Lindholm et al, Chapter 6
Lindholm et al, Chapter 6
Neural Networks and Deep Learnings
- Can effectively stack multiple parametric models to construct a new model that is able to describe more complex input/output relationships than linear or logistic models are able to.
The Neural Network Model
- We can describe the non-linear relationship between input variables and outputs in its prediction form as:
- where is a function parameterised by , which can be parameterised in many ways.
- The general strategy for neural networks is to use several layers of regression models and non-linear activation functions.
Generalised Linear Regression
- Begin with description of a neural network with the linear regression model:
Here, denote parameters by the weights and the offset term (bias) .
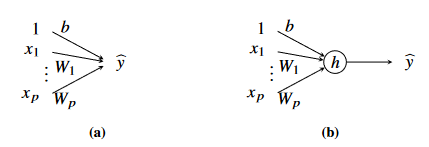
Figure 1 - (a) Graphical illustration of linear regression model and (b) generalised linear regression model. In (a), the output is the sum of all terms, b and the weighted inputs. In (b), the output is the sum of all terms, b and the weighted inputs passed through a non-linear activation function h
Each input variable is represented by a node, and each parameter by a link.
The output is the sum of all terms plus the bias term .
- By convention, use constant value 1 to as the input variable corresponding to the bias term.
To describe the non-linear relationship between input and output, introduce a non-linear function called the activation function .
- With this notation, the generalised linear regression model is denoted as
- Common activation functions are the Logistic Function and the Rectified Linear Unit.
- The generalised linear regression model in Equation 6.3 above is not capable of describing complex relationships.
- Make use of several parallel generalised linear regression models to create a layer, and stack these layers in a sequential construction
- This will result in a deep neural network.
Two-Layer Network
- In Equation 6.3, the output is constructed by a single scalar regression model.
- To increase its flexibility and turn it into a two-layer network, we let its output be sum of such generalised linear regression models, each of which has its own set of parameters.
- The parameters for the th regression model are and we denote its output by .
- These intermediate outputs are known as hidden units, since they are not the output of the whole model. The different hidden units instead act as input variables to an additional linear regression model.
- To distinguish the parameters in Eq 6.4 and 6.5, add superscripts and respectively.
- Then out final model is denoted as
- This notation can be written more compactly using matrix notation, where the parameters in each layer are stacked in a weight matrix and an offset vector as:
- With this, the full model is written as
- In this equation, the components in have been stacked as and .
- Additionally, the activation function in this equation acts element-wise across the inputs.
- The weight matrices and offset vectors are the parameters of the model, which can be compiled as a single vector (in the 2-layered perceptron shown above):
Deep Neural Networks
- Enumerate layers with index , where is the total number of layers.
- Each layer is parameterised by a weight matrix and an offset vector .
- Multiple layers of hidden units denoted by .
- Each layer consists of hidden units .
- Note that in this equation, can be different across the various layers.
- Each layer maps a hidden layer to the next hidden layer according to the following equation:
- A DNN of layers is then written as:
Neural Networks for Classification
- We can use neural networks for classification where we have categorical outputs.
- We can extend neural networks to classification in the same way as linear regression to logistic regression.
- The softmax function now becomes an additional activation function acting on the final layer of the neural network.
- It maps the output of the final layer to a probability distribution over the classes, .
- The output corresponds to the probability that the input corresponds to the th class.
- The input variables to the softmax function are referred to as logits.
- The softmax function is not another layer with parameters, merely as a transformation to the output.
Training a Neural Network
- A neural network is a parametric model and its parameters are found using techniques described in the previous chapter.
- The model parameters are weight matrices and offset vectors
- To find suitable values for the parameters we solve an optimisation of the following form:
Backpropagation
- An algorithm that efficiently computes the cost function and its gradient with respect to all parameters in the neural network
- Cost function and gradient are used in SGD algorithms
- The parameters in this model are all weight matrices and weight vectors
- We use these to do our update for gradient descent (Eqn 6.23)
- To compute the gradients efficiently, backpropagation uses Calculus chain rule instead of naively computing the derivatives.
- The gradient with respect to the (total weighted sum of) input signals to the units in a layer and the output signals of units in a layer given in Eq 6.25
In the backward propagation, compute all gradients and for all layers, from layer .
Then, we start calculating the gradients at the output layer, using the derivative of the activation function and in Eq 6.26.
6.26a describes that for regression problems, the derivative at the end of our MLP which uses squared-error loss is given by:
6.26b describes the derivative for a multi-class classification problem with cross-entropy loss.
