COMP4702 Lecture 4
COMP4702 Lecture 4
Error Function
An error function compares the predicted value with the true value in which a smaller value is better.
- We have already seen a few error functions, such as Sum of Squared Error (SSE) and Misclassification Rate.
The error function can be the same as the loss function, but isn’t necessarily the same.
- Loss function used for training the model
- Error function used to evaluate a trained model
The ultimate goal in Machine Learning is to build models that predicts the results of new, unseen data well
- We assume that this data follows some unknown distribution that is stationary
- We also assume that data points are drawn randomly from this distribution
Our goal is to minimise the expected new error data which is the expectation of all possible test data points with respect to its distribution  
- This is expressed as  
Here we use the integral symbol to denote that we perform many repeated evaluations.
Recall here that is our model.
In addition to the introduction of we introduce the training error :  
Motivation for Estimating E_new
- By estimating E_new, we learn a few key things
- Firstly, it gives us an indication of how well our model will perform in the real world with new, unseen data
- If the model isn’t “good enough” we can try collecting mode data or changing the model
- On the other hand, we can use it to tell whether there is a fundamental limitation on the model (e.g., are the classes fundamentally overlapping and we can’t distinguish them)
- We can also use to compare different models and perform hyperparameter tuning.
- However, its use in tuning the performance of a model or selecting a model invalidates its use as an estimator of
- To resolve this, need a new hold-out partition to perform this validation on
- Finally, we can use to report the expected performance to the end user.
Why E_train isn’t E_new
- Consider the case where we use a form of look-up table as a supervised machine learning model.
- We can store the training data in a table, which would yield
- This doesn’t help us predict new data.
- In practice, we often see
Estimation via Validation Set
We can set aside some data points (randomly) and use these to estimate in what is called the hold-out (or validation) dataset.
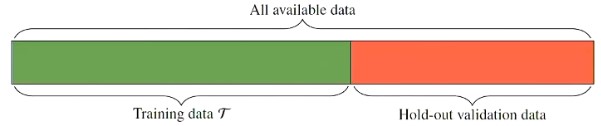
Figure 1 - Partition of dataset into training and hold-out set.
Using the hold-out data we can compute which is an unbiased estimate of
- As the size of the hold-out validation set increases, will be a better, lower-variance estimate of
- However, this leaves less data for training itself.
There is no “standard” percentage split but most people use 70/30 or 80/20
Estimation via k-Fold Cross Validation
Randomly partition data into equally sized subsets
Then we train the model times and compute for each run
- In the first run, the validation set is the first batch, and the training set is every other batch
- In the second run, the validation set is the second batch, and the training set is every other batch
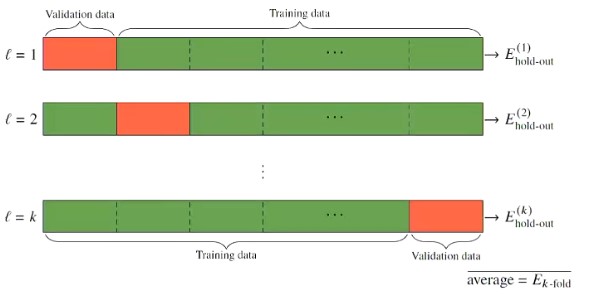
Figure 2 - k-fold cross-validation
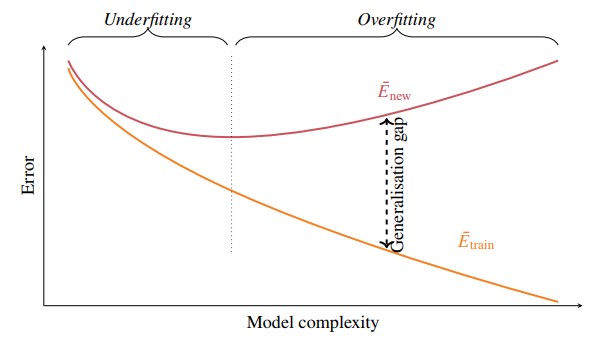
Training Error - Generalisation Gap Decomposition of E_New
- We often see statements about Machine Learning techniques in terms of “it doesn’t work” or “performance is better than human”
- These statements are usually too vague to have much meaning
- To really understand the performance of a Machine Learning model, it is useful to think about the generalisation gap
- The generalisation gap is a function of our estimates of and
<!-- cSpell: disable-next-line-->
<!-- cSpell: disable-next-line-->
Figure 3 - Behaviour of Enew and Etrain for many supervised machine learning techniques are a function of the model complexity.
- Generally, as the complexity of a model increases, the training error decreases.
- There is a “sweet spot” for in which it is decreased which is denoted by the dotted line in the figure above.
- It is quite tricky to find this line, but we will discuss ways of approaching it.
Training Error - Generalisation Gap Example
Consider a binary classification example with a two-dimensional input .
