COMP4702 Lecture 8
COMP4702 Lecture 8
Bagging and Boosting
- Create a predictor by building a collection (or committee) of base models and combining them together
- Produces favourable properties that mean they often achieve excellent performance
Bagging
Borrowing the idea of bootstrapping from statistics
- Recall the bias-variance tradeoff - complex models potentially good for solving challenging problems and have low bias but have the potential to over fit to training data.
- Bagging (bootstrap aggregating) is a resampling technique that reduces the variance of a model without increasing the bias.
Bootstrapping
A more general idea from computational statistics to quantify uncertainties in statistical estimators
Given a dataset , create multiple datasets by sampling with replacement from .
Bootstrapped dataset will have multiple copies of some data points and miss some others but many statistical properties preserved.
Assume that the size of every bootstrapped dataset is equal to the size of the original dataset
The bootstrapping algorithm is as follows:
Data: Training dataset
Result: Bootstrapped data
- For do
- | Sample uniformly on the set of integers
- | Set and
- end
- Essentially, create a “bootstrapped” dataset by sampling with replacement from the original dataset
Bootstrapping Example
- Consider a dataset generated from some (unknown) function denoted by the dotted line in the figure below.
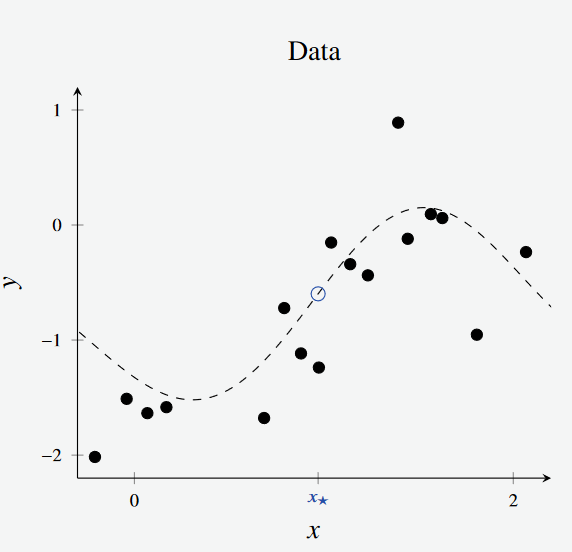
Figure 1 Visualisation of Data for Bootstrapping Example
- From this dataset, we sample with replacement and create nine bootstrapped regression trees
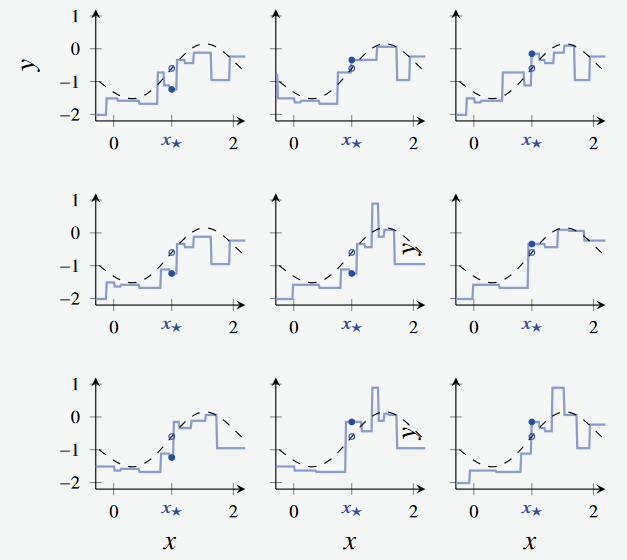
Figure 2 Created 9 bootstrapped trees from the above dataset
- We can see that the bootstrapped model fits the curve much better.
- Furthermore, in the regression tree learned from all the data, the prediction point is quite far away from its true value.
- The error is decreased when predicting using the bootstrapped regression trees.
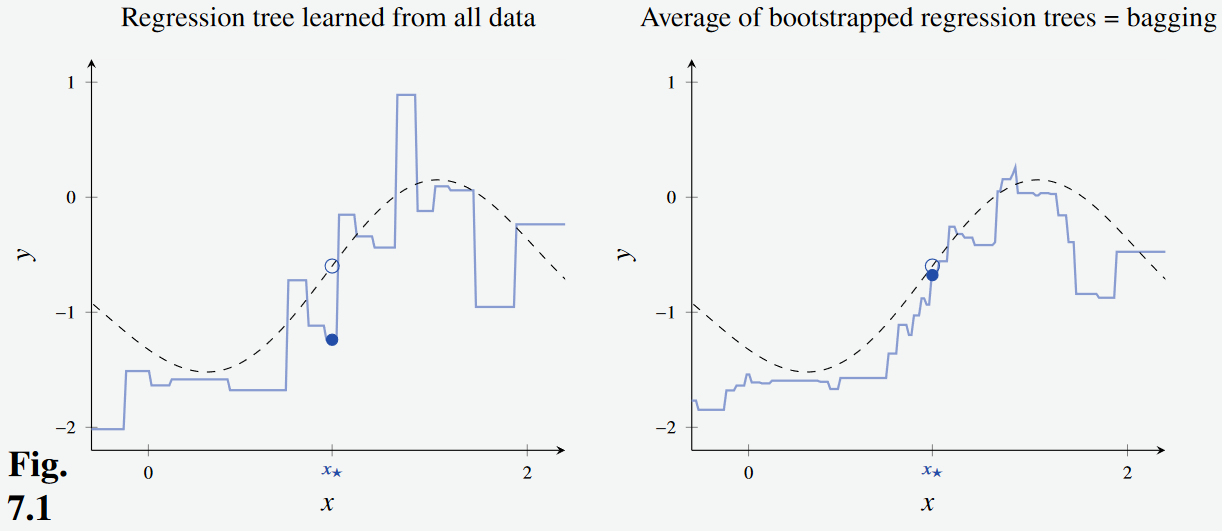
Figure 3 Observe that the resulting model (Right)
The technique of bagging creates bootstrapped datasets, and trains base models - one on each dataset.