The gradients for the weight and bias weights in that layer can be computed, and the gradient signals in the current layer are used to compute the gradients for the previous layer Eq 6.27
Note here that denotes the element-wise product and is the derivative of the activation function .
acts element-wise on
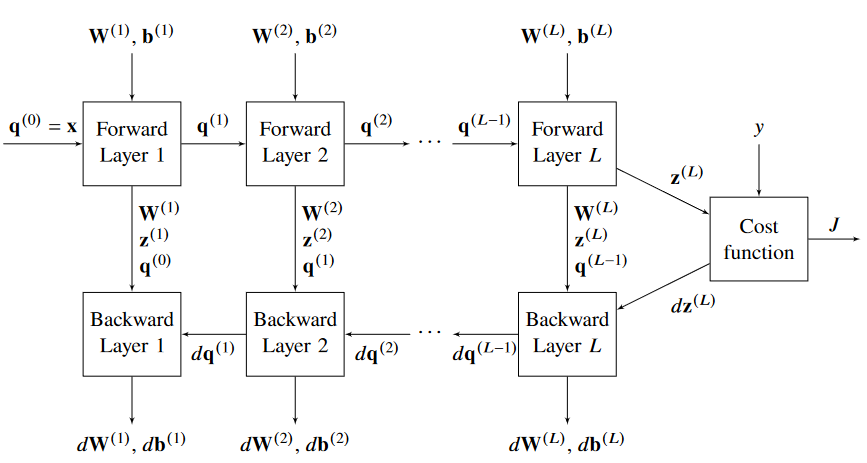
Figure 5 - Graphical representation of the backpropagation algorithm
The backpropagation algorithm is given as:
Input:
- Parameters
- Activation function
- Data with rows where each row corresponds to one data point in the current mini-batch
Result: , of the current mini-batch
- Forward-Propagation
- Set
- for do
- |
- | Do not execute this line for the last layer
- end
- Evaluate the cost function
- if Regression problem then
- |
- |
- else if Classification problem then
- |
- |
- Backward Propagation
- for do
- | Do not execute this line for the last layer
- |
- |
- |
- end
- return
Initialisation
- Training is sensitive to initial parameters as cost functions are usually non-convex.
- Typically initialise all parameters to small random numbers to enable different hidden units to encode different aspects of the data
- If ReLU activation functions used, offset elements are typically initialised to small positive values such that they operate in the non-negative range of ReLU.
Convolutional Neural Networks
- Used for data with grid-like structure, also single-dimension and three-dimensional data
- Each pixel in a greyscale image can be represented as a value in the range [0,1]
- General idea that pixel close together have more in common than pixels far apart.
Convolutional Layers
- Dense / fully connected layer found to be too flexible for images, and might not capture patterns of real importance
- Models will not generalise and perform well on new data
- Exploit the structure present in images to find a more efficiently parameterised model.
- Uses sparse interactions and parameter sharing
- Sparse Interactions Most parameters in a corresponding dense layer forced to be equal to zero.
- Parameter Sharing In a dense layer, each link between input variable and hidden unit is its own unique layer. Instead use the same filter for each pixel in the image.
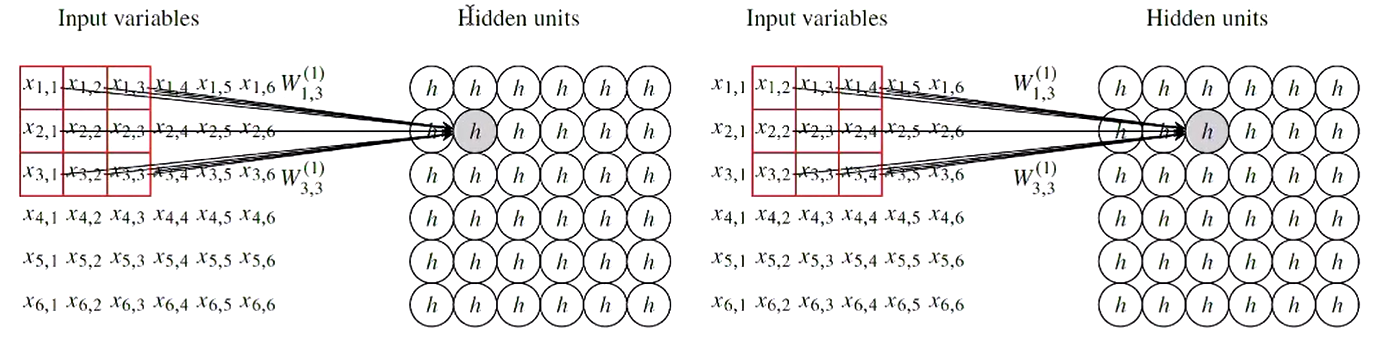
Strided Convolution allows for control over how many pixels in the filter shifts over at each step.
Pooling Layers
- Another way of summarising the information in previous layers can be done by using pooling layers.
- The output from the pooling layer is only dependent on the region of pixels around it.
- Max Pooling takes the maximum value from the region of pixels in the previous layer.
- Average Pooling takes the average value from the region of pixels in the previous layer.
Multiple Channels
- The network in the figure above only has 10 parameters, so one way to extend is to add more channels (by adding multiple kernels), each with their own set of parameters.
- One filter is probably not enough to encode interesting properties in the image.
Full CNN Architecture
- Use convolution layers to perform extract features and then use dense layers for classification or regression.
- Use softmax to bound sum between [0,1] for classification.
Dropout
- A technique to prevent overfitting in neural networks.
- Training multiple models and averaging predictions is one way to reduce variance (idea behind bagging)
- Bagging comes with problems with NNs - computation time to train, and memory required to store all the parameters.
- Drop-out is like a bagging technique that allows combination of many NNs without needing to train them separately.
- Set random hidden units to 0 (effectively removing them).
- At testing time, remove the drop-out.