be small, and vice versa.
Also define the cost function as the average loss over the training data.
Training a model amounts to finding the parameter values that minimise the cost:
- Where:
- is the loss function
- is the cost function.
- Note that each term in the expression above corresponds to evaluating the loss function for the prediction
- effectively means “the value of for which the cost function is the smallest”
Least Squares and the Normal Equations
- For regression, a commonly used loss function is the squared error loss:
- This loss function is 0 if and grows quadratically a the difference between and the prediction increases.
- The corresponding cost function for the linear regression model, shown in Eq 3.7 can be written using matrix notation as:
- Where denotes Euclidean vector norm, and denotes its square.
- This function is known as the least squares cost
- When using the squared error loss for learning a linear regression model from , we need to solve (Eq 3.12)
 
- We can denote this using Linear Algebra, in which we want to find the closest vector to in a Euclidean sense in the subspace spanned by the columns of .
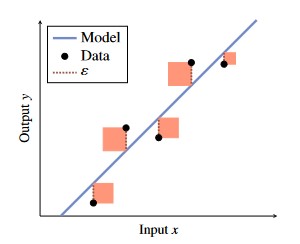 Figure 2 - Graphical Representation of Squared Error Loss Function.
Figure 2 - Graphical Representation of Squared Error Loss Function.
- Goal is to choose the model (blue line) such that the sum of squares (denoted in light red) of each error
- Equation 3.13 is often referred to as the normal equation and gives the solution to the least squares problem (eq 3.12).
- If is invertible (which is often the case), then has the closed form expression:
- The fact that this closed-form solution exists is important and is probably the reason for why linear regression + squared error loss is so common in practice.
- Other loss functions lead to optimisation problems that often lack closed-form solutions.
Goal Learn linear regression using squared error loss.
Data Training data Result Learned parameter vector,
- Construct the matrix and vector according to Eq 3.5
- Compute by solving Eq 3.13
Goal Predict with linear regression Data Learned parameter vector and test input Result Prediction
- Compute
Maximum Likelihood Perspective (Derivation of Least-Squares)
- We can get another perspective on the least squares method as a maximum likelihood solution
- In this context, the word likelihood refers to the statistical concept of the likelihood function
- Maximising the likelihood function amounts to finding the value of that makes observing as likely as possible.
- That is, instead of arbitrarily selecting a loss function, we start with the problem:
Here is the probability density of all observed outputs in the training data, given all inputs and parameters .
In defining what “likely” means mathematically, we consider the noise term as a stochastic variable with certain distribution
A common assumption is that the noise terms are independent, each with a Gaussian (normal) distribution with mean zero and variance
Stochastic Having a random probability distribution or pattern that may be analysed statistically but may not be predicted precisely.
- This implies that the observed data points are independent, and factorises as:
- Consider the linear regression model from (3.3), together with the gaussian noise assumption (3.16) yields the following:
- Recall that we want to maximise the likelihood with respect to . For numerical reasons, it is usually better to work with the logarithm of .
- Since the algorithm is a monotonically increasing function, maximising the log-likelihood (Equation 3.19) is equivalent to maximising the likelihood together. Combining Eq 3.18 and 3.19 yields:
\ln p({\bf{y}} | {\bf{X}} ; \theta) = -\frac{n}{2}\ln(2\pi\sigma_\varepsilon^2) \sigma{i=1}^n (\theta^T {\bf{x}}_i-y_i)^2 \tag{3.20}
- Removing the terms and factors independent of does not change the maximising argument. We can we-write 3.15 as:
\color{gray}\hat{\theta} = \arg \max_\theta p({\bf{y}} | {\bf{X}} ; \theta)\tag{3.15}
\begin{align*}
\hat{\theta}
&=\arg\max_\theta -\sum_{i=1}^n(\theta^T {\bf{x}}_i-y_i)^2\\
&=\arg\min_\theta\frac{1}{n} \sum_{i=1}^n (\theta^T {\bf{x}}_i - y_i)^2\tag{3.21}
\end{align*}
- We have just derived the equation for linear regression with the last-squares cost (the cost function implied by the squared error loss function, Equation 3.10).
