COMP4702 Lecture 3
COMP4702 Lecture 3
Discuss Linear Regression and Logistic Regression
Linear Regression
Linear Regression is the idea of fitting a straight line (or a hyperplane) to data.
We can use a straight line (or hyperplane) to model the relationship between input and output values
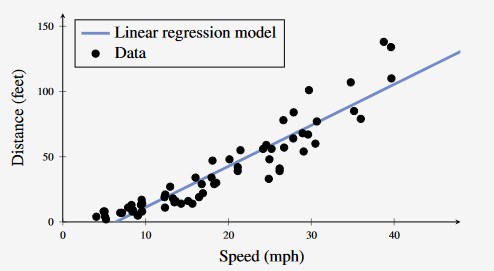
Figure 1 - Car Stopping Distance with Linear Regression Model
Lindholm uses the notation , to denote the y-intercept and gradient respectively
Fundamentally, the linear regression model is a line/curve fitting model
- The goal is to capture the general trend of the data
- However, highly likely that any real-world data will not fit nicely to a line.
To denote this non-conformance to the straight line, we introduce a term to represent this uncertainty, which represents the additive noise in the system.
- This equation can be more compactly represented using vector / matrix notation and linear algebra
Training a Linear Regression Model
- In training a linear regression model from a set of training data denoted we first collect the training data, which is comprised of:
Note that in the formula, each is a vector of a series of input data points
The output in this case is a single (numerical) value
Given this training set, we want to determine the parameters that best fit the data.
We can use this vector and matrix notation to describe the linear regression model for all training points in one equation
Optimisation of Linear Regression
- A typical machine model has a set of parameters, with which it will predict certain values
- We can find the difference between the predicted value and the true value (ground truth)
- We want to minimise this difference between the predicted value and the truth, and this can be done by changing the model’s parameters.
- This “difference” is defined by a loss function, denoted which measure how close the model’s prediction is to the observed data / truth .
- If the model fits well to the data, then the loss function should have a small value.
- The training of the model can be mathematically defined as:
Least-Squares and the Normal Equations
- A commonly used loss function for regression is the squared error loss, denoted as
- This loss function is 0 if and grows quadratically as the difference between and the prediction increases.
- That is, the loss function is 0 if the prediction matches the ground truth.
- Using the squared error loss, the cost function for the linear regression model given in (Eq 3.7) is given as:
This squared error loss can be visualised below, where the squared error loss is the sum of area of squares.
- Observe that points which are further away from the line have significantly larger squares.
- This means that the squared error loss function is potentially sensitive to outliers.
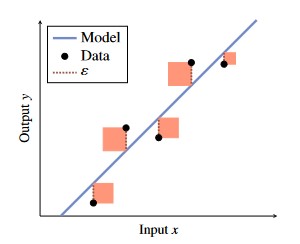
Figure 2 - Squared Error Loss Visualisation.
In the end, when we are trying to train a ML model, we are trying to find the optimal that minimises the error.
This can be denoted as follows:
- If is invertible, then there exists a closed-form equation (we can solve it in a single step, using linear algebra) instead of using some sort of iterative search algorithm
- The algorithm for solving this is given as
Maximum Likelihood Perspective
Turns out to be equivalent to the Sum of Squared Error perspective.
The Maximum Likelihood framework is used to fit models to data in statistics
- Important to incorporate statistics in to Machine Learning as we use statistics to handle the uncertainty in the data.
- Use the terminology “Maximum likelihood” to refer to finding the value of that makes observing as likely as possible.
If we assume that our model parameters are instances of random variables, then the likelihood function is something that is sensible to optimise (maximise) to build a good model for the data
If we assume that the noise term is normally distributed, then minimising the squared error loss is equivalent to maximising the log likelihood
To do this, we want to find some using the following formula:
- Here is the probability density of all observed outputs in the training data, given all inputs and parameters .
- As mentioned before, our noise term has a normal / Gaussian distribution with a mean of zero and variance
- Assuming that all observed training points are independent, and so, factorises as:
- Combining the linear regression model equation (Eq 3.3) with the Gaussian noise assumption (Eq 3.16) gives our probability distribution equation:
- If our noise is randomly distributed, it is a bit of a simplification that our model predicts a single value (our best-guess / average value of where the prediction should be).
- We should instead predict the confidence interval for these values to model this normally distributed uncertainty.
- (Eq. 3.18) gives the probability distribution for the prediction.
- Decreasing the error is equivalent to taking the derivative of the equation and solving for when the error is 0.
- In this case, we are solving for .
- In this case, the optimisation of the equation below is equivalent to optimising the equation without the logarithm
- This is useful, as the multiplication of small number results in increasingly small numbers (may result in increasingly small numbers)
- To get around this, take the logarithm of the function
- This only works as a logarithm is a monotonically increasing function
- We can remove the factors and terms independent of (which do not change the maximising argument) to derive the following equation
Observe that this is exactly the sum of squared error term we obtained earlier.
Linear Classification / Logistic Regression
How do we deal with categorical input variables using the linear regression model
- Logistic Regression is just linear regression, in which the output variable is categorical, .
- Therefore, we need to add a squashing function (e.g. sigmoid) to constrain the output to lie in this range.