In this simulated example, we know that in which is a uniform distribution on the square and is defined as follows:
- All points above the dotted curve in Figure 4 are blue with probability 0.8, and points below the curve are red with probability 0.8
The optimal classifier, in terms of minimal would have the dotted line as its boundary and achieve
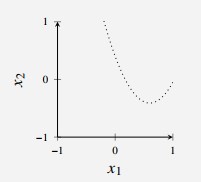
Figure 4 - Optimal decision boundary for classification problem.
We then generate this dataset with samples and learn three -NN classifiers with , and and plot the decision boundaries.
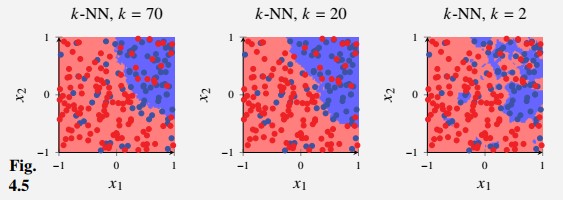
Figure 4 - Optimal decision boundary for classification problem.
In this figure, we see that the model adapts too much to the trends in the data
is rigid enough to not adapt to the noise, but might be a bit too inflexible to adapt to the true dotted line
We can compute by counting the fraction of misclassified points.
Since this is a simulated example, we also have access to which is
- This pattern resembles Figure 3 above, except that is actually smaller than for some values of (this doesn’t contradict the theory).
- The theory is in terms of and not for and
- That is, we need to repeat this experiment ~100 times and compute the average over those experiments.
| k-NN with k=70 | k-NN with k=20 | k-NN with k=2 | |
|---|---|---|---|
| 0.24 | 0.22 | 0.17 | |
| 0.25 | 0.23 | 0.30 | |
| 0.1 | 0.1 | 0.3 |
- This example is positive and increases with model complexity, whereas decreases with model complexity.
- For these values, has a minimum for which suggests that suffers from over fitting and suffers from under fitting
Minimising Training Gap
We also need to be aware that the size of the dataset affects the size of the generalisation gap
- Typically, more training data usually means a smaller training data, although probably increases.
The textbook also discusses minimising whilst having a small generalisation gap and end up with this advice
If consider that you could be under-fitting. To try improve results, increasing model flexibility.
If is close to zero but is not, you could be over fitting. To try to improve results, decrease model flexibility
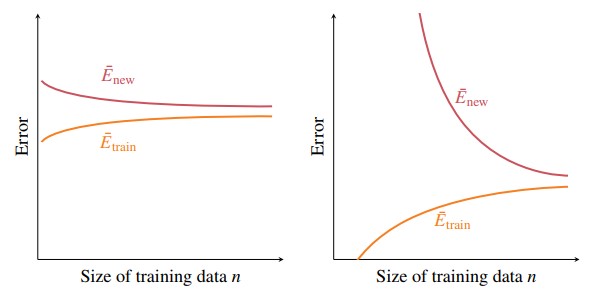
Figure 5 - Optimal decision boundary for classification problem.
Simple Model Generalisation gap isn’t so wide but slightly decreases as the size of the training gap decreases.
- More data to train model model that performs better on the test data.
Complex Model Same shapes but very different magnitudes
Intuition small dataset for small models, larger dataset has enough information to train a more complex model.
Example: Training Error vs Generalisation Gap
Consider a simulated problem so that we can compute .
Let data points be generated as , , and consider the following regression methods:
- Linear Regression with regularisation
- Linear Regression with a quadratic polynomial and regularisation
- Linear Regression with a third order polynomial and regularisation
- Regression tree
- Random forest with 10 Regression Trees
For each of these methods, try a few different hyper-parameters (regularisation parameter, tree depth) and compute and the generalisation gap.
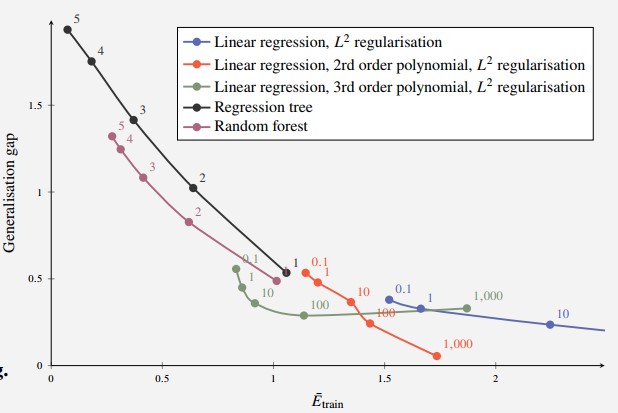
Figure 6 - Generalisation Gap of Various Models
Ideally, want both and the generalisation gap to both be small.
- In this example, motivated to choose something with small generalisation gap (e.g. 2nd order polynomial linear regression with parameter = 1,000)
However, note that we can’t plot this against model complexity, as this is very hard to measure in practice
Bias Variance Decomposition of E_new
- Now decompose into statistical bias and variance of the estimates of .
- Suppose we are trying to use a GPS to measure our location.
- denotes our true location
- is the measurement from the GPS which has some random distribution
- If we read from the GPS several times, we make observations of .