- Hence, using the squared error loss is equivalent to assuming a Gaussian (normal) noise distribution in the maximum likelihood formulation
- Other assumptions on lead to other loss functions.
Categorical Input Variables
- The regression problem is characterised by a numerical output and inputs of of arbitrary type
- We can handle categorical inputs by first assuming that we have an input variable that takes two different values.
- We refer to these two values as and respectively, and then create a dummy variable as:
x=\begin{cases}
0&\text{if A}\\
1&\text{if B}\\
\end{cases}\tag{3.22}
- We use this variable in any supervised machine learning method as if it was numerical.
- For Linear Regression, this effectively gives is a model which looks like:
y=\theta_0 + \theta_1x + \varepsilon=
\begin{cases}
\theta_0+\varepsilon&\text{if A}\\
\theta_0 + \theta_1 + \varepsilon&\text{if B}\\
\end{cases}\tag{3.23}
- The model is thus able to learn and predict two different values depending on whether the input is or .
- If the categorical variable takes more than two values, say we can make a so-called one-hot encoding by constructing a four-dimensional vector:
{\bf{x}}
= \begin{bmatrix}
x_A & x_B & x_C & x_D
\end{bmatrix}^T
\tag{3.24}
- In which if and if and so on
- Only one element if will be 1, with the rest being 0
- This can be used for any type of supervised machine learning methods, not just linear regression
Classification and Logistic Regression
- Can modify the linear regression model to apply it to the classification
- Comes at the cost of not being able to use convenient normal equations, and have to resort to numerical optimisation / iterative learning algorithms
Statistical View of Classification
- Supervised Machine Learning amounts to predicting the output from the input
- Classification amounts to predicting conditional class probabilities, as in Eq 3.25
p ( y = m | {\bf{x}})\tag{3.25}
- describes the probability for class m given that we know the input .
- The notation implies that we think about the class label as a random variable.
- Because we choose to model the real world, where data originates as involving a certain amount of randomness (much like the random error in regression).
Example - Voting Behaviour using Probabilities
- Want to construct a model that can predict voting preferences for different population groups.
- Have to face the fact that not everyone in a certain population group will vote for the same political party.
- Can therefore think of as a random variable which follows a certain probability distribution
- If we know that the vote count in the group of 45 year old women is 13% of the cerise party, 39% for the turquoise party and 48% for the purple party, we could describe it as:
\begin{align*}
p(y=\text{cerise party} | {\bf{x}}=\text{46 year old women}) = 0.13\\
p(y=\text{turquoise party} | {\bf{x}}=\text{46 year old women}) = 0.39\\
p(y=\text{purple party} | {\bf{x}}=\text{46 year old women}) = 0.48
\end{align*}
- In this way the probabilities describes the non-trivial fact that:
- All 45 year old women do not vote for the same party,
- The choice of party does not appear to be completely random among 45 year old women either - the purple party is the most popular, and the cerise party ist he least popular.
- This, it is useful to have a classifier which predicts not only a class but a distribution over classes
- From the above example, we see the utility of predicting a probability distribution instead of just a single class.
- For binary classification problems () where we train a model for which:
p(y=1 | {\bf{x}}) \text{ is modelled by } g({\bf{x}}) \tag{3.26a}
- By the laws of probabilities, it holds that which means that
p(y=-1|{\bf{x}})\text{ is modelled by } 1-g({\bf{x}}) \tag{3.26b}
- Since is modelled for a probability, it is natural to require that for any .
- For the multi-class problem, we instead let the classifier return a vector-valued function where:
- Each element of corresponds to the conditional class probability .
- Since models a probability vector, we require that each element and for any .
Logistic Regression Model for Binary Classification
- Logistic Regression is a modification of the linear regression model so that it fits the classification problem.
- Begin with the case for binary classification, in which we wish to learn a function that approximates the conditional probability of the positive class.
- We begin with the linear regression model, which is given by the following equation (with noise term removed):
- This is a mapping that takes as input, and returns , which in this context is called the logit
- Note that , whereas we need a function which instead returns a value in the interval .
- The key idea is to use linear regression, and to squeeze from Eq 3.28 to the interval using the logistic function which is plotted in the figure below.