Key Points
Logistic regression fits nicely within the Maximum Likelihood framework
Training the model requires an iterative/numerical optimisation algorithm (unlike linear regression, which has a closed-form solution as a result of introducing the non-linearity).
We can use one-hot encoding and a logistic regression model.
For example, for a classification problem with two classes we denote the encoding as the creation of a dummy variable which we can use for supervised machine learning
- If a categorical variable takes more thant two values, say, , we can make the one-hot encoding by constructing a four-dimensional vector in which only one of the values are 1 and the rest are 0
- For example, if the class is then and the rest are 0.
Binary Classification Problem
In a binary classification with two input variables , the decision boundary is visualised as below
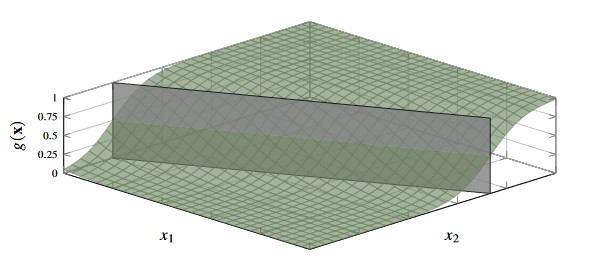
Figure 3 - Decision Boundary of 2-class problem with two input variables.
If then predict class , else predict class (or class depending on labelling scheme)
- We could also determine the probability that a given input belongs to a certain class (this is why we discuss linear regression and classification through the lens of Maximum Likelihood)
- It is in fact more powerful to have a classifier that returns the probability and a prediction, rather than just the prediction itself.
- It tells you how confident the model is in its prediction
Squashing Linear Regression
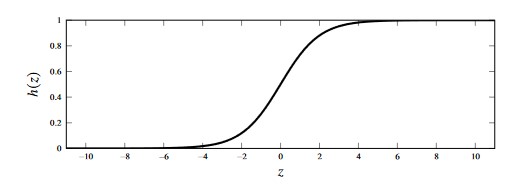
Figure 4 - Logistic Function
- We can use the logistic function to “squash” the output from the linear regression model to be in the range
Classification Notation
- For binary classification problems () where we train a model for which:
p(y=1 | {\bf{x}}) \text{ is modelled by } g({\bf{x}}) \tag{3.26a}
- We can use to compute as by the laws of probabilities
p(y=-1|{\bf{x}})\text{ is modelled by } 1-g({\bf{x}}) \tag{3.26b}
- For a multi-class problem, we let the classifier return a vector-valued function, where:
Model Notation
- We begin constructing the logistic regression / classification model by starting with the linear regression model
- We can then “squash” the output of this model using the logistic function
- Note that in this function we can omit the noise term as the randomness in classification is statistically modelled by the class probability construction instead of an additive noise variable .
* A modified version of Eq 3.29a from Lindholm et al
Training the Logistic Regression Model
In short, we can train the logistic regression model using the principle of maximum likelihood.
The only difference is that the model is denoted slightly differently.
- The training of the model is effectively solving Eq 3.30 shown below
- In which the log likelihood component can be denoted as:
- Note here that the loss that we have derived is the binary cross-entropy loss.
- This is a good loss function to optimise given that it corresponds directly to the maximum likelihood principle
Multi-Class Logistic Regression
- Instead of having a scalar-valued function representing we have a vector-valued function which represent the individual class probabilities.
- The Softmax function here is a normalised version of the logistic function shown above.
- Each of the entries in the vector is an instance of the logistic regression function, each denoted , each with their own set of parameters .
- We stack all instances of into a vector of logits and use the soft-max function to replace the logistic function
- We now have a combined expression for linear regression and the softmax function to model the class probabilities
- We can equivalently write out the class probabilities (elements of vector ) as:
- We use the multi-class cross-entropy loss function shown below
- Note that this multi-class cross-entropy loss is denoted
- We can insert the model we developed in (Eq 3.43) into the loss function (Eq 3.44) to give the cost function to optimise for the multi-class logistic regression problem.
We optimise this cost function iteratively to train the logistic regression model.’
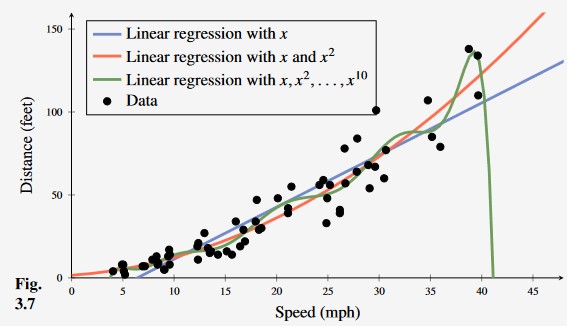
Figure 4 - Learning the car stopping distance with linear regression, second-order polynomial regression and 10th order polynomial regression. From this, we can see that the 10th degree polynomial is over fitting to outliers in the data making it less useful than even ordinary linear regression (blue).
On the training set, we can prove that the 10th order polynomial has the lowest error / is the most accurate on the training set.
- However, this is not necessarily a good thing - the 10th order polynomial is over fitting to the data.