Lindholm et al, Chapter 4
Lindholm et al, Chapter 4
A summary of Lindholm Chapter 4 - Understanding, Evaluating and Improving Performance
- At present, have just trained models, and assumed that they are performant
- This section discusses how to evaluate and improve the performance of models in production
Expected New Data Error E_new: Performance in Production
This section is really also regarding model selection
- Define new error function which encodes purpose of classification and regression
- Compares prediction to measured data point .
- Returns a small value if is a good prediction, and a larger value otherwise
- Can consider different error functions, depending on what properties of prediction are most important.
- Our default choices are as follows:
- Average misclassification (calculated as misclassification rate = 1 - accuracy)
- Squared Error for regression problems. This is similar to the loss function .
- Loss function is used when learning/training
- Error function is used to analyse performance of a model that has already been trained
Supervised Learning as Inputs over Random Distribution
In the end, supervised learning amounts to designing a method that performs well on new, unseen data.
The performance can be mathematically understood as the average of error function (how often classifier is right)
To mathematically model this data, introduce distribution over data, denoted .
- Now consider as a random variable with a probability distribution
Regardless o the classification or regression method chosen, it learns from training data and return predictions for any new input .
Now denote the prediction as tp emphasise that the model depends on the training data .
Integration-Based Error Rate
- Previous,y discussed how model predicts output for one or a few test inputs .
- Now consider averaging the error function over all data points with respect to the distribution
- Refer to this as the expected new data error
- In this equation is the expectation over all possible test data points with respect to the distribution
The model, regardless of its type is trained on a given training dataset .
In Eq 4.2, we average over all possible test data points .
Thus, describes how well the model generalises from the training data to new situations
We can extend this concept to the computation of the training error:
Note that is the training data
describes how well a method performs on specific data it was trained on
- Doesn’t give any insight on how the model performs on new, unseen data
describes how well a model performs “in production” on new data.
A model that fits the training data well (small ) might still have large when faced with new data
- The best strategy to minimise is therefore, not necessarily to minimise .
- Furthermore, misclassification (Eq 4.1a) is unsuitable as an optimisation objective as it is discontinuous and has a derivative of zero almost everywhere
- We can choose better loss function such as gradient boosting (Ch 7) and support vector machines (Ch 8)
Not all models are trained by explicitly training a loss function (e.g. -NN)
In practice, can never compute - we do not know true in practice by definition
We can instead attempt to estimate .
Estimating E new
- There are several motivations for estimating .
- Judging if performance is satisfying (whether is small enough), or whether more work should be put into the solution and/or more training data should be collected
- Choosing between different methods
- Choosing hyper-parameters in order to minimise
- Reporting expected performance to customer.
Cannot Estimate E new from Training Data
- Consider that contains samples from .
- Training data is assumed to have been collected under similar circumstances to that which the train model is being used.
- When an expected value cannot be computed in closed form (e.g. Eq 4.2), we can approximate the expected value by a sample average
- We can attempt to approximate the integral (expected value) by a finite sum.
- However, the data points used to perform this approximation is data that the model was trained on, and thus we cannot have any guarantee on the performance when evaluated on previously unseen data.
Hold-Out Validation Data
- To circumvent the issue presented before, we can partition the data to create a set of hold-out validation data denoted which is not in used for training.
- We can then use this data to compute the estimated performance of the model, known as the hold-out validation error
- In this way, not all data will be used for training, but some data points will be saved and used for only computing .
- However, you have to be careful when splitting your dataset
- Someone might have sorted the dataset for you, so you must shuffle the samples in your data before splitting.
- Therefore, assuming that both training and validation (hold-out) data is drawn from the same probability distribution, then we have that:
- However, this does not tell us how close is to for a single experiment
- The variance of will decrease if the size of the validation dataset.
- Thus, for sufficiently large , the above equation holds
- This is not an issue if there is a lot of data.
- However, if dataset is limited then have a trade-off between wanting to know out and decreasing our error rate (more training data = less error)
k-Fold Cross-Validation
To avoid setting aside validation data but still obtain an estimate of , we could perform a two-step procedure:
- Split available data into training and hold-out validation set. Train the model on the training dataset and compute using the hold-out validation data
- Train the model again using entire dataset.