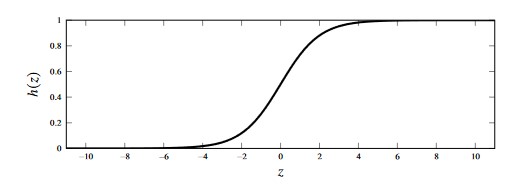
Figure 3 - Plot of the logistic function, given by h(z)=(e^z)/(1+e^z)$
- Substituting the logistic function into our equation for gives:
- Equation 3.29a is restricted to and hence can be interpreted as a probability.
- The function 3.29a is the logistic regression model for .
- Note that this equation also implicitly gives a model for .
- Fundamentally, the logistic regression model is the linear regression model with the logistic scaling function to scale the output at the end.
- Since logistic regression is a model for classification, we omit the loss term .
- The randomness in the classification data is modelled by the class probability class construction instead of additive noise
Training Logistic Regression Model by Maximum Likelihood
- Whilst the addition of the logistic function allows us to use linear regression for binary classification, it means that we cannot use the normal equations for learning due to the non-linearity of the logistic function
- Therefore, to train the model, we learn from the training data using the maximum likelihood approach
- Using this Maximum Likelihood approach, learning a classifier amounts to solving the following equation:
- Equation 3.30 is similar to the training solution for linear regression, in which we assume that all training data-points are independent, and we consider the logarithm of the likelihood function for numerical reasons
- Added explicitly to the notation to emphasise dependence on model parameters.
- Our model of is , which means that we can re-write the log-likelihood component as follows:
- We can turn the maximisation problem into a minimisation problem by using the negative log-likelihood as a cost function.
- Note here that the loss that we have derived is the cross-entropy loss.
- For the logistic regression model, we can re-write the cost function given in (Eq 3.32) in greater detail.
- We consider the case where the binary classes are labelled as .
- For , we write:
- And similarly for , we write:
- Observe how in both cases we get the same expression
- Therefore, we can write (Eq 3.32) compactly as:
- The loss function shown above (which is a special case of cross-entropy loss) is called the logistic loss (or binomial deviance).
- Learning a logistic regression model then results to solving the following equation to find the optimal
- Unlike linear regression, logistic regression has no closed-form solution so must result to numerical optimisation instead.
Logistic Regression Predictions and Decision Boundaries
Thus far have developed a method for predicting the probabilities for each class for some test input .
- Sometimes we just want the best class prediction the model can make without consideration for the class probabilities.
- This is achieved by adding a final step to the logistic regression model which converts the predicted probabilities into class prediction
- The most common approach is to let be the most probable class
- For the binary classification problem, this can be expressed as shown below.
- Note that the decision at is arbitrary.
Logistic Regression Pseudocode
Learn binary logistic regression
Data: Training data with output classes
Result Learned parameter vector
- Compute by solving (Eq 3.35) numerically
Predict with binary logistic regression
Data Learned parameter vector and test input
Result Prediction
- Compute using (Eq. 3.29)
- If then return else return
- In the general case, the decision threshold is appropriate.
- However, in some applications it can be beneficial to explore different thresholds
- minimises the misclassification rate, however, it is not always the most important aspect of a classifier
- For example, it can be more important to mistake a healthy patient as sick (false positive) instead of predict a sick patient as healthy (false negative).
- The addition of class prediction probabilities essentially allows the models to have an “I don’t know” option
Logistic Regression with Multiple Classes
We can generalise logistic regression to the multi-class problem, where .
One approach is to use the softmax function
For the binary classification problem we designed a model which return a single scalar value representing .
For the multi-class problem, we have to instead return a vector-valued function whose elements are non-negative and sum to 1.
- We initially use instances of (Eq 3.28, equation for simple linear regression) and denote each instance , with its own set of parameters .
- We stack all instances of into a vector of logits and use the soft-max function to replace the logistic function
- Essentially, use soft-max on the vector of logits instead of the logistic function on each model.
- The softmax function takes in a -dimensional vector, and returns a vector with same dimensionality.
- The output vector from the softmax function always sums to 1, and each element is .
