Lindholm et al, Chapter 5
Lindholm et al, Chapter 5
Learning Parametric Models
Principles of Parametric Modelling
- A linear regression model is denoted by
- Introduced explicit dependence on the parameters in the notation to emphasise that the equation should be viewed as a model of the true input-output relationship.
- For the linear regression model, two key assumptions were made:
- Function assumed to be linear in model parameters, .
- Noise assumed to be of Gaussian distribution
- Both of these assumptions can be relaxed - first consider relaxing the first assumption
- Let be some function that is adaptable to training data, by letting the function depend on model parameters learned from the training set.
- We can use this to transform logistic regression model into a non-linear model by using
- Having specified this family of models, we want to learn the parameters from the training data.
- For parametric models, this learning objective is typically formulated as an optimisation problem, denoted:
- Minimise a cost function defined as average of some (user-chosen) loss function evaluated training data.
- In some cases, can compute the solution exactly (e.g. linear regression, closed-form solution)
- Most cases require numerical optimisation methods (e.g. gradient descent)
- We really want to minimise but this error is unknown to us.
- With this concept in mind, we make the following observations:
- The cost function is computed based on the training data, and is subject to the noise in the data. Therefore, it is not meaningful to optimise with greater accuracy than the statistical accuracy in the estimate.
- Loss function error function - The error function used should not be the same as the los function - this is said to create models that are able to generalise better. In addition to this, we can choose loss functions that make the optimisation problem easier to solve, or make the model have favourable properties (e.g., make the model less computationally demanding to use in production)
- Early Stopping is sometimes useful as the end-point of the optimisation isn’t necessarily the set of parameters with lowest .
- Explicit Regularisation is performed by modifying the cost function by adding a term independent of the training data - we want to find the simplest set of parameters, so we penalise large parameter values.
Loss Functions and Likelihood-Based Models
- Different loss functions give rise to models with different solutions ()
- Different loss functions will be optimal for different problems.
- Certain combinations of models and loss functions have been given certain names:
- Linear Regression Linear-in-the-parameter models, squared error loss function.
- Support Vector Classification Linear-in-the-parameters model, hinge loss
- Want to create models that are robust (to outliers in the data).
- If outliers have minor impact on learned model, say loss function is robust.
- Important in models created using data contaminated with outliers.
Loss Functions for Regression
- In Chapter 3, introduced squared error loss, which is the default choice for linear regression as it means that the model has a closed-form solution.
- Another choice is the absolute error loss which is more robust to outliers as it grows more slowly for large errors.
- This can be justified using the concept of maximum likelihood estimation, just like with the squared error loss
- Consider that the error has a Laplace distribution
- It is sometimes argued that the squared error loss is a good choice because it penalises small errors () less than linearly.
- Furthermore, Gaussian distribution appears (at least approximately) quite often in nature
- However, the quadratic shape in nature is the reason for its non-robustness
- Therefore, Huber loss proposed as a hybrid between absolute loss and squared error loss
- Another extension to the absolute error is the -insensitive loss, which places a tolerance of width around the observed value and behaves like the absolute error loss outside of this region.
- The robustness properties of the -insensitive loss are very similar to that of absolute error loss
- This is useful for Support Vector Regression in Chapter 8.
Loss Functions for Binary Classification
- An intuitive loss for binary classification is the misclassification loss
- Although this is the ultimate goal, it is rarely used in training
- Different loss functions can lead to models that generalise better form the training data.
- We want to maximise the distance of between the decision boundary and each class to ensure better generalisation ability.
- To do this, we can formulate the loss function not just in terms of hard class predictions, but predicted class probability (or some other continuous quantity used to compute the class prediction)
- Furthermore, misclassification loss is difficult to optimise from a numerical optimisation perspective since the gradient is zero everywhere (except where it is undefined).
- For a binary classifier that predicts conditional class probabilities , in terms of a function the cross-entropy loss is a natural choice:
- Many binary classifiers can be constructed by thresholding some real-valued function at 0. That is, we write the class prediction:
- Logistic regression can be brought into this form by simply using as shown in Equation 3.39.
- For functions of this form, the decision boundary is given by the values of for which .
- The margin can be viewed as a measure of certainty in a prediction, where data points with small margins (not necessarily in the sense of Euclidean distance) are close to the decision boundary.
- We can define loss functions for binary classification in terms of the margin by assigning small loss to positive margins (correct classifications) and large loss to negative margins (incorrect classifications).
- Logistic loss (Equation 3.34) can be re-formulated as:
- In this equation, the linear logistic regression model corresponds to
- Note that in this arrangement, we have lost the notion of a class probability estimate, and only have a hard prediction once again.