This is better, but not perfect - to get a small variance in the estimate, must put a lot of data in hold-out validation dataset.
This means that model trained in step (1) can vary quite significantly to resulting model trained on entire dataset.
We can build on this idea to derive the k-fold cross-validation method by repeating the hold-out validation procedure multiple times:
- Split the dataset into k batches of similar size and let
- Take batch as the hold-out validation data and the remaining batches as training data
- Train the model on the training data and compute as average error on hold-out validation data.
- If set and return to (ii). If then compute k-fold cross validation error
- Train the model again, using the entire dataset
Using the k-fold cross-validation method, we get a model which is trained on all the data, as well as an approximation of denoted .
- Whilst $E_\text{hold-out} $ was an unbiased estimate of (at the cost of setting aside hold-out validation data), this is not the case for .
- However, with large enough , this is a sufficiently good approximation
Why does this work?
- The intermediate models are trained on of the data
- If k is sufficiently large, then they are quite similar to the final model since they are trained on almost the same dataset
- Furthermore, each intermediate is an unbiased but high-variance estimate of for the corresponding intermediate model
- Since all intermediate models and the final model are similar, is approximately the average of k high-variance estimates of for the final model
- When averaging estimates, variance decreases and will become a better estimates of than the intermediate .
Training Time
- Training is typically discussed as a procedure that is executed once
- In k-fold cross-validation, the training is repeated O(k) times
- For methods such as linear regression, the actual training is usually done in milliseconds, so doing it an extra O(k) times might not be a problem in practice
- If the training is computationally demanding (as in Deep Neural Networks) it becomes a rather cumbersome procedure, and might be more practically feasible.
- If there is a lot of data available, it is also an option to use the hold-out approach.
Using a Test Dataset
- In practice, important to choose or with hyper-parameters so that the error is minimised
- However, we cannot use to estimate the new data error (select models based on )
- If we do this, we risk over-fitting tot he validation data, resulting in being overly optimistic estimate of the actual new data error
- If important to have good estimate of the final , set aside another hold-out dataset - this is our test set.
- This test set should only be used once (after selecting models and hyper-parameters) to estimate for the final model.
Augmenting Training Set
- In problems where training data is expensive, common to increase training dataset using more or less artificial techniques.
- Can duplicate data and add noise to duplicated versions, to use simulated data, or use data from different but related problem.
- In this case, training data is no longer drawn from .
The Training Error-Generalisation Gap Decomposition of E new
This section discusses over-fitting and under-fitting
- The core goal of supervised machine learning is to design method with small
- Can gain more insights and better understand the behaviour of these methods by further reasoning about
- Introduce training-data averaged and .
- Here denotes the expected value with respect to the training set
- This is based on the assumption that the training dataset consists of independent draws from some probability distribution
- Know that cannot be used to estimate , but generally, it holds that:
- That is, a method performs worse on new, unseen data than on training data
- A method’s ability to perform well on unseen data after being trained is referred to as its ability to generalise from training data
- Therefore, call the difference between and the generalisation gap
Generalisation Gap Factors
- Size of generalisation gap depends on method and problem
- The more a method adapts to training data, the larger the generalisation gap
Framework for how much method adapts to training data is given by Vapnik-Chervonenkis (VC) dimension
Probabilistic bounds on generalisation gap can be derived, but are typically rather conservative.
Can use the terms model complexity or model flexibility which refers to the model’s ability to adapt to patterns in the training data
A model with high complexity (such as fully connected DNN, deep trees or k-NN with small k) can describe complicated input-output relationships
However, models with low complexity (such as logistic regression) is less flexible in terms of what functions it can describe
Model complexity for parametric models dependent on number of learnable parameters and regularisation techniques
This idea of model complexity is an oversimplification but is still useful for intuition
Typically, higher model complexity implies larger generalisation gap
decreases as model complexity increases, whereas typically attains a minimum value for some intermediate model complexity value.
- Model complexities that are too low or too high increase .