For each prediction, the predictions of the base models are combined together to form an ensemble.
For regression or class probabilities, the output is the average of the base models’ prediction
For hard classification labels, take a majority vote of all base models.
How does Bagging reduce the variance of models?
- Consider a collection of random variables .
- Let the mean and variance of these variables be and
- Let average correlation between pairs be
- Mean and the variance of these variables (e.g., ensemble output) given by Equation 7.2a and 7.2b
We can see that:
- The mean is unaffected
- The variance decreases as increases
- The less correlated the variables are, the smaller the variance
Typically, the test error of the ensemble will decrease as the size of the ensemble increases
- We can see this in Example 7.3, where an increase in the size of the ensemble decreases the squared test error.
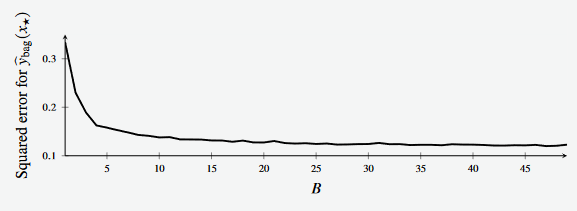
Figure 3 Observe that the resulting model (Right)
- In practice, this is slightly more difficult:
- We can’t directly control the correlation between base models, but we might try to encourage them to be somehow less correlated.
- The randomness from re-sampling will produce some differences between the base models.
- There could still be overfitting from the base models.
- Compared to using the original dataset, the bias of the base models might increase because of the bootstrapping
- We can’t directly control the correlation between base models, but we might try to encourage them to be somehow less correlated.
Out-of-Bag Error Estimation
- Bagging is another technique that spends more computational effort to get improvements in models (or estimation)
- Recall cross-validation as a way to get an estimate of .
- If we produce an ensemble via bagging, each base model will have seen (on average) about 63% of the datapoints.
- We can use the other of the points to build up an estimate of called the out-of-bag error .
- Each datapoint gets used as a test point for base models, and we average those estimates over all of the datapoints.
- The training computation was already done, so no extra effort is needed compared to cross-validation
- Interestingly, cross-validation is typically used more than
Random Forests
- Random forests are bagged decision trees, but with extra trick to try and make base model less correlated.
- At each step when considering splitting a node, we only consider a random subset of variables to split on.
- This might increase the variance of each base model, but if the decrease in is larger then we still get a benefit.
- In practice, people often find that this is the case.
- While is a hyperparameter (that needs to be tuned), rules of thumb are to use for classification and for regression.
Random Forest v Bagging Example
Example 7.4 from Lindholm et al.
- We have a synthetically generated dataset with points and a decision boundary (denoted by the dotted line)
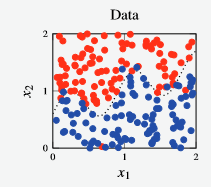
Figure 4 - Dataset for random forest vs bagging example.
Boosting
- Another ensemble technique, focused on combining simple (likely high bias) base models to reduce the bias of the ensemble.
- The training of models in bagging is parallel.
- Boosting constructs an ensemble sequentially - each model is encouraged to try and focus on mistakes made by previous model(s).
- Done by weighting datapoints during re-sampling and prediction.
- This means that it cannot be done in parallel
Example: Bagging vs Boosting
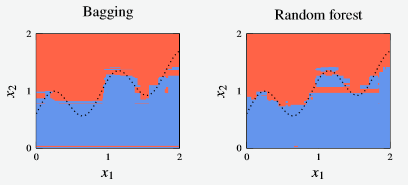
Figure 5 - Decision boundary for a random forest and bagged decision tree classifier
- The individual ensemble members are given as:
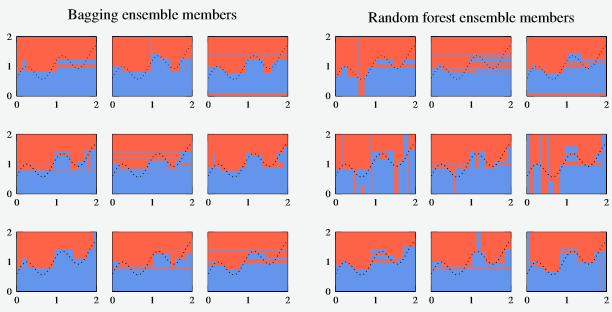
Figure 6 - Compilation of ensemble members for bagging and random forest
- And likewise, the error rate of the two models
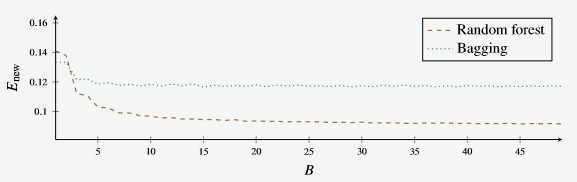
Figure 7 - E new for the random forest and bagging models.