- The misclassification loss can also be re-formulated in terms of the margin:
- Another loss function is exponential loss, which is defined as:
- We can also define hinge loss, which is defined as:
- One downside of the hinge loss function is that it is not a strictly proper loss function - it is not possible to interpret the learnt classification model probabilistically when using this loss.
- To remedy this, consider using the squared hinge loss, which is less robust than hinge loss.
- An alternative to this is the Huberised squared hinge loss
- When learning models for imbalanced or asymmetric problems, it is possible to modify the loss function to account for imbalance/asymmetry.
- For example, misclassification loss can be modified to penalise that not predicting correctly is a “C times more severe mistake” than not prediction correctly, the misclassification loss can be modified into Equation 5.19 below
- A similar effect can be achieved by duplicating all positive training data points times in the training data instead of modifying the loss function.
Multi-Class Classification
- Cross-entropy loss is easy to generalise to multi-class classification as done in Chapter 3
- Generalisation of other loss functions requires generalising the concept of a margin to the multi-class case.
- Another alternative is to re-formulate the problem as several binary problems - approach taken in the textbook.
Likelihood-Based Models and the Maximum Likelihood Approach
- Maximising the likelihood is equivalent to minimising cost function based on negative log-likelihood loss
In all cases where we have a probabilistic model of conditional distribution the negative log-loss likelihood is a plausible loss function
For classification problem, this is simple as corresponds directly to a probability vector over the classes
I have ignored a bunch of content here for the sake of time
Regularisation
- A useful tool for avoiding overfitting if a model is too flexible.
- In a parametric model, the idea of regularisation is to “keep the parameters small unless the data really convinces us otherwise”.
- There are many ways to implement this, distinguish between explicit and implicit regularisation:
L2 Regularisation
Also known as Tikhonov regularisation, weight decay, ridge regression, or shrinkage
- L2 regularisation is a form of explicit regularisation, where we add a penalty term to the cost function that penalises large values of the parameters .
- By choosing the regularisation parameter , a trade-off between the original cost function (fitting training data as well as possible) and the regularisation term (keeping parameters close to 0) is mad.e
- In setting , the least squares problem is recovered, whereas with , all parameters will be forced to 0.
- Optimal values can be found via cross-validation
- Can derive version of normal equations for L2 regularisation:
- In the equation is the identity matrix.
- For the matrix is always invertible, and the solution is given by:
- This reveals another motivation for using regularisation for linear regression - when is non-invertible, no unique solution exists, however, the regularisation term will ensure that a unique solution exists.
L1 Regularisation
- With L1 regularisation, the penalty term is added to the cost function.
- This added penalty term is the L1 norm of the parameter vector (i.e., sum of absolute value of parameters).
- The L1 regularised cost function for linear regression is
- No closed-form solution that exists, but can create efficient numerical optimisation algorithm
- L1 regularisation pushes all parameters toward small values (but not necessarily zero)
- Tends fo favour sparse solutions
Implicit Regularisation
- There are alternative ways to achieve a similar effect without explicitly modifying the cost function
- One way to do this is early stopping - applicable to any method that is trained using iterative numerical optimisation.
- This amounts to stopping the optimisation before it has reached the minimum of the cost function
- Can be implemented by setting aside some hold-out validation data and computing after each iteration.
- Observed that will decrease initially, but eventually reaches a minimum and starts to increase again.
- The optimisation is aborted at the point when reached its minimum.
Parameter Optimisation
- Want to find minimum or maximum of objective function.
- There are two ways optimisation is used in ML:
- Training a model by minimising the cost function with respect to model parameters . The objective function in this case is , and optimisation variables to model parameters .
- Tuning hyper parameters such as , such as using hold-out validation dataset. The objective function is the validation error and the optimisation variables is the hyper parameters.
- Optimisation is easier for convex objective functions - take some time to consider whether we can re-formulate a non-convex optimisation problem into a convex one.
- The most important property of convex functions is that they have a unique global minimum, and no other minima.
- When closed form solutions don’t exist, we must use (iterative) numerical techniques for solving.
- For L1 regularised linear regression, but it turns out coordinate descent is a good approach for this problem.
Gradient Descent
Useful when we don’t have a closed-form solution but we have access to the value of the objective function and its derivative (gradient).
- Can be used for learning the parameter vectors of high-dimension when the objective function is simple enough that we can compute its gradient.
- We can potentially also use Gradient Descent for hyperparameter optimisation
- Assume that the gradient of the cost function exists for all .
- Note that is a vector of the same dimension as , which describes the direction in which increases.
- From this, we obtain which is the direction in which decreases
- If we take a small step in the direction of negative gradient, this will reduce the value of the cost function
- If in convex, the inequality in Equation 5.30 is strict except at the minimum (where the derivative is zero)
- This suggests that if we have and want to select such that Equation 5.30 holds true, we should use the following equation, with some .