- Over-fitting: Model complexity that is too high ( is higher than it would be with a less-complex model)
- Under-fitting: Model complexity that is too low
- The point at which obtains a minimum value is referred to as a “balanced fit”
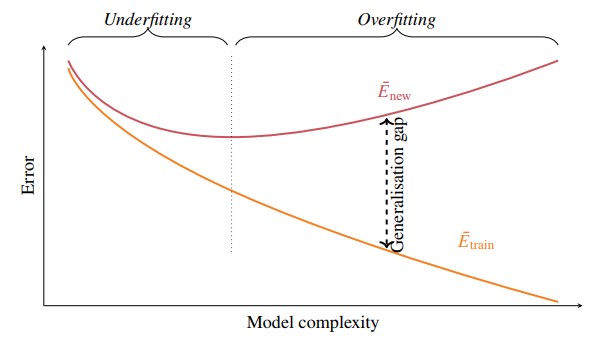
Figure 1 - Over-fitting vs Under-fitting
- In the figure above, we observe the behaviour of and as model complexity increases
- decreases as the model complexity increases
- However, does not necessarily decrease as the model complexity increases.
- We ideally want to choose a model with complexity such that is minimised.
Binary Classification Example
Consider simulated binary classification input with two dimensional input
Since problem is simulated, we know that $ p({\bf{x}},y) $ (that $ \bf{x} $ is drawn from some probability distribution)
In this problem is a uniform distribution on the square and defined as follows:
- All points above dotted curve are red with probability 0.8
- All points below curve are red with probability 0.8.
The optimal classifier in terms of minimal would have the dotted line as its decision boundary and achieve .
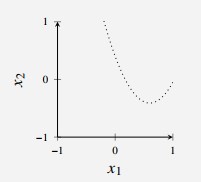
Figure 2 - Optimal Decision Boundary for Classification Problem
We generate a training dataset with samples.
Using this training data, we train three -NNs with as shown in the figure below
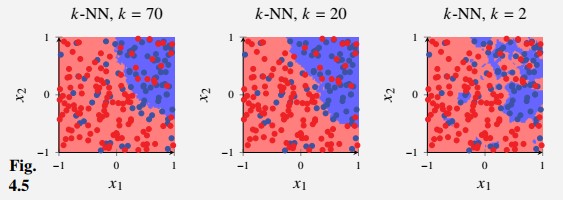
Figure 3 - Example of Over-fitting and Under-fitting in KNN Classification
We see that gives the least flexible model and gives the most flexible model
We see that in the figure (right) adapts too much to the data
Conversely (left) is rigid enough to not adapt to the noise, but might be too inflexible to adapt to the true decision boundary
By creating more testing data, we can compute and .
- Since in this example, the data is simulated, we can estimate numerically by creating more test data and computing it.
This resembles Figure 1 above, except that is smaller than for some values of .
| -NN with | -NN with | -NN with | |
|---|---|---|---|
| 0.24 | 0.22 | 0.17 | |
| 0.25 | 0.23 | 0.30 |
We observe in the tabulated values that the generalisation gap
For the values of shown, we observe that is smallest for
- This suggests that by extension suffers from over-fitting and suffers from under-fitting
A key factor in the size of the generalisation gap is the size of the training set.
- In general, the more training data, the smaller the generalisation gap
- However, typically increases as increases, since most models are unable to fit all training data-points well if there are too many
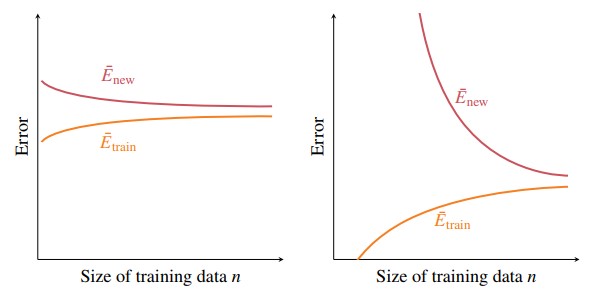
Figure 4 - Behaviour of Training Models with increase in size of training data. Simple model (left) vs complex model (right)
More complex model will attain smaller for a large enough .
The generalisation gap is larger for a more complex model, especially when the training dataset is small.
Reducing E new in Practice
Overarching goal in supervised learning to reduce
Eq (4.11) from before defines that .
This implies that to reduce we both need to reduce and
The new data error will, on average, not be smaller than the training data
- Therefore, if is much larger than the value of required, need to re-think the problem and method chosen to solve it
The generalisation gap and decrease as increases.
- If possible, increasing the size of the training data may significantly decrease
Making the model more flexible decreases but often increase the generalisation gap.