- The mean is given as
- Then, we define
- Bias:
- Variance:
- The variance describes the variability in the measurements (e.g., from noise in GPS measurements)
- The bias is some systematic error (e.g. GPS measurements are always offset to one side by a certain amount)
If we knew in reality all of this would be redundant. However, in practice we do not know and therefore we must predict it
If a model has hyper parameters, it is likely that the complexity of the model can be changed by varying the values of the hyper parameters
- However, the relationship is often not that simple.
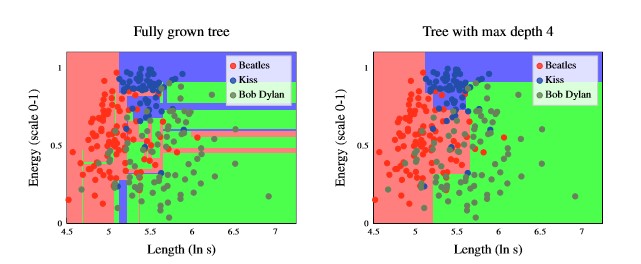
Figure 7 - Decision boundaries for Decision Trees with different depths
From the figure above, it is evident that decision trees partition the input space into axis-aligned rectangles.
Additionally, it is evident that the fully grown tree has a higher model complexity than the tree with max depth of 4.
The variance depends on the model, but also strongly dependent on the data (the number of data points).
If we let denote the size of the training set, it is a bit misleading as the size of the training data is comprised of both rows and columns.
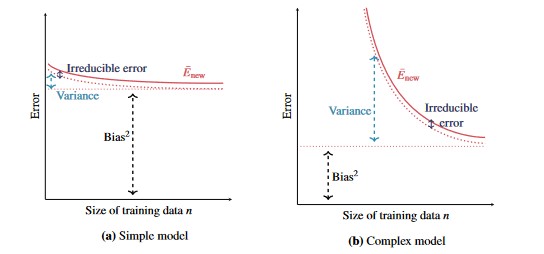
Figure 8 - Relationship between Bias, Variance and the size of the training set, n
As the amount of training data increases, the bias and variance decrease
- We can typically make the model more accurate by collecting more training data
- Complex models with small amounts of training data can be dangerous, as we have such a large variance component.
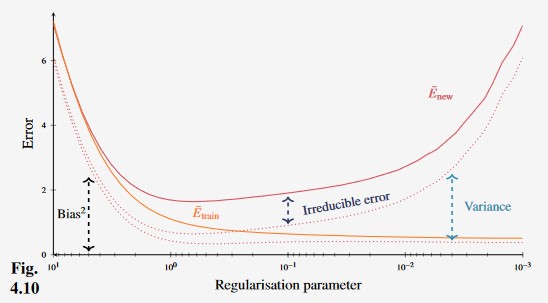
Figure 9 - Effect of regularisation on error in polynomial regression model.
Regularisation tends to make models simpler, and thus decrease variance and increase bias.
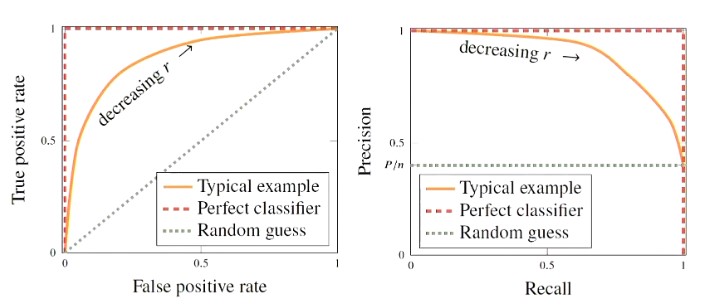
Figure 10 - ROC (left) and Precision-Recall curves are two types of curves used to evaluate the performance of different classifier cut-offs.
Example 4.5
UCI Machine Learning Repository for thyroid problems
7,200 data points with 21 medical inputs (features) and three diagnoses classes .
To convert this to a binary classification problem, transform this to the classes
The problem is imbalanced since only 7% of the data points are abnormal
- Therefore, the naive classifier which always predicts points are normal would obtain a ~7% misclassification rate
The problem is possibly asymmetric
- False Positives (falsely predicting the disease) is better than Falsely claiming that the patient is normal
- Can run diagnoses to more accurately determine that the patient is healthy
Using the dataset with a logistic regression classifier () gives the following result
| y=normal | y=abnormal | |
|---|---|---|
| 3177 | 237 | |
| 1 | 13 |
- Most validation data points are correctly predicted as normal
- Much of the abnormal data is also falsely predicted as normal (237)
- Lowering the decision threshold gives the following confusion matrix
| y=normal | y=abnormal | |
|---|---|---|
| 3067 | 165 | |
| 111 | 85 |
- This gives more true positives (85 v 13) but this happens at the cost of more false positives (111 vs 1)
- The accuracy is lower (0.919 vs 0.927) but false positives decreased (237 vs 165)