- The Gradient Descent Algorithm is as follows:
Input: Objective function , initial , learning rate
Result:
- Set
- while not small enough do
- | Update
- | Update
- end
- return
When using this algorithm in practice, we do not know which determines how big the step is at each iteration
- It is possible to formulate the selection of as an internal optimisation problem that is solved at each iteration (a “line search problem”)
- Consider the simpler solution where consider to be a constant chosen by the user.
- In this case, is viewed as a hyperparameter, called the learning rate or step size, and the optimal value depends on the shape of the cost function.
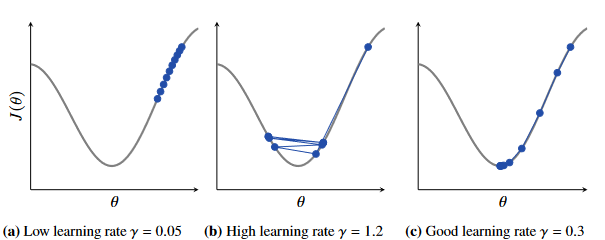
Figure 5.7 - Effect of learning rate on gradient descent. (Left) Too high learning rate (Middle) Too high learning rate (Right) Good learning rate.
Can see in Fig 5.7, the effect of different learning rates.
- If the cost function values are getting worse or oscillating wildly, decrease the learning rate
- If the learning rate fairly constant and only slowly decreasing, increase the learning rate.
No guarantees about convergence with gradient descent, as a bad choice of will break the method.
With the right choice of learning rate, the value of will decrease fo each iteration until a point with zero gradient is found.
- However, not necessarily a minimum but could be a maximum or saddle point in the objective function.
- In non-convex problems with multiple minima, we cannot expect gradient descent to find the global minimum
- Initialisation is usually critical for determining which minimum is found.
Good practice to run the optimisation multiple times with different training initialisations.
- However for large models, this can be computationally expensive, so can use heuristics and tricks to find a good initialisation point
Second-Order Gradients
Omitted as not really covered in the lectures -> not relevant
Optimisation with Large Datasets (SGD)
- With large values of (samples in the dataset), we can expect that the gradient computed for the first half of the dataset to be almost identical to the gradient computed for the second half.
- Consequently, might be a waste of time to compute the gradient over the entire dataset at each iteration of gradient descent.
- Instead, we can compute the gradient based on the first half of the training set, update the parameters according to the gradient descent method and and then compute the gradient for the new parameters based on the second half of the training data.
- Utilising Equation 5.37 requires half the computation compared to the two parameter updates of conventional gradient descent.
- We can further extend this idea into subsampling with even fewer data points used in the gradient computation.
- Call a sub-sample of the data a mini-batch which can typically contain samples.
- One complete pass through the training data is called an epoch, and consists of iterations.
- Note: When using mini-batches, it is important to ensure that the mini-batches are balanced and representative of the entire dataset.
- Mini-batches should be formed randomly - can do this by shuffling the data and dividing into mini-batches.
- After completing one epoch, perform shuffling of the training data and do another pass through the dataset.
- This idea of gradient descent with mini-batches is called stochastic gradient descent and is summarised in the pseudocode shown below:
Stochastic Gradient Decent Pseudocode
Input Objective Function , initial , learning rate Result
- Set
- while convergence criteria not met do
- | for do
- | | Randomly shuffle the training data
- | | for do
- | | | Approximate the gradient using the mini-batch
- | | | Update
- | | | Update
- | | end
- | end
- end
- return
- Stochastic Gradient Descent is widely used, with different variants for different purposes.
Learning Rate and Convergence for SGD
Standard gradient descent converges if the learning rate is wisely chosen and constant (since the gradient is zero at the minimum).
For SGD, cannot obtain convergence with a constant learning rate - we only obtain an estimate of the true gradient, and this estimate will not necessarily be zero at the minimum of the objective function (might be considerable amount of noise in the gradient estimation due to subsampling)
SGD with constant learning rate will not converge toward a point, but continue to “wander around” somewhat randomly.
For the gradient descent method to work, also require that the estimate is unbiased - if unbiased, will on average step in the right direction toward the optimum.
By decreasing the learning rate over time, the parameter updates will become smaller and smaller.
Start with and a fairly high learning rate and decay as increases.
There was other content here, but I have decided to omit it because it’s taking too much time
Hyperparameter Optimisation
- Simplest way optimiser hyper-parameters is to perform a “grid search”.
- Very computationally inefficient especially for parameter vectors with high dimensionality.
- This is fine for problems with low-dimensional hyper-parameters but grows quickly with the number of hyper-parameters.
- If we consider points for which the objective function has already been evaluated as a training dataset, we can use a regression method to learn a model for the objective function.
- This model can be used to predict where to evaluate the objective function next.