- Making the model less flexible decreases the generalisation gap, but increases
Therefore, the optimal trade-off (to minimise ) is obtained when when neither the generalisation gap nor is zero.
We can monitor and estimate with cross-validation to obtain the following conclusions:
- If (small generalisation gap, possibly under-fitting), it might be beneficial to increase model flexibility by loosening regularisation, increasing the model order (more parameters to learn), etc.
- If is close to zero and is not (possibly over-fitting), it might be beneficial to decrease the model flexibility by tightening the regularisation, decreasing the order (fewer parameters to learn), etc.
Shortcomings of Model Complexity Scale
- When there is one hyperparameter to choose, it is often easy to determine what to do (as in Figure 1)
- However, when there are multiple hyper-parameters (or competing methods) it is important to realise that one-dimensional complexity as shown before doesn’t properly address the space for all possible choices
- It is possible for a method to have a smaller generalisation gap than another method without having larger training error.
- The one-dimensional complexity can be misleading for intricate deep-learning models
- Not even sufficient for relatively simple problem of jointly choosing degree of polynomial regression and regularisation parameter
Example - Training Error and Generalisation Gap for Regression
Consider a simulated problem with generated using , and
We consider the following regression methods:
- Linear Regression with regularisation
- Linear regression with quadratic polynomial and regularisation
- Linear regression with third-order polynomial and regularisation
- Regression tree
- Random forest with 10 regression trees
For each of these methods, try a few different values of parameters (regularisation parameters, tree depth) and compute and the generalisation gap
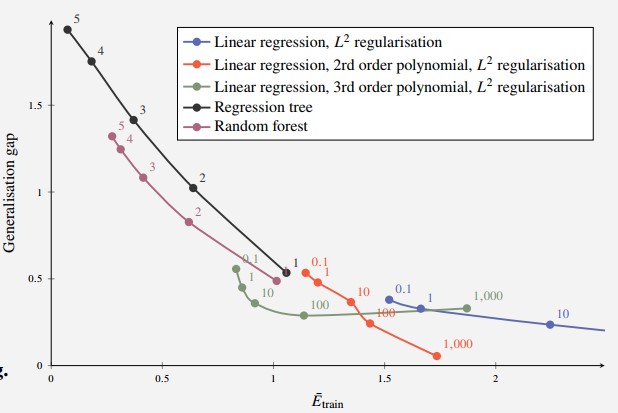
Figure 5 - Evaluation of training loss and generalisation gap
For each method, the hyperparameter that minimises is the value that is the closest to the origin since
When comparing different methods, the problem is more complex than that presented before.
Takeaway: Relationships are intricate, problem-dependent and impossible to describe using the methodology above
- Observe the second-order polynomial (red) vs the third-order polynomial (green) linear regression
- For some values of the regularisation parameter, the training error decreases without increasing the generalisation gap
- Similarly, the generalisation gap is smaller while the training error remains the same (for the random forest than for the tree)
- Observe the second-order polynomial (red) vs the third-order polynomial (green) linear regression
We can simplify this by introducing the bias-variance decomposition
Bias-Variance Decomposition of E_new
- Introduce another decomposition of using squared bias and variance.
Recap of Bias and Variance
- Consider an experiment with an unknown constant (true value) which we would like to estimate.
- are our measurements of , which are drawn from some random distribution
- Since is a random variable, it has some mean which is denoted as .
- Now introduce the concepts of bias and variance
Variance: How much the result varies each time it is sampled
Bias: Systematic, constant error in that remains regardless of number of times sampled.
If we consider the squared error between and to as a metric of how good the estimator is, wegt can re-write it in terms of the variance and squared bias:
- The average squared error between and is the sum of the squared bias and variance.
- To obtain small expected squared error, have to consider both the bias and variance - that is, both values need to be small.
Bias and Variance in a Machine Learning Context
Consider the regression problem with squared error function (SSE) for the sake of simplicity.
- This concept and the intuition behind it carries over to classification as well.
In this context, corresponds to the true relationship between input and output.
corresponds to the model learned from the trained data.
- Since the training data collection includes randomness, the model learned from it will also be random.
Make the assumption that the true relationship between the input and the output can be described using (a possibly very complicated) function plus some independent noise term .
- Use the notation to denote the model trained on some training data .