- We use the softmax function to model the class probabilities (similar to the use of the logistic function in the binary classification case).
- We can also write out the individual class probabilities (i.e., elements of vector ) as:
- Note that this construction uses parameter vectors , which means that the number of parameters that need to be learned grows as increases.
Training Logistic Regression with Multiple Classes
- As with the binary logistic regression model, we can use the concept of maximum likelihood to train our model.
- For this, we will use to denote all model parameters, .
- Since is our model for , the cost function for the cross-entropy loss for the multi-class problem is given as:
- Note that this multi-class cross-entropy loss is denoted
- We can insert the model we developed in (Eq 3.43) into the loss function (Eq 3.44) to give the cost function to optimise for the multi-class logistic regression problem.
Polynomial Regression and Regularisation
Linear and Logistic Regression may appear rigid and non-flexible compared to -NNs and Decision Trees as they are comprised of purely straight lines
However, both models are able to adapt to the training data well if the input dimension is large relative to the number of data points .
We can increase the input dimension by performing a non-linear transformation of the input.
A simple way of doing this is to replace a one-dimensional input with itself raised to different powers (which turns this into polynomial regression)
- The same can be done for the logit in logistic regression.
Consider that in the original linear regression model, if we let , this is still a linear model, with input
- However, in doing this, the input dimensionality has increased from to .
Non-linear input transformations can be very useful, but it effectively increases and can easily over fit the model to noise.
In the car stopping example, we have our original data, and add a for the offset, term, and for the second order term to produce a new matrix
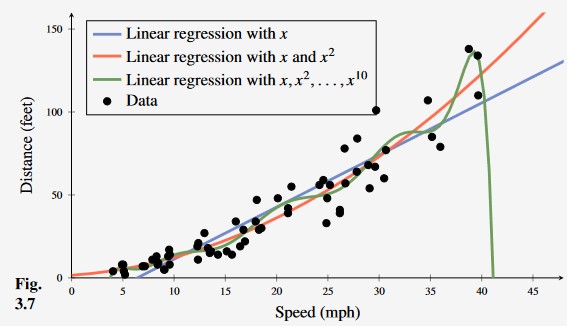
Figure 4 -
Learning the car stopping distance with linear regression, second-order polynomial regression and 10th order polynomial regression. From this, we can see that the 10th degree polynomial is over fitting to outliers in the data making it less useful than even ordinary linear regression (blue).
Regularisation
One way to avoid the over-fitting of the model is to carefully select which inputs (transformations) to include.
- Forward Selection Strategy Add one input at a time
- Backward Elimination Strategy Remove inputs that are considered to be redundant
We can additionally evaluate different candidate models, and compare using cross validation (discussed in Chapter 4.)
Additionally, we can perform regularisation, which is the idea of keeping the parameters small unless the data really convinces us otherwise.
There are different ways to implement this mathematically, which result in different regularisation techniques.
L2 Regularisation
To keep small, an extra penalty term is added to the cost function when using L^2 regularisation
Here, is referred to as the regularisation parameter (a hyperparameter chosen by the user, which controls the strength of regularisation effect).
- This penalty term prevents over fitting
- Original cost function only rewards fit to training data, the regularisation term prevents overly large parameter values at the cost of a slightly worse fit
- Therefore, important to choose the value of the regularisation parameter wisely.
- has no regularisation effect whilst will force all parameters to 0.
Adding regularisation to the linear regression model with squared loss error (Eq 3.12) yields the following equation
- Just like the non-regularised problem, Eq 3.48 has a closed-form solution given by a modified version of the normal equations:
Note that in this equation is the identity matrix of size .
This particular application of regularisation is referred to as ridge regularisation.
The concept of regularisation is not limited to linear regression
- The same penalty can be applied to any method that involves the optimisation of a cost function
For example, here is the regularisation applied to logistic regression
- Logistic regression is commonly trained using Eq. 3.50 instead of Eq 3.29.
- This reduces possible issues with over fitting
- Additionally, have issues with model diverging with some datasets unless is used.
Generalised Linear Models
This section has been omitted as it is not part of the assessable content for this course