- Surprisingly, the new error is lower for the random forest than the random forest.
- As both models’ error decrease.
- However, the Random Forest model’s error continues to decrease after whereas the bagging model seems to stagnate.
Example: Boosting Minimal Example
- Consider a classification problem with two-dimensional input space
- The training data consists of datapoints (5 samples from each class)
- For example, use a decision stump (decision tree with depth 1) as a simple, weak classifier.
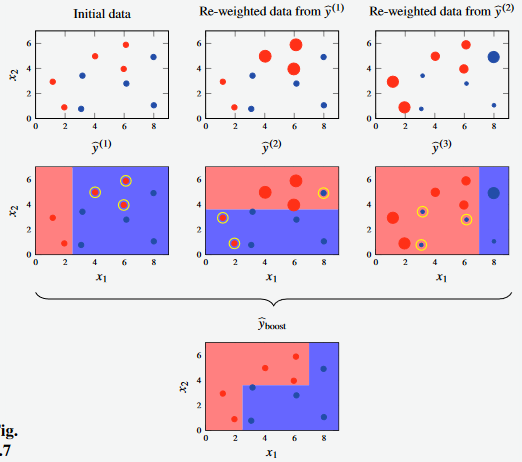
Figure 8 - E new for the random forest and bagging models.
- In the first iteration of the decision stump, the model misclassifies three of the red points.
- In the second iteration, two red points misclassified
- In the third iteration, three blue points misclassified.
- Use these learnings in creating the final boost model.
Adaboost
An old boosting algorithm that is still quite useful.
- Try to be a little more active about creating an ensemble that creates a better base model when compiled together
- Looking at the pseudocode we can see that
- Each datapoint is given a weight parameter , set initially to be equal
- Another parameter is calculated on each iteration using training error.
- This parameter is then used to modify the weight values to be used in the next iteration
- The weights are also re-normalised
- The
The AdaBoost training algorithm is given as:
Data: Training data
Result: weak classifiers
- Assign weights to all datapoints
- for do
- | Train a weak classifier on the weighted training data denoted
- | Compute
- | Compute
- | Compute
- | Set (normalisation of weights)
From lines 5 and 6 of the AdaBoost algorithm, we cna draw the following conclusions:
- Adaboost trains the ensemble by minimising an exponential loss function of the boosted classifier at each iteration - the loss function is shown in Equation 7.5 below.
- The fact that this is an exponential function makes the math work out nicely.
- Part of the derivation shows that we can do the optimisation using the weighted misclassification loss at each iteration (Line 4).
Design Choices for Adaboost
- The book gives a few bits of advice for choosing the base classifier and the number of iterations for AdaBoost:
- A good idea to use a simple model that’s fast to train (e.g. decision stumps or a small decision tree) because boosting reduces bias efficiently. Note that boosting is still an Ensemble method that uses sampling, so it still possibly reduces variance.
- Overfitting is possible if gets too large - could use early stopping.
Gradient Boosting
A newer technique compared to AdaBoost
- AdaBoost uses an exponential loss function that can be sensitive to outliers, noise in the data.
- One way to address this is to use a different loss function (but requires re-thinking of the model)
- If we take a general view of a model (aka function approximator) as a weighted sum combining together some other functions, we have an additive model (statistics term)
In boosting:
- Each base model/basis function is itself a machine learning model, which has bene learned from data.
- The overall model is learnt sequentially, over (B) iterations
Training via Gradient Boosting
- Training an additive model is an optimisation problem over to minimise Equation 7.15 shown below.
- This is done greedily at each step for the exponential loss function in AdaBoost (Equation 7.5)
- Alternatively, any method that will improve will be fine (Equation 7.16, 7.17)
- The base model at step is related to the base model at step , in which acts like a step size parameter
- Then, if our goal is to reduce the objective function, we require that the new value of the objective function to be smaller than that of the previous ensemble to be.
- The base model at step is related to the base model at step , in which acts like a step size parameter
- A general approach for this is summarised as:
The gradient of, with respect to the current base models is taken as the gradient of the los function for the base models on the data as shown in Equation 7.18
(That is, this method doesn’t necessarily have to be greedy)
If we can determine what the gradient of is, we can “go downhill” on that gradient to minimise its value.
Practical implementations of gradient boosting (using decision trees as base models) are often found to give State of the Art performance, with implementations such as XGBoost and LightGBM