- This is our random variable, which corresponds to defined above.
- We also introduce the average trained model, which corresponds to :
denotes the expected value over training data points drawn from some probability distribution .
Therefore, is the (hypothetical) average model achieved if the model could be trained an infinite number of times on different training sets of size and then compute the average of all of those models.
From before, we have the definition of defined for regression with squared error:
- We can alternatively denote Eq 4.16 as
- Extending 4.13 to also include the zero-mean noise term gives the following expression inside the expected value in Eq 4.17 as:
- This equation is effectively the application of Eq 4.13 applied to supervised machine learning
- In , we also have the expectation over new data points .
- We can incorporate that expected value into the expression to form a new decomposition of .
In this new decomposition, the squared bias term describes how much the average trained model differs from the true averaged over all possible test data points .
The variance term describes how much varies each time the model is trained on a different training set.
For the bias term to be small, the model must be flexible enough such that can be close to (at least in regions where is large).
If the variance term is small, the model is not very sensitive to exactly which data points happened (or happened not to be) in the training data.
The irreducible error is a byproduct of the assumption in Eq 4.14 in which it is not possible to predict since it is a random error independent of all other variables.
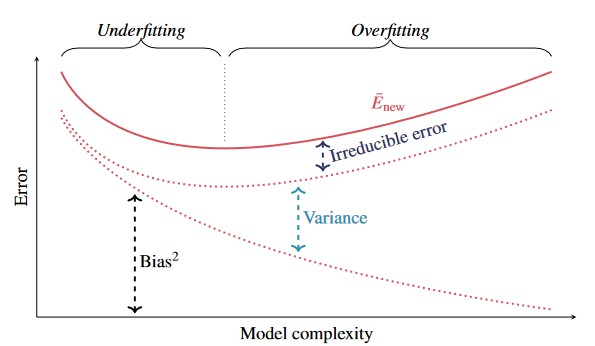
Figure 6 - Model Complexity vs Error considering the bias-variance decomposition of Enew. Observe that low model complexity means high bias. More complex models adapts to noise in the training data which results in higher variance. This means that to achieve small Enew we need to select a suitable model complexity level. This is called the bias-variance tradeoff.
Factors Affecting Bias and Variance
- We can use Bias and Variance to define model complexity
- A model with high complexity means low bias and high variance.
- Conversely, low model complexity means high bias and low variance.
- The more flexible the model is, the more it will adapt to the training data (including the actual data points present as well as any noise)
- A less flexible model can be too rigid to capture the true relationship between the inputs and outputs - this effect is described by the squared bias term.
Example: Bias-Variance Tradeoff for Regularised Linear Regression
- Consider a simple example in which follows the probability distributions:
- Let the training data consists of only data points.
- Attempt to model the data using linear regression with a 4th order polynomial denoted
Since 4.20 is a special case of 4.21, and the squared loss corresponds to gaussian noise, we have a zero-bias model if we train using squared loss error.
However, learning 5 parameters from only 10 data points leads to very high variance.
Therefore, decide to train model using squared loss error and regularisation which will decrease the variance (but increase the bias)
Greater regularisation (larger ) means more bias and less variance.
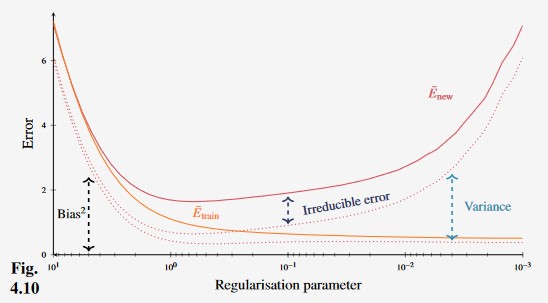
Figure 8 - Effect of regularisation on error in polynomial regression model.
From the figure above, we can see that for this particular problem the optimal value of occurs at around 0.7, where attains its minimum value.
Connections between Bias, Variance and the Generalisation Gap
Bias and variance are theoretically well-defined but hard to determine the value of in practice (as they are defined in terms of probability distribution )
In practice, can have an estimate of the generalisation gap (e.g., as whereas bias and variance require additional tools to estimate.
Consider regression problem in which squared error is used as both error and loss function
- Additionally, assume that a global minimum has been found during training.
- We approximate the expected value by a sampling average using the training data points.
- If we assume that can possibly be , together with the assumption of having the squared error as a loss function and the learning of always finding the global minimum, we have the inequality given in the next step.
- Remember that , and allow gives the following:
- In practice, the assumptions don’t always hold.
- Can deal with this through using bagging (ensemble methods) which will be discussed in Chapter 7
Additional Tools for Evaluating Binary Classifiers
- Define some tools for binary classification problem with imbalanced or asymmetric problems
- Consider the binary classification problem in which 90% of the samples belong to class A and 10% to class B.
- If we evaluate accuracy just using a single acc value, we can gain 90% accuracy just by always predicting class A.
- We have to look more closely at the types of errors made by the model
- Using a classifier often involves applying some adjustable threshold to make the decision of which class to choose (as in Logistic Regression)
- If we change this threshold, we are likely to see a change in the classification performance.
Confusion Matrix and ROC Curve
- Confusion Matrix a table that breaks down a comparison of the class predictions vs true class values from training data.
- In the binary case, we can have True Positive, True Negative, False Positive and False Negative
- By separating the predictions into four groups dependent on , the actual output and (the predicted output from the classifier) we can construct the following confusion matrix for the classification problem.
| True Negative | False Negative | N | |
| False Positive | False Negative | P | |
| N | P | n |
denotes total number of positive (negative) examples in the dataset denotes the total number of positive (negative) predictions made by the model.
- For asymmetric problems, important to distinguish between False Positive (Type I) and False Negative (Type II) error
- Ideally, both types of errors should be 0, but there is typically a tradeoff between these two errors.
- The tradeoff between FP and FN can be changed by tuning a decision threshold .
- Some of the terminology associated with confusion matrices include:
- Other common terms associated with Confusion Matrices are given below
| Ratio | Name | |
|---|---|---|
| FP/N | Fall-out, Probability of False Alarm | False Positive Rate |
| TN/N | Specificity, Selectivity | True Negative Rate |
| TP/P | Sensitivity, Power, Probability, Probability of Detection | True Positive Rate, Recall |
| FN/P | Miss Rate | False Negative rate |
| TP/P* | Positive Predictive rate | Precision |
| FP/P* | False Discovery Rate | |
| TN/N* | Negative Predictive Value | |
| FN/N* | False omission rate | |
| P/n | Prevalence | |
| (FN + FP)/n | Misclassification Rate | |
| (TN + TP)/n | 1 - misclassification rate | Accuracy |
| 2TP/ (P*+P) | score | |
| score |
Recall: How much of the positive data points are correctly predicted as positive Precision: Ratio of TP are among those predicted positive ROC (Receiver Operating Characteristics): Plotting the ROC curve can be useful in comparing classifiers with different threshold values .
- Plot true positive rate over false positive rate for all
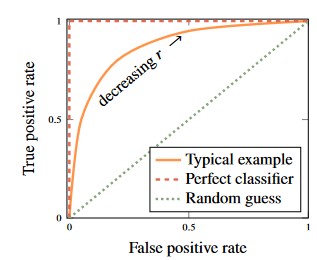
Figure 9 - ROC Curve for Classifier
Observe that the perfect classifier (red dotted line) touches the top left corner of the plot.
- This is in contrast to a classifier that gives random guesses - this gives a straight diagonal line
We can use ROC-AUC (Area under the ROC curve) to summarise the plot
- A perfect classifier has ROC-AUC=1 and a classifier that assigns random guesses to have ROC-AUC=0.5
We can use the precision-recall curve for imbalanced problems.
A problem is:
- Imbalanced if the vast majority of the data-points belong to one class (typically, the negative class)
- The imbalance implies that a (useless) classifier which always predicts will score very well in terms of misclassification rate
- Confusion matrix offers good opportunity to inspect FPs and FNs
- Can also use measures such as misclassification rate in balanced problems to summarise this into a single score.
- For imbalanced problems where the negative class is the most common class, the score is better
- However, score is preferred as doesn’t consider the fact that one type of error is considered to be more serious than another
- considers recall to be times more important as precision
- ROC may be misleading for imbalanced problems and so precision-recall curve
Figure 10 - Precision-Recall Curve for Binary Classification Problem. Precision-Recall curves are good for imbalanced classification problems.